Retrieval Augmented Generation (RAG) on Databricks
This article provides an overview of retrieval augmented generation (RAG) and describes RAG application support in Databricks.
What is Retrieval Augmented Generation?
RAG is a generative AI design pattern that involves combining a large language model (LLM) with external knowledge retrieval. RAG is required to connect real-time data to your generative AI applications. Doing so improves the accuracy and quality of the application, by providing your data as context to the LLM at inference time.
The Databricks platform provides an integrated set of tools that supports the following RAG scenarios.
Type of RAG |
Description |
Example use case |
|---|---|---|
Unstructured data |
Use of documents - PDFs, wikis, website contents, Google or Microsoft Office documents, and so on. |
Chatbot over product documentation |
Structured data |
Use of tabular data - Delta Tables, data from existing application APIs. |
Chatbot to check order status |
Tools & function calling |
Call third party or internal APIs to perform specific tasks or update statuses. For example, performing calculations or triggering a business workflow. |
Chatbot to place an order |
Agents |
Dynamically decide how to respond to a user’s query by using an LLM to choose a sequence of actions. |
Chatbot that replaces a customer service agent |
RAG application architecture
The following illustrates the components that make up a RAG application.
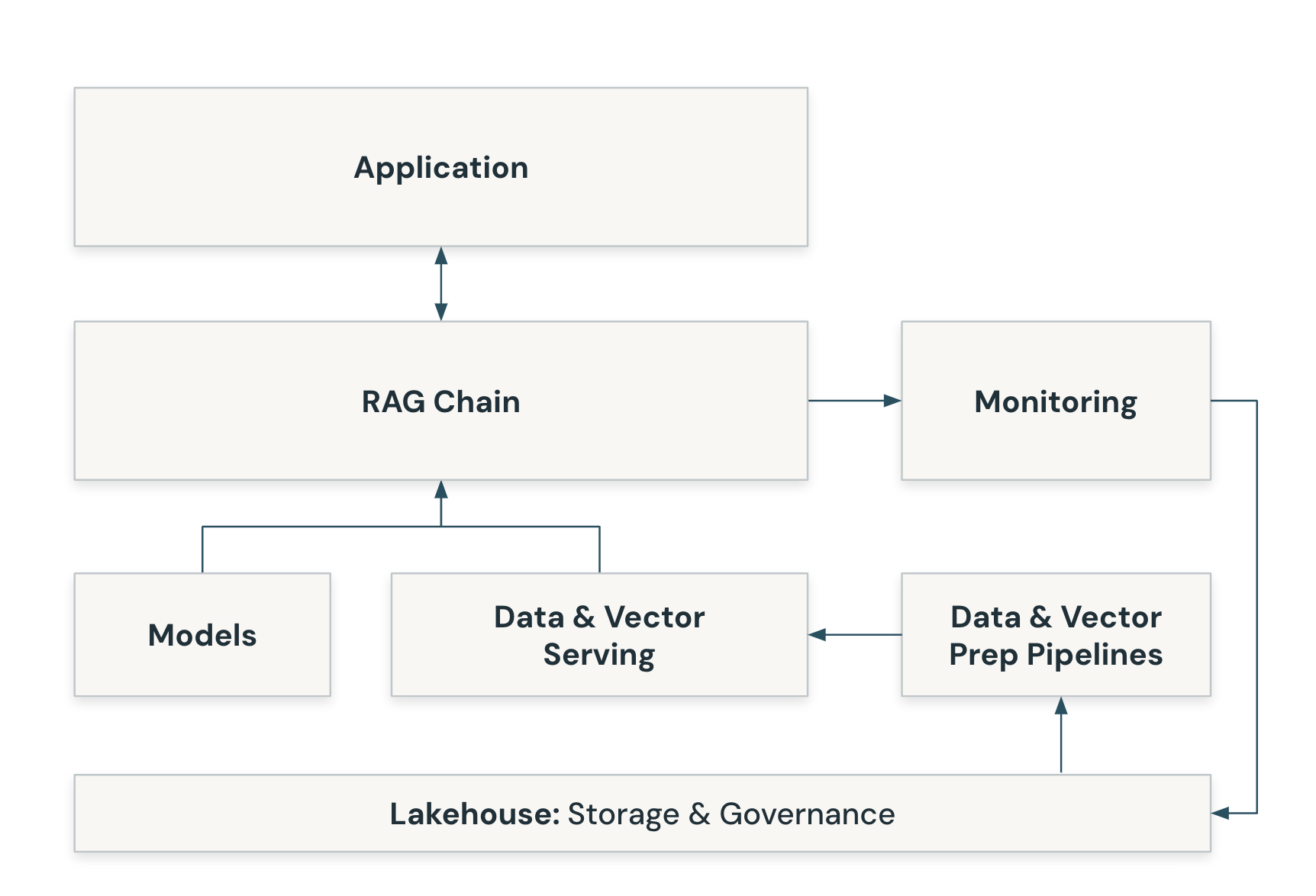
RAG applications require a pipeline and a chain component to perform the following:
Indexing A pipeline that ingests data from a source and indexes it. This data can be structured or unstructured.
