マテリアライズド ビューの仕組み
プレビュー
この機能はパブリックプレビュー段階です。
通常のビューと同様に、マテリアライズドビューもクエリの結果であり、テーブルと同様にアクセスできます。 通常のビューはクエリごとに再計算されますが、マテリアライズドビューは Databricks によって自動的に最新の状態に保たれ、冗長な再計算を回避します。 実体化ビュー (Materialized View) は事前に計算されているため、それに対するクエリは通常のビューよりもはるかに高速に実行できます。
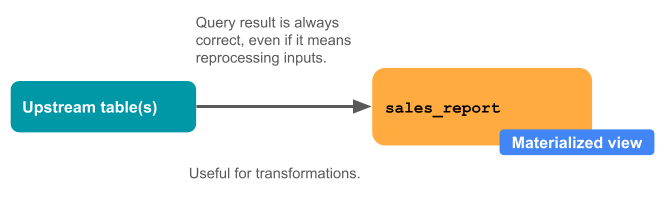
マテリアライズドビューは、多くの変換に適しています。
行ではなくデータセットを推論します。 実際には、クエリを記述するだけです。
彼らは常に正しいです。 すべてのデータは、遅れて到着したり、順不同で到着したりした場合でも処理されます。
多くの場合、増分です。 Databricks は、マテリアライズドビューの更新コストを最小限に抑える適切な戦略を選択しようとします。
次の図は、マテリアライズドビューの仕組みを示しています。
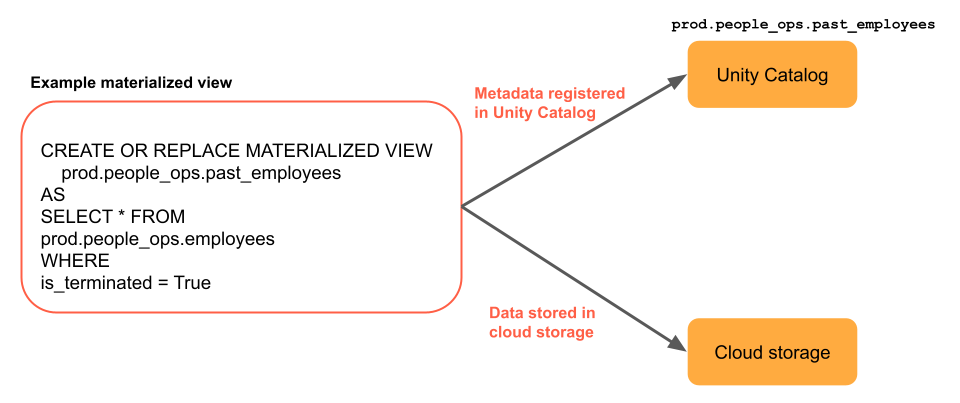
マテリアライズドビューは、1 つの Delta Live Tables パイプラインによって定義および更新されます。 Delta Live Tables パイプラインを作成するときは、パイプラインのソース コードでマテリアライズドビューを明示的に定義できます。 これらのテーブルは、このパイプラインによって定義され、他のパイプラインで変更または更新することはできません。 Databricks SQL でマテリアライズドビューを作成すると、Databricks は、このビューを更新するために使用される Delta Live Tables パイプラインを作成します。
Databricks は Unity Catalog を使用して、クエリや増分更新に使用される追加のシステム ビューなど、ビューに関するメタデータを格納します。 さらに、データはクラウドストレージにマテリアライズされます。
次の例では、2 つのテーブルを結合し、マテリアライズドビューを使用して結果を最新の状態に保ちます。 メソッドで 1 つ以上の spark.readStream 呼び出しを使用すると、ビューが実体化ビュー (Materialized View) ではなくストリーミング テーブルに変更されます。
import dlt
@dlt.table
def regional_sales():
partners_df = spark.read.table("partners")
sales_df = spark.read.table("sales")
return (
partners_df.join(sales_df, on="partner_id", how="inner")
)
自動更新
マテリアライズド・ビューは、自動的に最新の状態に保たれ、多くの場合、段階的に更新されます。 Databricks は、入力やクエリの変更に応じて、マテリアライズド ビューを自動的に最新の状態に保ちます。 マテリアライズドビューは、クエリ結果を最初から完全に再計算する必要がある場合でも、常に正しい結果を表示します。 多くの場合、Databricks はマテリアライズド ビューに対して増分更新を行いますが、これは完全な再計算よりもはるかに低コストです。
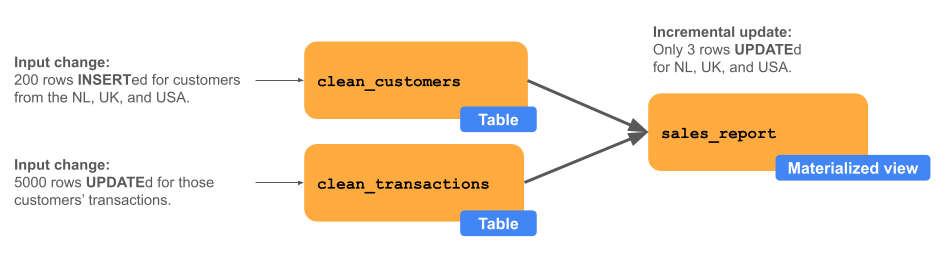
次の図は、 clean_customers と clean_transactionsという 2 つのアップストリームテーブルを結合した結果である sales_reportというマテリアライズドビューを示しています。アップストリーム プロセスでは、3 か国 (米国、オランダ、英国) の clean_customers に 200 行が挿入され、これらの新しい顧客に対応する clean_transactions 5,000 行が更新されます。 sales_report と呼ばれるマテリアライズドビューは、新規顧客または対応するトランザクションを持つ国に対してのみ増分更新されます。この例では、売上レポート全体ではなく、3 つの行が更新されています。