Recuperação de desastres
Um padrão claro de recuperação de desastres é essencial para uma plataforma nativa de análise de dados em nuvem, como a Databricks. É fundamental que suas equipes de dados possam usar a Databricks plataforma mesmo no caso raro de uma interrupção regional do provedor de cloudserviços, seja ela causada por um desastre regional, como um furacão ou terremoto, ou por outra fonte.
Databricks é geralmente uma parte central de um ecossistema geral de dados que inclui muitos serviços, inclusive o serviço de ingestão de dados upstream (lotes/transmissão), armazenamento nativo em nuvem, como Google Cloud Storage, ferramentas e serviços downstream, como aplicativos Business Intelligence, e ferramentas de orquestração. Alguns de seus casos de uso podem ser particularmente sensíveis a uma interrupção regional em todo o serviço.
Este artigo descreve conceitos e práticas recomendadas para soluções bem-sucedidas de recuperação de desastres inter-regionais para a plataforma Databricks.
Visão geral da recuperação de desastres
A recuperação de desastres envolve um conjunto de políticas, ferramentas e procedimentos que permitem a recuperação ou a continuidade da infraestrutura e dos sistemas tecnológicos vitais após um desastre natural ou induzido pelo homem. Um grande serviço como o Google cloud cloud atende a muitos clientes e tem proteções integradas contra uma única falha. Por exemplo, uma região é um grupo de edifícios conectados a diferentes fontes de energia para garantir que uma única perda de energia não desligue uma região. No entanto, podem ocorrer falhas na região cloud, e o grau de interrupção e seu impacto na organização podem variar.
Antes de implementar um plano de recuperação de desastres, é importante entender a diferença entre recuperação de desastres (DR) e alta disponibilidade (HA).
A alta disponibilidade é uma característica de resiliência de um sistema. A alta disponibilidade garante um nível mínimo de desempenho operacional que geralmente é definido em termos de tempo de atividade consistente ou porcentagem de tempo de atividade. A alta disponibilidade é implementada no local (na mesma região que o sistema primário), projetando-a como um recurso do sistema primário. Por exemplo, o serviço cloud, como o Google cloud, tem um serviço de alta disponibilidade, como o Google Cloud Storage. A alta disponibilidade não exige uma preparação explícita significativa por parte do cliente da Databricks.
Por outro lado, um plano de recuperação de desastres requer decisões e soluções que funcionem para sua organização específica, a fim de lidar com uma interrupção regional maior dos sistemas essenciais. Este artigo discute a terminologia comum de recuperação de desastres, soluções comuns e algumas práticas recomendadas para planos de recuperação de desastres com Databricks.
Terminologia
Terminologia da região
Este artigo usa as seguintes definições para regiões:
Região primária: A região geográfica na qual os usuários executam cargas de trabalho diárias típicas de análise de dados interativa e automatizada.
Região secundária: A região geográfica para a qual as equipes do IT transferem temporariamente as cargas de trabalho de análise de dados durante uma interrupção na região primária.
Armazenamento com redundância geográfica: O Google Cloud tem armazenamento com redundância geográfica entre regiões para buckets GCS persistentes usando um processo de replicação de armazenamento assíncrono.
Importante
Para os processos de recuperação de desastres, Databricks recomenda que o senhor não conte com o armazenamento geo-redundante para duplicação de dados entre regiões, como os dois buckets GCS em seu Google cloud account que Databricks cria para cada workspace. Em geral, use o Deep Clone para tabelas Delta e converta os dados para o formato Delta para usar o Deep Clone, se possível, para outros formatos de dados.
Terminologia do status da implantação
Este artigo usa as seguintes definições de status de implantação:
Implementação ativa: Os usuários podem se conectar a uma implementação ativa de cargas de trabalho de Databricks workspace e execução. Os trabalhos são agendados periodicamente usando o programador Databricks ou outro mecanismo. A transmissão de dados também pode ser executada nessa implantação. Alguns documentos podem se referir a uma implantação ativa como uma implantação a quente.
Implantação passiva: Os processos não são executados em uma implantação passiva. IT As equipes podem definir procedimentos automatizados para implantar código, configuração e outros objetos do Databricks na implementação passiva. Um desdobramento só se torna ativo se um desdobramento ativo atual estiver inativo. Alguns documentos podem se referir a uma implementação passiva como uma implementação fria.
Importante
Um projeto pode, opcionalmente, incluir várias implantações passivas em diferentes regiões para oferecer opções adicionais de resolução de interrupções regionais.
De modo geral, uma equipe tem apenas uma implementação ativa por vez, no que é chamado de estratégia de recuperação de desastres ativa-passiva. Há uma estratégia menos comum de soluções de recuperação de desastres chamada ativo-ativo, na qual há duas implantações ativas simultâneas.