Retrieval and generation This is the actual RAG chain. It takes the user query and retrieves similar data from the index, then passes the data, along with the query, to the LLM model.
The below diagram demonstrates these core components:
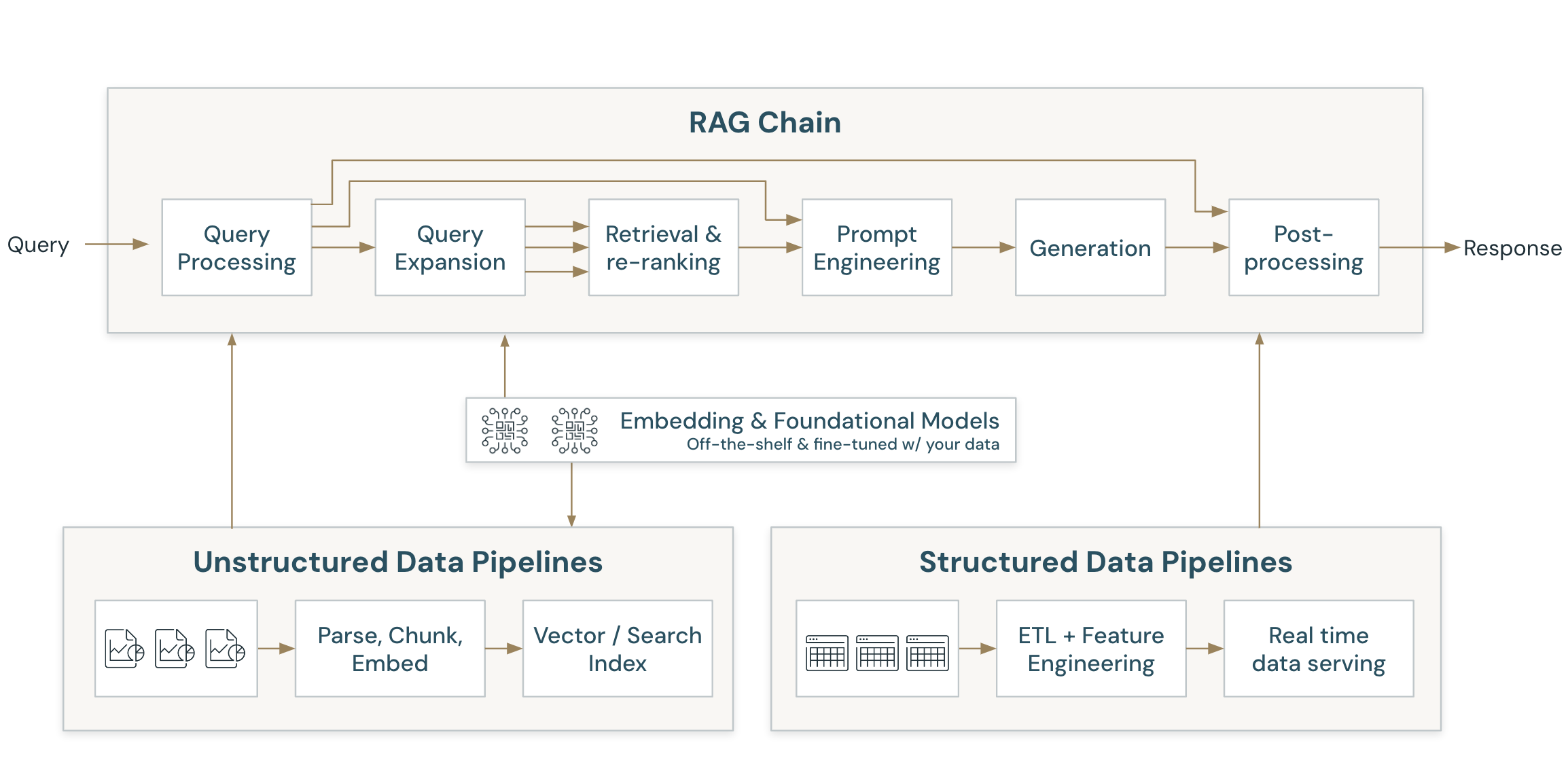
Unstructured data RAG example
The following sections describe the details of the indexing pipeline and RAG chain in the context of an unstructured data RAG example.
Indexing pipeline in a RAG app
The following steps describe the indexing pipeline:
Ingest data from your proprietary data source.
