Install notebook dependencies
You can install Python dependencies for serverless notebooks using the Environment side panel. This panel provides a single place to edit, view, and export a notebook’s library requirements. These dependencies can be added using a base environment or individually.
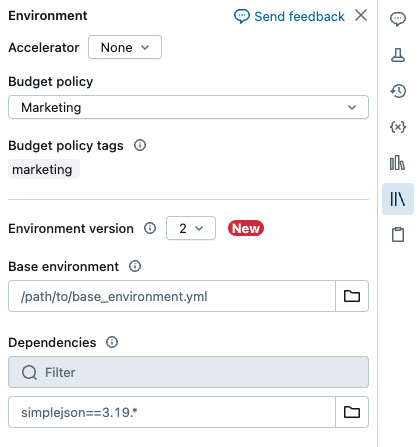
For non-notebook tasks, see Configure environments and dependencies for non-notebook tasks.
Important
Do not install PySpark or any library that installs PySpark as a dependency on your serverless notebooks. Doing so will stop your session and result in an error. If this occurs, remove the library and reset your environment.
Configure a base environment
A base environment is a YAML file stored as a workspace file or on a Unity Catalog volume that specifies additional environment dependencies. Base environments can be shared among notebooks. To configure a base environment:
Create a YAML file that defines settings for a Python virtual environment. The following example YAML, which is based on the MLflow projects environment specification, defines a base environment with a few library dependencies:
client: "1" dependencies: - --index-url https://pypi.org/simple - -r "/Workspace/Shared/requirements.txt" - my-library==6.1 - "/Workspace/Shared/Path/To/simplejson-3.19.3-py3-none-any.whl" - git+https://github.com/databricks/databricks-cli
Upload the YAML file as a workspace file or to a Unity Catalog volume. See Import a file or Upload files to a Unity Catalog volume.
To the right of the notebook, click the
 button to expand the Environment side panel. This button only appears when a notebook is connected to serverless compute.
button to expand the Environment side panel. This button only appears when a notebook is connected to serverless compute.In the Base Environment field, enter the path of the uploaded YAML file or navigate to it and select it.
Click Apply. This installs the dependencies in the notebook virtual environment and restarts the Python process.
Users can override the dependencies specified in the base environment by installing dependencies individually.
Configure the notebook environment
You can also install dependencies on a notebook connected to serverless compute using the Environment side panel:
To the right of the notebook, click on the
button to expand the Environment side panel. This button only appears when a notebook is connected to serverless compute.Select the environment version from the Environment version drop-down. See Serverless environment versions. Databricks recommends picking the latest version to get the most up-to-date notebook features.
In the Dependencies section, click Add Dependency and enter the path of the library dependency in the field. You can specify a dependency in any format that is valid in a requirements.txt file.
Click Apply. This installs the dependencies in the notebook virtual environment and restarts the Python process.
Note
A job using serverless compute will install the environment specification of the notebook before executing the notebook code. This means that there is no need to add dependencies when scheduling notebooks as jobs. See Configure environments and dependencies.
View installed dependencies and pip logs
To view installed dependencies, click Installed in the Environments panel for a notebook. pip installation logs for the notebook environment are also available by clicking pip logs at the bottom of the panel.
Reset the environment
If your notebook is connected to serverless compute, Databricks automatically caches the content of the notebook’s virtual environment. This means you generally do not need to reinstall the Python dependencies specified in the Environment side panel when you open an existing notebook, even if it has been disconnected due to inactivity.
Python virtual environment caching also applies to jobs. When a job is run, any task of the job that shares the same set of dependencies as a completed task in that run is faster, as required dependencies are already available.
Note
If you change the implementation of a custom Python package used in a job on serverless, you must also update its version number so that jobs can pick up the latest implementation.
To clear the environment cache and perform a fresh install of the dependencies specified in the Environment side panel of a notebook attached to serverless compute, click the arrow next to Apply and then click Reset environment.
Note
Reset the virtual environment if you install packages that break or change the core notebook or Apache Spark environment. Detaching the notebook from serverless compute and reattaching it does not necessarily clear the entire environment cache. Resetting the environment reinstalls all dependencies specified in the Environment side panel, so ensure that offending packages are removed before resetting.
Configure environments and dependencies for non-notebook tasks
For other supported task types, such as Python script, Python wheel, or dbt tasks, a default environment includes installed Python libraries. To see the list of installed libraries, see the Installed Python libraries section of the client version you are using. See Serverless environment versions. If a task requires a Python library that is not installed, you can install the library from workspace files, Unity Catalog volumes, or public package repositories. To add a library when you create or edit a task:
In the Environment and Libraries dropdown menu, click
 next to the Default environment or click + Add new environment.
next to the Default environment or click + Add new environment.
Select the environment version from the Environment version drop-down. See Serverless environment versions. Databricks recommends picking the latest version to get the most up-to-date features.
In the Configure environment dialog, click + Add library.
Select the type of dependency from the dropdown menu under Libraries.
In the File Path text box, enter the path to the library.
For a Python Wheel in a workspace file, the path should be absolute and start with
/Workspace/.For a Python Wheel in a Unity Catalog volume, the path should be
/Volumes/<catalog>/<schema>/<volume>/<path>.whl.For a
requirements.txtfile, select PyPi and enter-r /path/to/requirements.txt.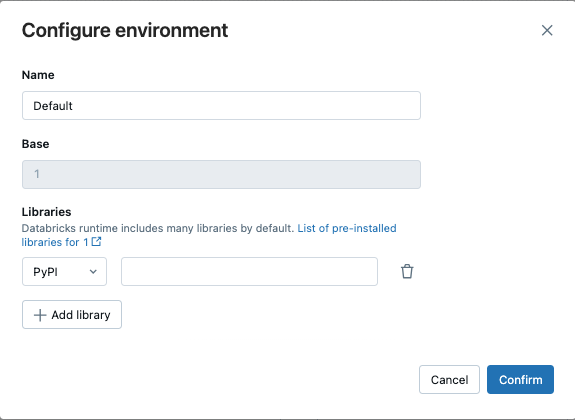
Click Confirm or + Add library to add another library.
If you’re adding a task, click Create task. If you’re editing a task, click Save task.
Configure default Python package repositories
Administrators can configure private or authenticated package repositories within workspaces as the default pip configuration for both serverless notebooks and serverless jobs. This allows users to install packages from internal Python repositories without explicitly defining index-url or extra-index-url. However, if these values are specified in code or in a notebook, they take precedence over the workspace defaults.
This configuration leverages Databricks secrets to securely store and manage repository URLs and credentials. Administrators can configure the setup using the workspace admin settings page or using a predefined secret scope and the Databricks CLI secrets commands or the REST API.
Setup using the workspace admin settings page
Workspace admins can add or remove the default Python package repositories using the workspace admin settings page.
As a workspace administrator, log in to the Databricks workspace.
Click your username in the top bar of the Databricks workspace and select Settings.
Click on the Compute tab.
Next to Default Package Repositories, click Manage.
(Optional) Add or remove an index URL, extra index URLs or a custom SSL certificate.
Click Save to save the changes.
Note
Modifications or deletions to secrets are applied after reattaching serverless compute to notebooks or rerunning the serverless jobs.
Setup using the secrets CLI or REST API
To configure default Python package repositories using the CLI or REST API, create a predefined secret scope and configure access permissions, then add the package repository secrets.
Predefined secret scope name
Workspace administrators can set default pip index URLs or extra index URLs along with authentication tokens and secrets in a designated secret scope under predefined keys:
Secret scope name:
databricks-package-managementSecret key for index-url:
pip-index-urlSecret key for extra-index-urls:
pip-extra-index-urlsSecret key for SSL certification content:
pip-cert
Create the secret scope
A secret scope can be created using the Databricks CLI secrets commands or the REST API. After creating the secret scope, configure access control lists to grant all workspace users read access. This ensures that the repository remains secure and cannot be altered by individual users. The secret scope must use the predefined secret scope name databricks-package-management.
databricks secrets create-scope databricks-package-management
databricks secrets put-acl databricks-package-management admins MANAGE
databricks secrets put-acl databricks-package-management users READ
Add Python package repository secrets
Add the Python package repository details using the predefined secret key names, with all three fields being optional.
# Add index URL.
databricks secrets put-secret --json '{"scope": "databricks-package-management", "key": "pip-index-url", "string_value":"<index-url-value>"}'
# Add extra index URLs. If you have multiple extra index URLs, separate them using white space.
databricks secrets put-secret --json '{"scope": "databricks-package-management", "key": "pip-extra-index-urls", "string_value":"<extra-index-url-1 extra-index-url-2>"}'
# Add cert content. If you want to pip configure a custom SSL certificate, put the cert file content here.
databricks secrets put-secret --json '{"scope": "databricks-package-management", "key": "pip-cert", "string_value":"<cert-content>"}'
Modify or delete private PyPI repository secrets
To modify PyPI repository secrets use the put-secret command. To delete PyPI repository secrets, use delete-secret as shown below:
# delete secret
databricks secrets delete-secret databricks-package-management pip-index-url
databricks secrets delete-secret databricks-package-management pip-extra-index-urls
databricks secrets delete-secret databricks-package-management pip-cert
# delete scope
databricks secrets delete-scope databricks-package-management