Terminologia das indústrias de recuperação de desastres
Há dois termos importantes sobre indústrias que o senhor deve entender e definir para sua equipe:
Objetivo do ponto de recuperação: Um objetivo de ponto de recuperação (RPO) é o período máximo visado em que os dados (transações) podem ser perdidos de um serviço IT devido a um incidente grave. Sua implantação da Databricks não armazena os principais dados do cliente. Isso é armazenado em sistemas separados, como Google Cloud Storage ou outra fonte de dados sob seu controle. O plano de controle do Databricks armazena alguns objetos de forma parcial ou total, como Job e Notebook. Para Databricks, o RPO é definido como o período máximo visado em que objetos como Job e Notebook podem ser perdidos. Além disso, o senhor é responsável por definir o RPO para seus próprios dados do cliente em Google Cloud Storage ou outra fonte de dados sob seu controle.
Objetivo de tempo de recuperação: O objetivo de tempo de recuperação (RTO) é a duração de tempo e o nível de serviço dentro dos quais um processo comercial deve ser restaurado após um desastre.
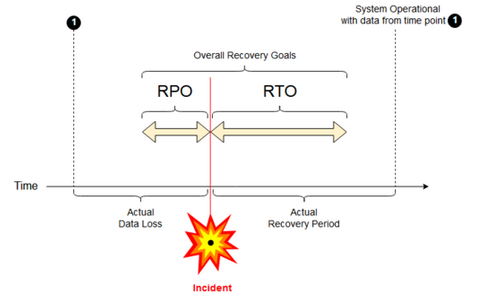
Recuperação de desastres e corrupção de dados
Uma solução de recuperação de desastres não reduz a corrupção de dados. Os dados corrompidos na região primária são replicados da região primária para uma região secundária e são corrompidos em ambas as regiões. Há outras maneiras de mitigar esse tipo de falha, por exemplo, Delta viagem do tempo.
Fluxo de trabalho típico de recuperação
Um cenário de recuperação de desastres da Databricks normalmente se desenrola da seguinte maneira:
Ocorre uma falha em um serviço crítico que o senhor usa em sua região primária. Pode ser uma fonte de dados de serviço ou uma rede que afeta a implementação do Databricks.
O senhor investiga a situação com o provedor cloud.
Se o senhor concluir que sua empresa não pode esperar que o problema seja resolvido na região primária, talvez decida que precisa de um failover para uma região secundária.
Verifique se o mesmo problema não afeta também a região secundária.
Fazer o failover para uma região secundária.
Interrompa todas as atividades no site workspace. Os usuários interrompem as cargas de trabalho. Os usuários ou administradores são instruídos a fazer um backup das alterações recentes, se possível. Os trabalhos são encerrados se ainda não tiverem falhado devido à interrupção.
começar o procedimento de recuperação na região secundária. O procedimento de recuperação atualiza o roteamento e a renomeação das conexões e do tráfego de rede para a região secundária.
Após o teste, declare a região secundária operacional. As cargas de trabalho de produção podem agora ser retomadas. Os usuários podem acessar log in para a implantação agora ativa. O senhor pode reativar o trabalho agendado ou atrasado.
Para obter detalhes sobre os passos em um contexto Databricks, consulte Testar failover.
Em algum momento, o problema na região primária é atenuado e o senhor confirma esse fato.
Restaure (fail back) para sua região primária.
Interromper todo o trabalho na região secundária.
começar o procedimento de recuperação na região primária. O procedimento de recuperação lida com o roteamento e a renomeação da conexão e do tráfego de rede de volta à região primária.
Replicar os dados de volta para a região primária, conforme necessário. Para reduzir a complexidade, talvez seja necessário minimizar a quantidade de dados que precisam ser replicados. Por exemplo, se alguns trabalhos forem somente de leitura quando executados na implementação secundária, talvez não seja necessário replicar esses dados de volta para a implementação primária na região primária. No entanto, o senhor pode ter uma produção Job que precisa ser executada e pode precisar de replicação de dados de volta para a região primária.
Teste a implementação na região primária.
Declare que sua região primária está operacional e que é sua implantação ativa. Retomar as cargas de trabalho de produção.
Para obter mais informações sobre a restauração para a região primária, consulte Restauração de teste (failback).
Importante
Durante essas passo, pode ocorrer alguma perda de dados. Sua organização deve definir quanta perda de dados é aceitável e o que você pode fazer para mitigar essa perda.
Passo 1: Entenda as necessidades do seu negócio
Seu primeiro passo é definir e entender as necessidades de sua empresa. Defina quais serviços de dados são essenciais e quais são os RPO e RTO esperados.
Pesquise a tolerância do mundo real de cada sistema e lembre-se de que o failover e o failback de recuperação de desastres podem ser caros e acarretar outros riscos. Outros riscos podem incluir corrupção de dados, dados duplicados se o senhor gravar no local de armazenamento errado e usuários que log in e fazem alterações nos locais errados.
Mapeie todos os pontos de integração da Databricks que afetam seus negócios:
Suas soluções de recuperação de desastres precisam acomodar processos interativos, processos automatizados ou ambos?
Quais serviços de dados o senhor usa? Alguns podem ser on-premises.
Como os dados de entrada chegam ao site cloud?
Quem consome esses dados? Quais processos o consomem no downstream?