Split the data into chunks that can fit into the context window of the foundational LLM. This step also includes parsing the data and extracting metadata. This data is commonly referred to as a knowledge base that the foundational LLM is trained on.
Use an embedding model to create vector embeddings for the data chunks.
Store the embeddings and metadata in a vector database to make them accessible for querying by the RAG chain.
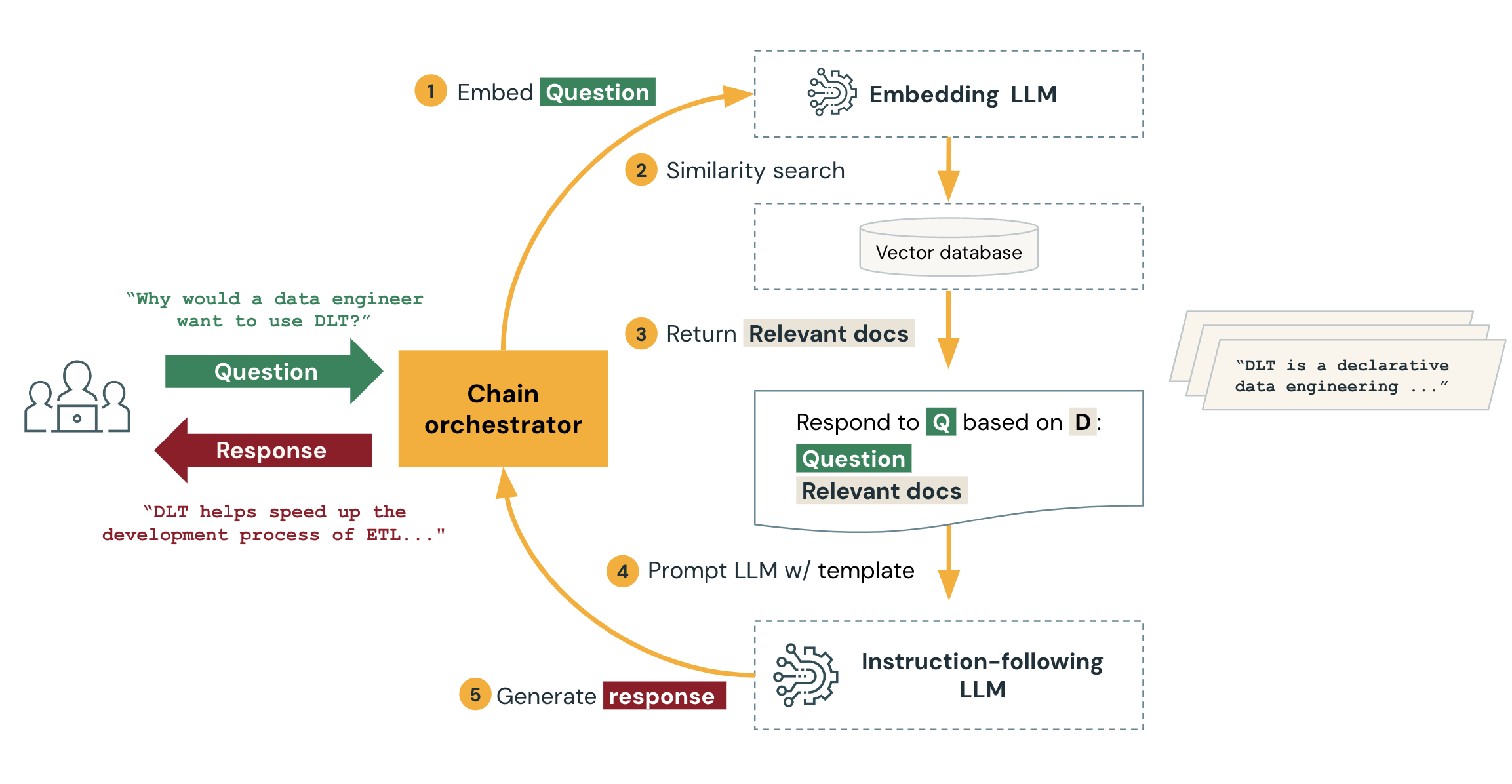
Retrieval using the RAG chain
After the index is prepared, the RAG chain of the application can be served to respond to questions. The following steps and diagram describe how the RAG application responds to an incoming request.
Embed the request using the same embedding model that was used to embed the data in the knowledge base.
Query the vector database to do a similarity search between the embedded request and the embedded data chunks in the vector database.
Retrieve the data chunks that are most relevant to the request.
Feed the relevant data chunks and the request to a customized LLM. The data chunks provide context that helps the LLM generate an appropriate response. Often, the LLM has a template for how to format the response.
Generate a response.
The following diagram illustrates this process: