Desenvolver código de pipeline com Python
Delta Live Tables introduz várias novas construções de código Python para definir a visualização materializada e as tabelas de transmissão no pipeline. Python o suporte para o desenvolvimento de pipeline baseia-se nos fundamentos de PySpark DataFrame e transmissão estruturada APIs.
Para usuários não familiarizados com Python e DataFrames, a Databricks recomenda o uso da interface SQL. Consulte Desenvolver código de pipeline com SQL.
Para obter uma referência completa da sintaxe Python do Delta Live Tables, consulte Referência da linguagem Python do Delta Live Tables.
Noções básicas de Python para desenvolvimento de pipeline
Python O código que cria o conjunto de dados Delta Live Tables deve retornar DataFrames.
Todas as APIs Python do Delta Live Tables são implementadas no módulo dlt. Seu código Delta Live Tables pipeline implementado com Python deve importar explicitamente o módulo dlt na parte superior do Python Notebook e dos arquivos.
Delta Live TablesO código Python específico difere de outros tipos de código Python de uma maneira crítica: o código Python pipeline não chama diretamente as funções que realizam a ingestão de dados e transformações para criar o conjunto de dados Delta Live Tables. Em vez disso, o Delta Live Tables interpreta as funções de decoração do módulo dlt em todos os arquivos de código-fonte configurados em um pipeline e cria um gráfico de fluxo de dados.
Importante
Para evitar um comportamento inesperado na execução do pipeline, não inclua código que possa ter efeitos colaterais nas funções que definem o conjunto de dados. Para saber mais, consulte a referência do Python.
Crie uma tabela materializada view ou de transmissão com Python
O decorador @dlt.table informa ao site Delta Live Tables para criar uma tabela materializada view ou de transmissão com base nos resultados retornados por uma função. Os resultados de uma leitura de lotes criam uma tabela materializada view, enquanto os resultados de uma leitura de transmissão criam uma tabela de transmissão.
Em default, os nomes das tabelas materializadas view e de transmissão são inferidos a partir dos nomes das funções. O exemplo de código a seguir mostra a sintaxe básica para a criação de uma tabela materializada view e de transmissão:
Observação
Ambas as funções fazem referência à mesma tabela no catálogo samples e usam a mesma função decoradora. Esses exemplos destacam que a única diferença na sintaxe básica da visualização materializada e das tabelas de transmissão é usar spark.read em vez de spark.readStream.
Nem todas as fontes de dados suportam leituras de transmissão. Algumas fontes de dados devem sempre ser processadas com a semântica de transmissão.
import dlt
@dlt.table()
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dlt.table()
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Opcionalmente, você pode especificar o nome da tabela usando o argumento name no decorador @dlt.table. O exemplo a seguir demonstra esse padrão para uma tabela materializada view e transmissão:
import dlt
@dlt.table(name = "trips_mv")
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dlt.table(name = "trips_st")
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Carregar dados do armazenamento de objetos
O Delta Live Tables suporta o carregamento de dados de todos os formatos suportados pela Databricks. Consulte Opções de formato de dados.
Observação
Esses exemplos usam dados disponíveis no /databricks-datasets montado automaticamente em seu site workspace. Databricks recomenda o uso de caminhos de volume ou URIs cloud para fazer referência aos dados armazenados no armazenamento de objetos cloud. Consulte O que são volumes do Unity Catalog?
Databricks recomenda o uso das tabelas Auto Loader e transmissão ao configurar cargas de trabalho de ingestão incremental em relação aos dados armazenados no armazenamento de objetos cloud. Consulte O que é o Auto Loader?
O exemplo a seguir cria uma tabela de transmissão a partir dos arquivos JSON usando Auto Loader:
import dlt
@dlt.table()
def ingestion_st():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
O exemplo a seguir usa a semântica de lotes para ler um diretório JSON e criar um view materializado:
import dlt
@dlt.table()
def batch_mv():
return spark.read.format("json").load("/databricks-datasets/retail-org/sales_orders")
Valide os dados de acordo com as expectativas
Você pode usar as expectativas para definir e aplicar restrições de qualidade de dados. Veja como gerenciar a qualidade dos dados com Delta Live Tables.
O código a seguir usa @dlt.expect_or_drop para definir uma expectativa chamada valid_data que descarta registros nulos durante a ingestão de dados:
import dlt
@dlt.table()
@dlt.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders_valid():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
Consultar a visualização materializada e as tabelas de transmissão definidas em seu pipeline
Use o esquema LIVE para consultar outras visualizações materializadas e tabelas de transmissão definidas em seu site pipeline.
O exemplo a seguir define quatro conjuntos de dados:
Uma tabela de transmissão denominada
ordersque carrega dados do site JSON.Um view materializado chamado
customersque carrega os dados do CSV.Um view materializado chamado
customer_ordersque une registros dos conjuntos de dadosordersecustomers, converte o carimbo de data/hora do pedido em uma data e seleciona os camposcustomer_id,order_number,stateeorder_date.Um view materializado chamado
daily_orders_by_stateque agrega a contagem diária de pedidos para cada estado.
import dlt
from pyspark.sql.functions import col
@dlt.table()
@dlt.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
@dlt.table()
def customers():
return spark.read.format("csv").option("header", True).load("/databricks-datasets/retail-org/customers")
@dlt.table()
def customer_orders():
return (spark.read.table("LIVE.orders")
.join(spark.read.table("LIVE.customers"), "customer_id")
.select("customer_id",
"order_number",
"state",
col("order_datetime").cast("int").cast("timestamp").cast("date").alias("order_date"),
)
)
@dlt.table()
def daily_orders_by_state():
return (spark.read.table("LIVE.customer_orders")
.groupBy("state", "order_date")
.count().withColumnRenamed("count", "order_count")
)
Crie tabelas em um loop for
O senhor pode usar o Python for loops para criar várias tabelas de forma programática. Isso pode ser útil quando o senhor tem muitas fontes de dados ou conjuntos de dados de destino que variam em apenas alguns parâmetros, resultando em menos código total para manter e menos redundância de código.