Há integrações de terceiros que precisam estar cientes das mudanças na recuperação de desastres?
Determine as ferramentas ou estratégias de comunicação que podem apoiar seu plano de recuperação de desastres:
Que ferramentas o senhor usará para modificar rapidamente as configurações de rede?
O senhor pode predefinir sua configuração e torná-la modular para acomodar soluções de recuperação de desastres de forma natural e sustentável?
Quais ferramentas e canais de comunicação notificarão as equipes internas e terceiros (integrações, consumidores downstream) sobre as alterações de failover e failback de recuperação de desastres? E como o senhor confirmará o reconhecimento deles?
Quais ferramentas ou suporte especial serão necessários?
Qual serviço, se houver algum, será desativado até que a recuperação completa esteja em vigor?
Passo 2: Escolha um processo que atenda às suas necessidades de negócios
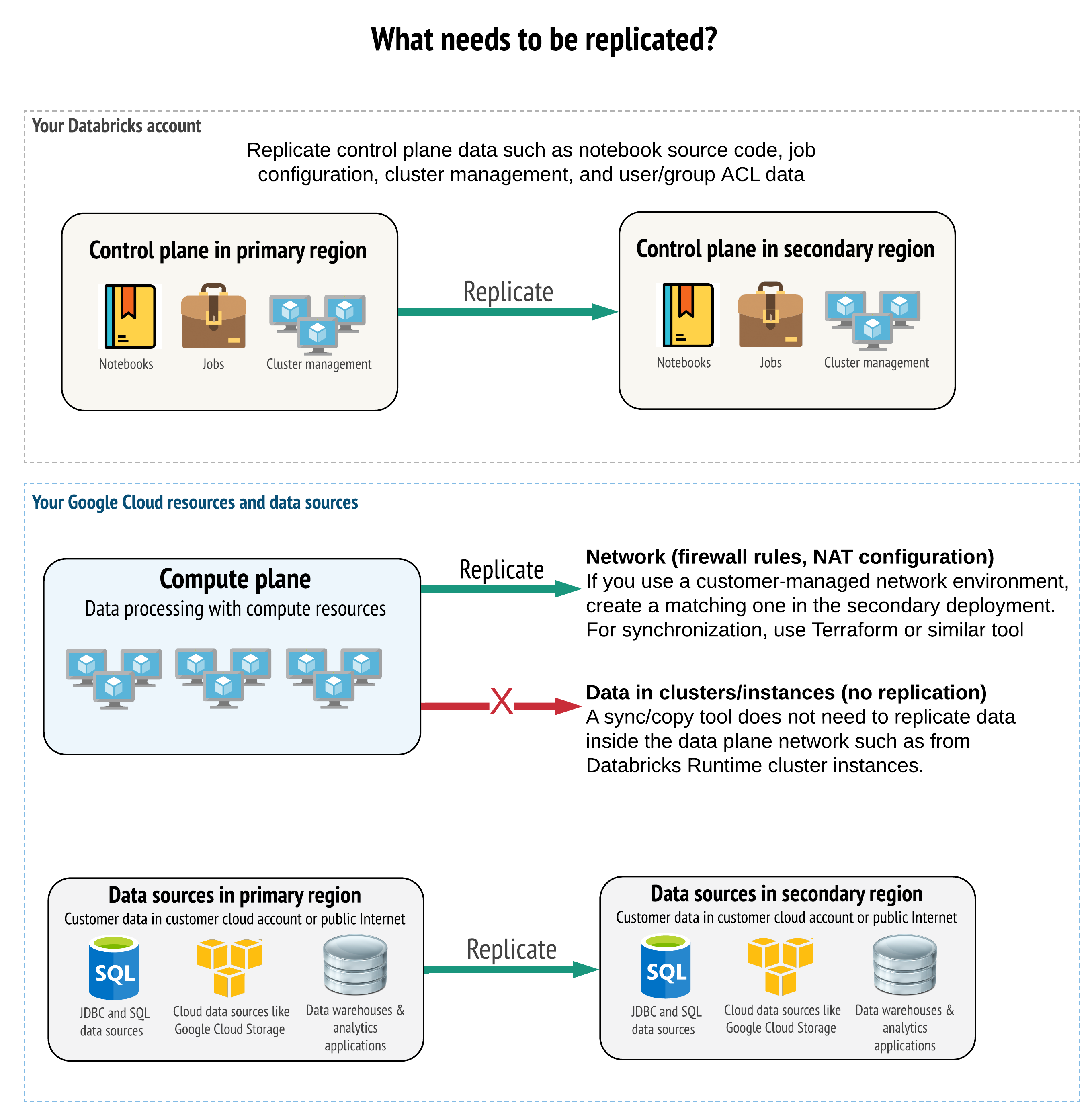
Suas soluções devem replicar os dados corretos no plano de controle, no plano compute e na fonte de dados. O espaço de trabalho redundante para recuperação de desastres deve ser mapeado para diferentes planos de controle em diferentes regiões. O senhor deve manter esses dados sincronizados periodicamente usando uma solução baseada em script, seja uma ferramenta de sincronização ou um CI/CD fluxo de trabalho. Não há necessidade de sincronizar os dados da própria rede do plano compute, como, por exemplo, do trabalhador Databricks Runtime.
Além disso, o senhor precisa garantir que sua fonte de dados seja replicada conforme necessário entre as regiões.
Práticas recomendadas gerais
As práticas recomendadas gerais para um plano de recuperação de desastres bem-sucedido incluem:
Entenda quais processos são essenciais para os negócios e precisam ser executados na recuperação de desastres.
Identifique claramente quais serviços estão envolvidos, quais dados estão sendo processados, qual é o fluxo de dados e onde eles são armazenados
Isolar o serviço e os dados o máximo possível. Por exemplo, crie um contêiner de armazenamento cloud especial para os dados de recuperação de desastres ou mova os objetos Databricks que são necessários durante um desastre para um workspace separado.
É sua responsabilidade manter a integridade entre as implantações primária e secundária de outros objetos que não estão armazenados no plano de controle do Databricks.
Aviso
É uma prática recomendada não armazenar dados no bucket raiz GCS que é usado para acesso DBFS root para o workspace. Esse armazenamento DBFS root não é compatível com a produção de dados do cliente. Databricks também recomenda não armazenar biblioteca, arquivos de configuração ou script de inicialização nesse local.
Para fontes de dados, sempre que possível, recomenda-se que o senhor use as ferramentas nativas do Google cloud para replicação e redundância para replicar dados para as regiões de recuperação de desastres.
Escolha uma estratégia de soluções de recuperação
As soluções típicas de recuperação de desastres envolvem dois (ou possivelmente mais) workspace. Existem várias estratégias que você pode escolher. Considere a duração potencial da interrupção (horas ou talvez até um dia), o esforço para garantir que o workspace esteja totalmente operacional e o esforço para restaurar (fazer fail back) para a região primária.
Estratégia de soluções ativo-passivo
Uma solução ativa-passiva é a mais comum e a mais fácil, e esse tipo de solução é o foco deste artigo. Uma solução ativa-passiva sincroniza as alterações de dados e objetos da implementação ativa para a implementação passiva. Se preferir, o senhor pode ter várias implantações passivas em diferentes regiões, mas este artigo se concentra na abordagem de implantação passiva única. Durante um evento de recuperação de desastres, a implementação passiva na região secundária torna-se sua implementação ativa.
Há duas variantes principais dessa estratégia:
Soluções unificadas (para toda a empresa): Exatamente um conjunto de implementações ativas e passivas que dão suporte a toda a organização.
soluções por departamento ou projeto: Cada departamento ou domínio de projeto mantém soluções de recuperação de desastres separadas. Algumas organizações querem dissociar os detalhes da recuperação de desastres entre os departamentos e usar regiões primárias e secundárias diferentes para cada equipe com base nas necessidades exclusivas de cada equipe.
Há outras variantes, como o uso de uma implementação passiva para casos de uso somente de leitura. Se o senhor tiver cargas de trabalho que sejam somente de leitura, por exemplo, consultas de usuários, elas poderão ser executadas em uma solução passiva a qualquer momento se não modificarem dados ou objetos Databricks, como Notebook ou Job.
Estratégia de soluções ativo-ativo
Em uma solução ativa-ativa, o senhor executa todos os processos de dados em ambas as regiões, sempre em paralelo. Sua equipe de operações deve garantir que um processo de dados, como o Job, seja marcado como concluído somente quando for finalizado com sucesso em ambas as regiões. Os objetos não podem ser alterados na produção e devem seguir uma promoção rigorosa de CI/CD do desenvolvimento/preparação para a produção.
Uma solução ativa-ativa é a estratégia mais complexa e, como o trabalho é executado em ambas as regiões, há um custo financeiro adicional.
Assim como na estratégia ativa-passiva, o senhor pode implementá-la como uma organização unificada ou por departamento.
Talvez o senhor não precise de um workspace equivalente no sistema secundário para todo o espaço de trabalho, dependendo do seu fluxo de trabalho. Por exemplo, talvez um site de desenvolvimento ou de preparação workspace não precise de uma duplicata. Com um desenvolvimento bem projetado pipeline, o senhor poderá reconstruir facilmente esse espaço de trabalho, se necessário.
Escolha suas ferramentas
Há duas abordagens principais para que as ferramentas mantenham os dados tão semelhantes quanto possível entre o espaço de trabalho em suas regiões primária e secundária:
Cliente de sincronização que copia do primário para o secundário: um cliente de sincronização envia dados de produção e ativos da região primária para a região secundária. Normalmente, essa execução é feita de forma programada.
CI/CD para implantação paralela: Para o código de produção e o ativo, use a ferramentaCI/CD que envia as alterações para os sistemas de produção simultaneamente para ambas as regiões. Por exemplo, ao enviar o código e o ativo da fase de preparação/desenvolvimento para a produção, um sistema CI/CD o torna disponível em ambas as regiões ao mesmo tempo. A ideia central é tratar todos os artefatos em um Databricks workspace como Infrastructure-as-Code. A maioria dos artefatos pode ser implantada conjuntamente no espaço de trabalho primário e secundário, enquanto alguns artefatos podem precisar ser implantados somente após um evento de recuperação de desastres. Para obter ferramentas, consulte Scripts, amostras e protótipos de automação.
O diagrama a seguir contrasta essas duas abordagens.
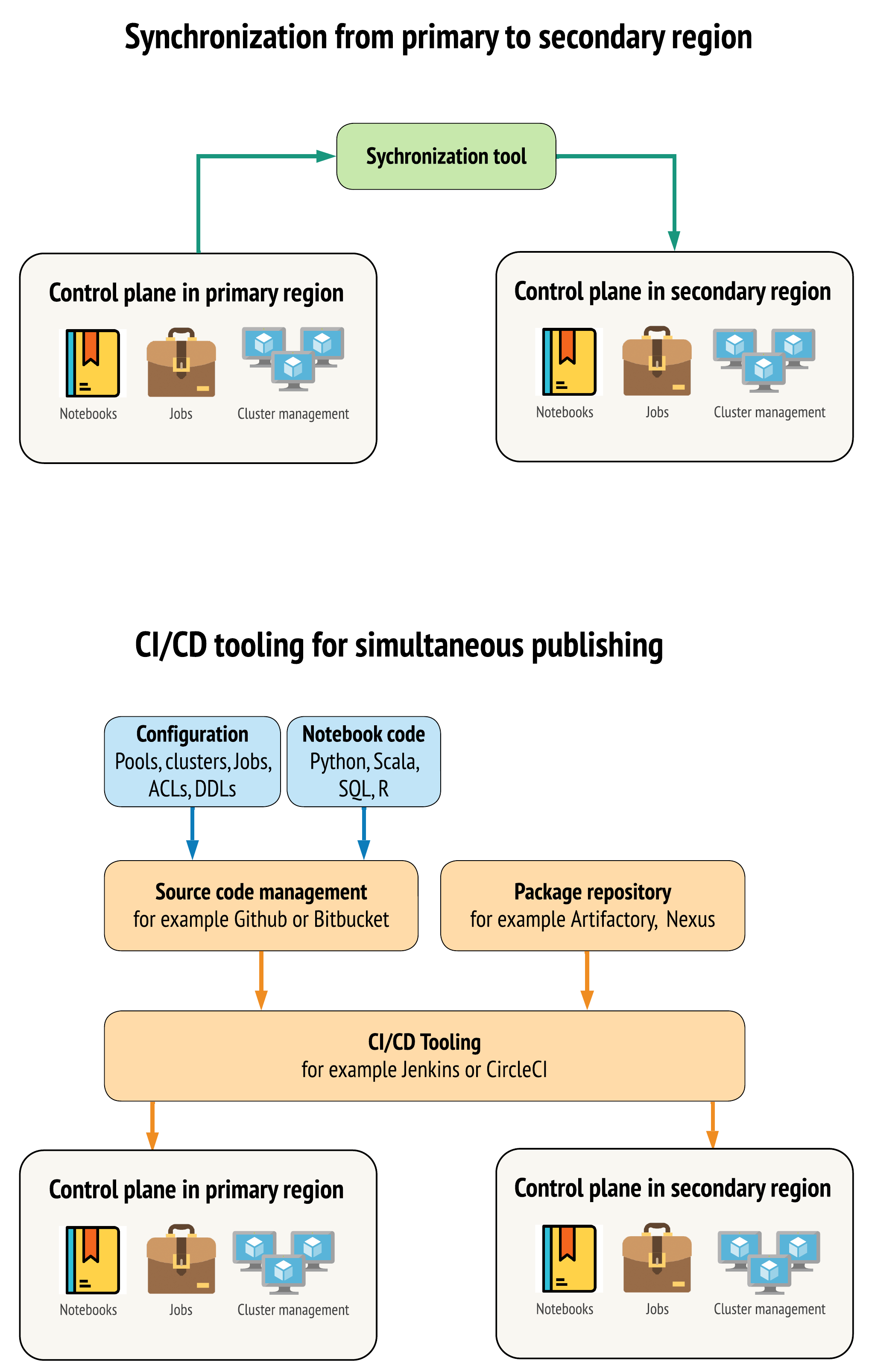
Dependendo das suas necessidades, o senhor pode combinar as abordagens. Por exemplo, use CI/CD para o código-fonte Notebook, mas use a sincronização para configurações como pool e controles de acesso.
A tabela a seguir descreve como lidar com diferentes tipos de dados com cada opção de ferramenta.
