How materialized views work
Preview
This feature is in Public Preview.
Like regular views, materialized views are also the results of a query and you can access them like you would a table. Whereas regular views are recomputed on every query, materialized views are automatically kept up to date by Databricks to avoid redundant recomputation. Because a materialized view is precomputed, queries against it can run much faster than against regular views.
Materialized views are a good choice for many transformations:
You reason over datasets instead of rows. In fact, you simply write a query.
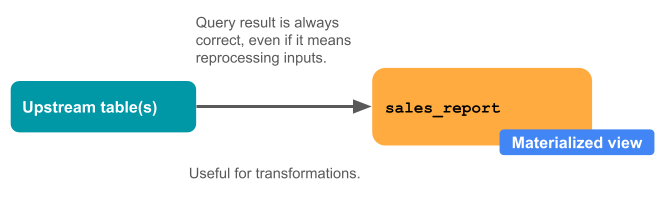
They are always correct. All data is processed, even if it arrives late or out of order.
They are often incremental. Databricks will try to choose the appropriate strategy that minimizes the cost of updating a materialized view.
The following diagram illustrates how materialized views work.
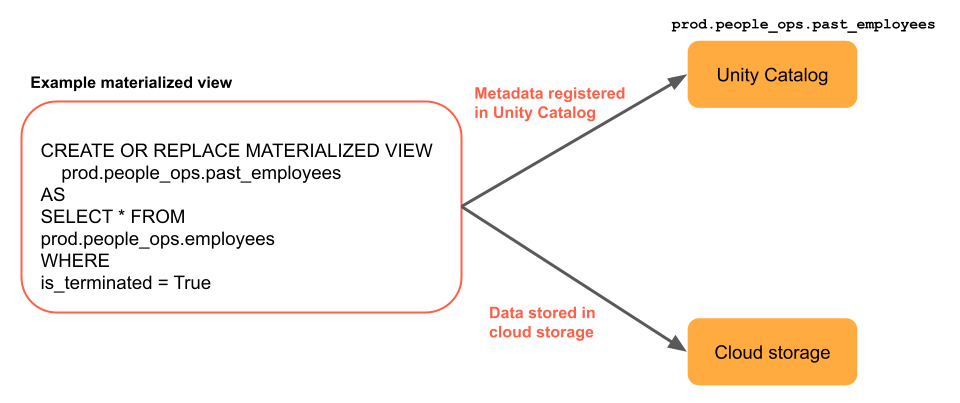
Materialized views are defined and updated by a single Delta Live Tables pipeline. When you create a Delta Live Tables pipeline, you can explicitly define materialized views in the source code of the pipeline. These tables are then defined by this pipeline, and can’t be changed or updated by any other pipeline. When you create a materialized view in Databricks SQL, Databricks creates a Delta Live Tables pipeline which is used to update this view.
Databricks uses Unity Catalog to store metadata about the view, including the query and additional system views that are used for incremental updates. Furthermore, data is materialized in cloud storage.
The following example joins two tables together and keeps the result up to date using a materialized view. If you use one or more spark.readStream invocations in the method, it changes the view into a streaming table instead of a materialized view.
import dlt
@dlt.table
def regional_sales():
partners_df = spark.read.table("partners")
sales_df = spark.read.table("sales")
return (
partners_df.join(sales_df, on="partner_id", how="inner")
)
Automatic incremental updates
Materialized views are automatically kept up to date, often incrementally. Databricks automatically keeps materialized views up to date as inputs or the query changes. A materialized view always shows the correct result, even if it requires fully recomputing the query result from scratch. Often, Databricks makes incremental updates to a materialized view, which can be far less costly than a full recomputation.
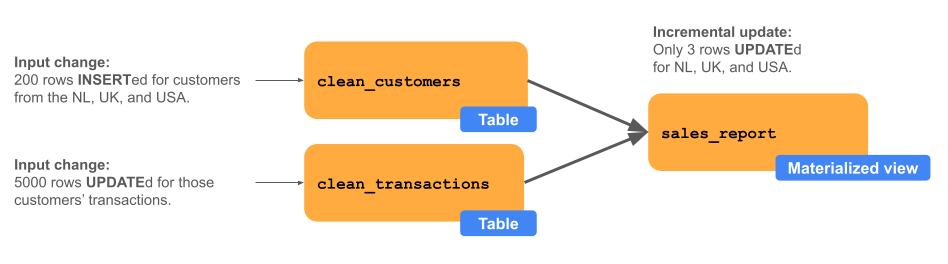
The diagram below shows a materialized view called sales_report, which is the result of joining two upstream tables called clean_customers and clean_transactions. An upstream process inserts 200 rows into clean_customers in three countries (USA, Netherlands, UK) and updates 5,000 rows in clean_transactions corresponding to these new customers. The materialized view called sales_report is incrementally updated for only the countries that have new customers or corresponding transactions. In this example, we see three rows updated instead of the entire sales report.
Materialized views limitations
Materialized views have the following limitations:
Since they are always correct, some changes to inputs will require a full recomputation of a materialized view, which can be expensive.
They are not designed for low-latency use cases. The latency of updating a materialized view is in the seconds or minutes, not milliseconds.
Not all computations can be incrementally computed.