O loop for avalia a lógica em ordem serial, mas, uma vez concluído o planejamento do conjunto de dados, o pipeline executa a lógica em paralelo.
Importante
Ao usar esse padrão para definir o conjunto de dados, certifique-se de que a lista de valores passada para o loop for seja sempre aditiva. Se um dataset previamente definido em um pipeline for omitido de uma futura execução do pipeline, esse dataset será descartado automaticamente do esquema de destino.
O exemplo a seguir cria cinco tabelas que filtram os pedidos dos clientes por região. Aqui, o nome da região é usado para definir o nome da visualização materializada de destino e para filtrar os dados de origem. A visualização temporária é usada para definir a união das tabelas de origem usadas na construção da visualização materializada final.
import dlt
from pyspark.sql.functions import collect_list, col
@dlt.view()
def customer_orders():
orders = spark.read.table("samples.tpch.orders")
customer = spark.read.table("samples.tpch.customer")
return (orders.join(customer, orders.o_custkey == customer.c_custkey)
.select(
col("c_custkey").alias("custkey"),
col("c_name").alias("name"),
col("c_nationkey").alias("nationkey"),
col("c_phone").alias("phone"),
col("o_orderkey").alias("orderkey"),
col("o_orderstatus").alias("orderstatus"),
col("o_totalprice").alias("totalprice"),
col("o_orderdate").alias("orderdate"))
)
@dlt.view()
def nation_region():
nation = spark.read.table("samples.tpch.nation")
region = spark.read.table("samples.tpch.region")
return (nation.join(region, nation.n_regionkey == region.r_regionkey)
.select(
col("n_name").alias("nation"),
col("r_name").alias("region"),
col("n_nationkey").alias("nationkey")
)
)
# Extract region names from region table
region_list = spark.read.table("samples.tpch.region").select(collect_list("r_name")).collect()[0][0]
# Iterate through region names to create new region-specific materialized views
for region in region_list:
@dlt.table(name=f"{region.lower().replace(' ', '_')}_customer_orders")
def regional_customer_orders(region_filter=region):
customer_orders = spark.read.table("LIVE.customer_orders")
nation_region = spark.read.table("LIVE.nation_region")
return (customer_orders.join(nation_region, customer_orders.nationkey == nation_region.nationkey)
.select(
col("custkey"),
col("name"),
col("phone"),
col("nation"),
col("region"),
col("orderkey"),
col("orderstatus"),
col("totalprice"),
col("orderdate")
).filter(f"region = '{region_filter}'")
)
A seguir, um exemplo do gráfico de fluxo de dados para esse pipeline:
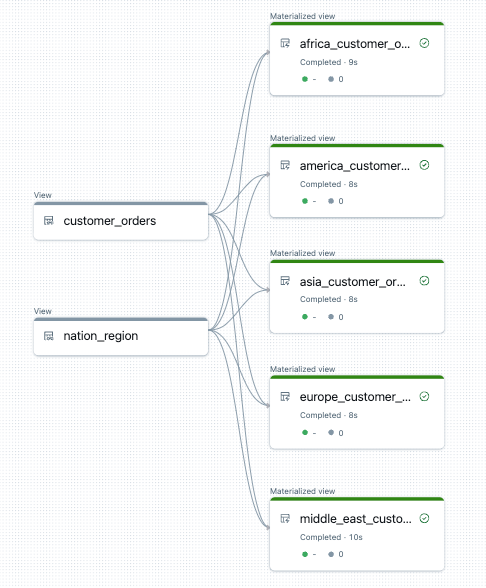
Solução de problemas: o loop for cria muitas tabelas com os mesmos valores
O modelo de execução preguiçosa que o pipeline usa para avaliar o código Python exige que sua lógica faça referência direta a valores individuais quando a função decorada por @dlt.table() é chamada.
O exemplo a seguir demonstra duas abordagens corretas para definir tabelas com um loop for. Nos dois exemplos, cada nome de tabela da lista tables é explicitamente referenciado na função decorada por @dlt.table().
import dlt
# Create a parent function to set local variables
def create_table(table_name):
@dlt.table(name=table_name)
def t():
return spark.read.table(table_name)
tables = ["t1", "t2", "t3"]
for t_name in tables:
create_table(t_name)
# Call `@dlt.table()` within a for loop and pass values as variables
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dlt.table(name=t_name)
def create_table(table_name=t_name):
return spark.read.table(table_name)
O exemplo a seguir não faz referência aos valores corretamente. Esse exemplo cria tabelas com nomes distintos, mas todas as tabelas carregam dados do último valor no loop for:
import dlt
# Don't do this!
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dlt.table(name=t_name)
def create_table():
return spark.read.table(t_name)