Descrição |
Como lidar com as ferramentas de CI/CD |
Como lidar com a ferramenta de sincronização |
|---|---|---|
Código-fonte: Notebook exportações de código-fonte e código-fonte para pacote biblioteca |
Co-implantado tanto no primário quanto no secundário. |
Sincronizar o código-fonte do primário para o secundário. |
Usuários e grupos |
Gerenciar metadados como configuração em Git. Como alternativa, use o mesmo provedor de identidade (IdP) para ambos os espaços de trabalho. Co-implantado dados de usuários e grupos para implantações primárias e secundárias. |
Use o SCIM ou outra automação para ambas as regiões. A criação manual não é recomendada, mas, se for usada, deve ser feita para ambos ao mesmo tempo. Se o senhor usar uma configuração manual, crie um processo automatizado programado para comparar a lista de usuários e grupos entre as duas implementações. |
pool configurações |
Pode ser padrão em Git. Co-implantado no primário e no secundário. No entanto, |
pool criado com qualquer |
Job configurações |
Pode ser padrão em Git. Para a implementação primária, implante a definição Job como está. Para a implementação secundária, implante o site Job e defina as simultaneidades como zero. Isso desativa o Job nessa implantação e impede a execução extra. Altere o valor de simultaneidade depois que a implementação secundária se tornar ativa. |
Se a execução do trabalho no |
Listas de controle de acesso (ACLs) |
Pode ser padrão em Git. Co-implantado em implantações primárias e secundárias para Notebook, pastas e clusters. No entanto, mantenha os dados para o trabalho até o evento de recuperação de desastres. |
O Permissions API pode definir controles de acesso para clusters, Job, pool, Notebook e pastas. Um cliente de sincronização precisa mapear os IDs de objeto correspondentes para cada objeto no site secundário workspace. Databricks recomenda a criação de um mapa de IDs de objetos do site primário para o secundário workspace e a sincronização desses objetos antes de replicar os controles de acesso. |
bibliotecas |
Incluir no código-fonte e cluster/Job padrão. |
Sincronize a biblioteca personalizada a partir de repositórios centralizados, DBFS ou do armazenamento cloud (pode ser montado). |
Inclua no código-fonte, se preferir. |
Para simplificar a sincronização, armazene o script de inicialização no site principal workspace em uma pasta comum ou em um pequeno conjunto de pastas, se possível. |
|
Pontos de montagem |
Inclua no código-fonte se for criado somente por meio do Job baseado em Notebookou do comando API. |
Use Job. Observe que o endpoint de armazenamento pode mudar, já que o espaço de trabalho estaria em regiões diferentes. Isso também depende muito de sua estratégia de recuperação de desastres de dados. |
Metadados da tabela |
Inclua o código-fonte se for criado somente por meio do Job baseado em Notebookou do comando API. Isso se aplica tanto ao metastore interno do Databricks quanto ao metastore externo configurado. |
Compare as definições de metadados entre os metastore usando a API de catálogo do Spark ou SHOW CREATE TABLE por meio de um Notebook ou scripts. Observe que as tabelas para armazenamento subjacente podem ser baseadas em região e serão diferentes entre instâncias de metastore. |
segredos |
Incluir no código-fonte se for criado somente por meio do comando API. Observe que talvez seja necessário alterar o conteúdo de alguns segredos entre o primário e o secundário. |
Os segredos são criados em ambos os espaços de trabalho por meio do site API. Observe que talvez seja necessário alterar o conteúdo de alguns segredos entre o primário e o secundário. |
Configurações de cluster |
Pode ser padrão em Git. Co-implantado em implantações primárias e secundárias, embora aquelas em implantação secundária devam ser encerradas até o evento de recuperação de desastres. |
clusters são criados depois de serem sincronizados com o site secundário workspace usando API ou CLI. Esses podem ser encerrados explicitamente se o senhor quiser, dependendo das configurações de encerramento automático. |
Notebook, Job, e permissões de pasta |
Pode ser padrão em Git. Co-implantado em implantações primárias e secundárias. |
Replicar usando a API de permissões. |
Escolha regiões e múltiplos espaços de trabalho secundários
O senhor precisa ter controle total do seu gatilho de recuperação de desastres. O senhor pode decidir acionar isso a qualquer momento ou por qualquer motivo. O senhor deve assumir a responsabilidade pela estabilização da recuperação de desastres antes de poder reiniciar suas operações no modo failback (produção normal). Normalmente, isso significa que o senhor precisa criar vários espaços de trabalho Databricks para atender às suas necessidades de produção e recuperação de desastres e escolher a região de failover secundária.
No Google cloud, o senhor pode ter controle total da região secundária escolhida. Certifique-se de que todos os seus recursos e produtos estejam disponíveis nessa região. Alguns serviços do Databricks estão disponíveis somente em algumas regiões do Google cloud .
Passo 3: preparar espaços de trabalho e fazer uma cópia única
Se o site workspace já estiver em produção, é comum executar uma única operação de cópia para sincronizar a implantação passiva com a implantação ativa. Essa cópia única lida com o seguinte:
Replicação de dados: Replique usando as soluções de replicação cloud ou as operações do Delta Deep Clone.
geração de tokens: Use a geração de tokens para automatizar a replicação e as cargas de trabalho futuras.
replicaçãoworkspace : Use a replicação workspace usando os métodos descritos na passo 4: Prepare sua fonte de dados.
workspace validação: - teste para garantir que o site workspace e o processo possam ser executados com êxito e fornecer os resultados esperados.
