Como funciona a visualização materializada
Prévia
Esse recurso está em Prévia Pública.
Assim como a visualização normal, a visualização materializada também é o resultado de uma consulta e o senhor pode acessá-la como faria com uma tabela. Enquanto as visualizações regulares são recalculadas a cada consulta, as visualizações materializadas são mantidas automaticamente atualizadas pelo site Databricks para evitar recálculos redundantes. Como um view materializado é pré-calculado, as consultas contra ele podem ser executadas muito mais rapidamente do que contra uma visualização regular.
As visualizações materializadas são uma boa opção para muitas transformações:
O senhor raciocina sobre o conjunto de dados em vez de linhas. Na verdade, você simplesmente escreve uma consulta.
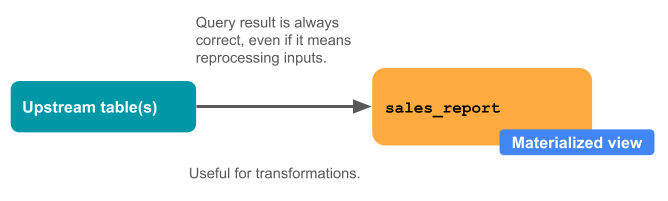
Eles estão sempre corretos. Todos os dados são processados, mesmo que cheguem atrasados ou fora de ordem.
Eles geralmente são incrementais. Databricks tentará escolher a estratégia adequada que minimiza o custo de atualização de um materializado view.
O diagrama a seguir ilustra o funcionamento da visualização materializada.
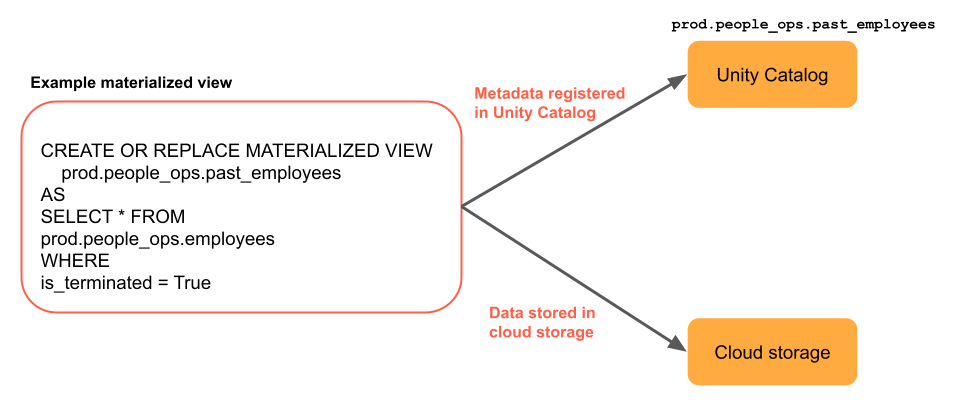
A visualização materializada é definida e atualizada por um único Delta Live Tables pipeline. Ao criar um Delta Live Tables pipeline, o senhor pode definir explicitamente a visualização materializada no código-fonte do pipeline. Essas tabelas são então definidas por esse pipeline e não podem ser alteradas ou atualizadas por nenhum outro pipeline. Quando o senhor cria um view materializado em Databricks SQL, Databricks cria um Delta Live Tables pipeline que é usado para atualizar esse view.
Databricks usa o site Unity Catalog para armazenar metadados sobre o site view, incluindo a consulta e a visualização adicional do sistema que são usadas para atualizações incrementais. Além disso, os dados são materializados no armazenamento cloud.
O exemplo a seguir une duas tabelas e mantém o resultado atualizado usando um view materializado. Se o senhor usar uma ou mais invocações spark.readStream no método, ele transformará a view em uma tabela de transmissão em vez de uma view materializada.
import dlt
@dlt.table
def regional_sales():
partners_df = spark.read.table("partners")
sales_df = spark.read.table("sales")
return (
partners_df.join(sales_df, on="partner_id", how="inner")
)
Atualizações incrementais automáticas
As visualizações materializadas são atualizadas automaticamente, muitas vezes de forma incremental. Databricks mantém automaticamente a visualização materializada atualizada à medida que as entradas ou a consulta são alteradas. Um view materializado sempre mostra o resultado correto, mesmo que seja necessário recomputar totalmente o resultado da consulta do zero. Frequentemente, o site Databricks faz atualizações incrementais em um view materializado, o que pode ser muito menos dispendioso do que uma recomputação completa.
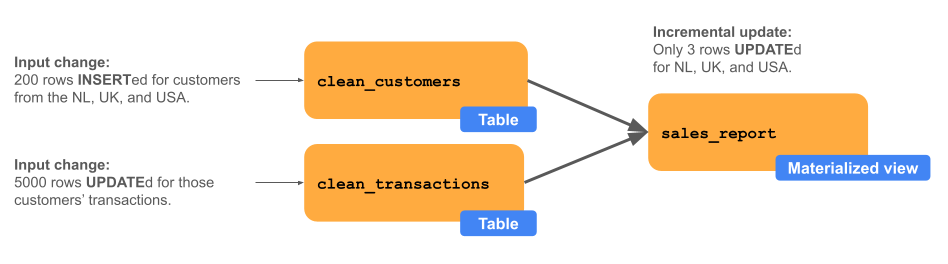
O diagrama abaixo mostra um view materializado chamado sales_report, que é o resultado da união de duas tabelas upstream chamadas clean_customers e clean_transactions. Um processo upstream insere 200 linhas em clean_customers em três países (EUA, Holanda, Reino Unido) e atualiza 5.000 linhas em clean_transactions correspondentes a esses novos clientes. O site materializado view chamado sales_report é atualizado de forma incremental somente para os países que têm novos clientes ou transações correspondentes. Neste exemplo, vemos três linhas atualizadas em vez de todo o relatório de ventas.
Limitações da visualização materializada
A visualização materializada tem as seguintes limitações:
Como eles estão sempre corretos, algumas alterações nas entradas exigirão uma recomputação completa de um view materializado, o que pode ser caro.
Eles não foram projetados para casos de uso de baixa latência. A latência da atualização de um site materializado view é em segundos ou minutos, não em milissegundos.
Nem todos os cálculos podem ser computados de forma incremental.