Após as operações de cópia únicas iniciais, as ações subsequentes de cópia e sincronização são mais rápidas e qualquer registro de suas ferramentas também é um log do que mudou e quando mudou.
Passo 4: Prepare sua fonte de dados
Databricks pode processar uma grande variedade de fontes de dados usando processamento de lotes ou transmissão de dados.
Antes de implementar um sistema para sua fonte de dados, é importante entender a diferença de replicação entre GCS e BigQuery:
Para o BigQuery, os dados são replicados. Os dados corrompidos podem ser recuperados por até sete dias (supondo que não haja backups).
Para o GCS que usa o Delta Lake, a replicação depende do tipo de bucket, como simples, duplo ou múltiplo. Os dados corrompidos podem ser recuperados dependendo da retenção do vácuo.
processamento de lotes a partir da fonte de dados
Quando os dados são processados em lotes, eles geralmente residem em uma fonte de dados que pode ser replicada facilmente ou entregue em outra região.
Por exemplo, os dados podem ser carregados regularmente em um local de armazenamento cloud. No modo de recuperação de desastres da região secundária, o senhor deve garantir que os arquivos sejam carregados no armazenamento da região secundária. As cargas de trabalho devem ler o armazenamento da região secundária e gravar no armazenamento da região secundária.
Transmissão de dados
O processamento de uma transmissão de dados é um desafio maior. Os dados de transmissão podem ser ingeridos de várias fontes, processados e enviados para uma solução de transmissão:
Fila de mensagens, como Kafka ou Pub/Sub Lite
Banco de dados de captura de dados de alterações (CDC) transmissão
Processamento contínuo baseado em arquivos
Processamento programado baseado em arquivos, também conhecido como trigger once
Em todos esses casos, o senhor deve configurar a fonte de dados para lidar com o modo de recuperação de desastres e usar a implementação secundária na região secundária.
Um gravador de transmissão armazena um ponto de verificação com informações sobre os dados que foram processados. Esse ponto de verificação pode conter um local de dados (geralmente o armazenamento cloud ) que precisa ser modificado para um novo local para garantir o reinício bem-sucedido da transmissão. Por exemplo, a subpasta source sob o ponto de verificação pode armazenar a pasta cloud baseada em arquivo.
Esse ponto de controle deve ser replicado em tempo hábil. Considere a sincronização do intervalo do ponto de verificação com qualquer nova solução de replicação cloud.
A atualização do ponto de verificação é uma função do gravador e, portanto, aplica-se à ingestão ou ao processamento da transmissão de dados e ao armazenamento em outra fonte de transmissão.
Para cargas de trabalho de transmissão, certifique-se de que os pontos de verificação estejam configurados no armazenamento gerenciado pelo cliente para que possam ser replicados na região secundária para a retomada da carga de trabalho a partir do ponto da última falha. O senhor também pode optar por executar o processo de transmissão secundário em paralelo ao processo primário.
Passo 5: Implemente e teste suas soluções
Teste periodicamente sua configuração de recuperação de desastres para garantir que ela funcione corretamente. Não vale a pena manter uma solução de recuperação de desastres se o senhor não puder usá-la quando precisar. Algumas empresas alternam entre regiões a cada poucos meses. A troca de regiões em um programa regular testa suas suposições e processos e garante que eles atendam às suas necessidades de recuperação. Isso também garante que sua organização esteja familiarizada com as políticas e os procedimentos para emergências.
Importante
Teste regularmente suas soluções de recuperação de desastres em condições reais.
Se o senhor descobrir que está faltando um objeto ou padrão e ainda precisar contar com as informações armazenadas no seu sistema primário workspace, modifique seu plano para remover esses obstáculos, replique essas informações no sistema secundário ou disponibilize-as de alguma outra forma.
Teste as mudanças organizacionais necessárias em seus processos e na configuração em geral. Seu plano de recuperação de desastres afeta o pipeline de implementação, e é importante que sua equipe saiba o que precisa ser mantido em sincronia. Depois de configurar o espaço de trabalho de recuperação de desastres, o senhor deve garantir que sua infraestrutura (manual ou código), Job, Notebook, biblioteca e outros objetos workspace estejam disponíveis na região secundária.
Converse com sua equipe sobre como expandir os processos de trabalho padrão e o pipeline de configuração para implantar alterações em todo o espaço de trabalho. gerenciar identidades de usuários em todos os espaços de trabalho. Lembre-se de configurar ferramentas como Job automation e monitoramento para o novo espaço de trabalho.
Planejar e testar alterações nas ferramentas de configuração:
Ingestão: Entenda onde estão suas fontes de dados e onde essas fontes obtêm seus dados. Sempre que possível, parametrize a origem e garanta que o senhor tenha um padrão de configuração separado para trabalhar com suas implantações secundárias e regiões secundárias. Prepare um plano para failover e teste todas as suposições.
Alterações na execução: Se o senhor tiver um programador para acionar o Job ou outras ações, talvez seja necessário configurar um programador separado que funcione com a implementação secundária ou com sua fonte de dados. Prepare um plano para failover e teste todas as suposições.
Conectividade interativa: Considere como a configuração, a autenticação e as conexões de rede podem ser afetadas pela interrupção regional para qualquer uso de REST APIs, ferramentas CLI ou outro serviço, como JDBC/ODBC. Prepare um plano para failover e teste todas as suposições.
Mudanças na automação: Para todas as ferramentas de automação, prepare um plano para failover e teste todas as suposições.
Saídas: Para todas as ferramentas que geram dados de saída ou logs, prepare um plano para failover e teste todas as suposições.
Teste de failover
A recuperação de desastres pode ser acionada por muitos cenários diferentes. Ela pode ser acionada por uma interrupção inesperada. Algumas funcionalidades principais podem estar fora do ar, incluindo a rede cloud, o armazenamento cloud ou outro serviço principal. O senhor não tem acesso para desligar o sistema de forma adequada e precisa tentar se recuperar. No entanto, o processo pode ser acionado por um desligamento ou uma interrupção planejada, ou mesmo pela alternância periódica de suas implantações ativas entre duas regiões.
Quando o senhor testar o failover, conecte-se ao sistema e execute um processo de desligamento. Verifique se todos os trabalhos foram concluídos e se o site clusters foi encerrado.
Um cliente de sincronização (ou a ferramenta CI/CD ) pode replicar objetos e recursos relevantes do Databricks para o workspace secundário. Para ativar seu workspace secundário, seu processo pode incluir alguns ou todos os itens a seguir:
execução de testes para confirmar que a plataforma está atualizada.
Desative o pool e clusters na região primária para que, se o serviço com falha voltar a ficar on-line, a região primária não comece a processar novos dados.
Processo de recuperação:
Verifique a data dos últimos dados sincronizados. Consulte a terminologia das indústrias de recuperação de desastres. Os detalhes desse passo variam de acordo com a forma como o senhor sincroniza os dados e suas necessidades comerciais específicas.
Estabilize sua fonte de dados e garanta que todos eles estejam disponíveis. Inclua todas as fontes de dados externas, como Google cloud SQL, BigQuery, ou Pub/Sub, bem como seus arquivos Delta Lake, Parquet, ou outros.
Encontre o ponto de recuperação da transmissão. Configure o processo para reiniciar a partir daí e tenha um processo pronto para identificar e eliminar possíveis duplicatas (o Delta Lake Lake facilita isso).
Conclua o processo de fluxo de dados e informe os usuários.
começar o pool relevante (ou aumentar o
min_idle_instancespara o número relevante).começar relevante clusters (se não for rescindido).
Altere a execução concorrente do Job e a execução relevante do Job. Essas execuções podem ser únicas ou periódicas.
Para qualquer ferramenta externa que use um URL ou nome de domínio para o seu Databricks workspace, atualize as configurações para account para o novo plano de controle. Por exemplo, atualizar URLs para APIs REST e conexões JDBC/ODBC. O URL voltado para o cliente do aplicativo da Web Databricks muda quando o plano de controle é alterado, portanto, notifique os usuários da sua organização sobre o novo URL.
Teste de restauração (failback)
O failback é mais fácil de controlar e pode ser feito em uma janela de manutenção. Esse plano pode incluir alguns ou todos os itens a seguir:
Obter confirmação de que a região primária foi restaurada.
Desative o pool e clusters na região secundária para que ela não comece a processar novos dados.
Sincronize qualquer ativo novo ou modificado no workspace secundário de volta à implementação primária. Dependendo do design de seus scripts de failover, o senhor poderá executar os mesmos scripts para sincronizar os objetos da região secundária (recuperação de desastres) com a região primária (produção).
Sincronize todas as novas atualizações de dados com a implementação primária. O senhor pode usar as trilhas de auditoria de logs e tabelas Delta para garantir que não haja perda de dados. Observe que alguns gerenciar fonte de dados têm janelas de tempo limitadas para recuperação usando o Snapshot automatizado. Por exemplo, o Google BigQuery tem um limite de sete dias para a restauração de dados.
Desligue todas as cargas de trabalho na região de recuperação de desastres.
Altere o URL do trabalho e dos usuários para a região primária.
execução de testes para confirmar que a plataforma está atualizada.
começar o pool relevante (ou aumentar o
min_idle_instancespara um número relevante) .começar relevante clusters (se não for rescindido).
Altere a execução concorrente do Job e a execução relevante do Job. Essas execuções podem ser únicas ou periódicas.
Conforme necessário, configure a região secundária novamente para recuperação futura de desastres.
Scripts, amostras e protótipos de automação
Scripts de automação a serem considerados em seus projetos de recuperação de desastres:
A Databricks recomenda que o senhor use o Databricks Terraform Provider para ajudar a desenvolver seu próprio processo de sincronização.
Consulte também Databricks Workspace Migration Tools para obter exemplos de automação e scripts de protótipo.
O projeto Databricks Sync (DBSync) é uma ferramenta de sincronização de objetos que faz backup, restaura e sincroniza o espaço de trabalho do Databricks.