Objetos de banco de dados em Databricks
A Databricks usa dois objetos seguros principais para armazenar e acessar dados.
As tabelas regem o acesso a dados tabulares.
Os volumes controlam o acesso a dados não tabulares.
Este artigo descreve como esses objetos de banco de dados se relacionam com catálogos, esquemas, visualizações e outros objetos de banco de dados em Databricks. Este artigo também fornece uma introdução de alto nível sobre como os objetos do banco de dados funcionam no contexto da arquitetura geral da plataforma.
O que são objetos de banco de dados na Databricks?
Os objetos de banco de dados são entidades que ajudam o senhor a organizar, acessar e controlar os dados. O Databricks usa uma hierarquia de três níveis para organizar os objetos do banco de dados:
Catalog (Catálogo): O contêiner de nível superior, que contém esquemas. Consulte O que são catálogos no Databricks?
Esquema ou banco de dados: Contém objetos de dados. Consulte O que são esquemas em Databricks?
Objetos de dados que podem estar contidos em um esquema:
Volume: um volume lógico de dados não tabulares no armazenamento de objetos cloud. Consulte O que são volumes do Unity Catalog?
Tabela: uma coleção de dados organizada por linhas e colunas. Consulte O que é uma tabela?
view: uma consulta salva em uma ou mais tabelas. Consulte O que é um view?
Função: lógica salva que retorna um valor escalar ou um conjunto de linhas. Consulte Funções definidas pelo usuário (UDFs) no Unity Catalog.
Modelo: um modelo do machine learning pacote com MLflow. Veja como gerenciar o ciclo de vida do modelo em Unity Catalog.
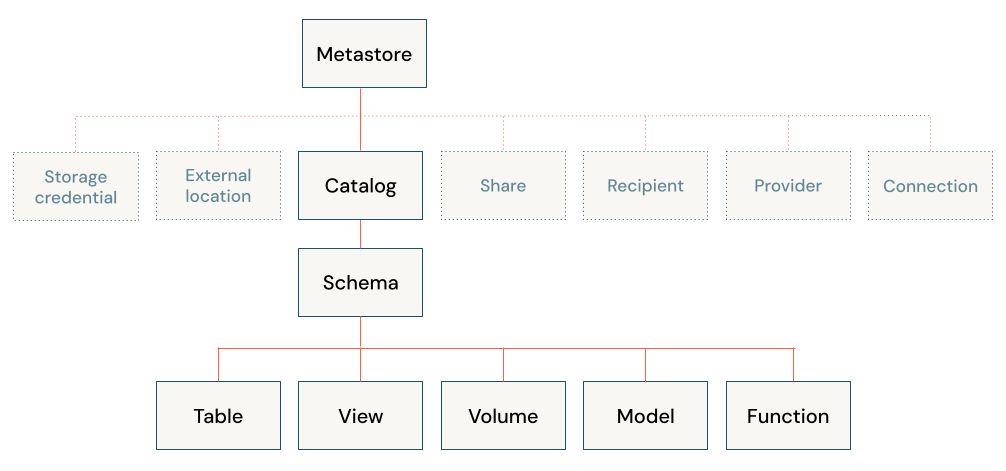
Os catálogos são registrados em um metastore que é gerenciado no nível account. Somente os administradores interagem diretamente com o metastore. Consulte Metastores.
Databricks fornece ativos adicionais para trabalhar com dados, todos eles governáveis usando controles de acesso de nível workspaceou Unity Catalog, as soluções de governança de dados Databricks:
workspace-Dados de nível ativo, como Notebook, fluxo de trabalho e consultas.
Objetos protegíveis do Unity Catalog, como credenciais de armazenamento e compartilhamentos do Delta Sharing, que controlam principalmente o acesso ao armazenamento ou ao compartilhamento seguro.
Para obter mais informações, consulte Database objects vs. workspace securable data ativo e Unity Catalog securable credentials and infrastructure.
Gerenciar o acesso a objetos de banco de dados usando o Unity Catalog
O senhor pode conceder e revogar o acesso aos objetos do banco de dados em qualquer nível da hierarquia, incluindo o próprio metastore. O acesso a um objeto concede implicitamente o mesmo acesso a todos os filhos desse objeto, a menos que o acesso seja revogado.
O senhor pode usar o comando ANSI SQL típico para conceder e revogar o acesso a objetos em Unity Catalog. O senhor também pode usar o Catalog Explorer para o gerenciamento orientado pela interface do usuário dos privilégios do objeto de dados.
Para obter mais informações sobre a proteção de objetos em Unity Catalog, consulte Securable objects in Unity Catalog.
Permissões de objeto padrão no Unity Catalog
Dependendo de como o seu workspace foi criado e habilitado para Unity Catalog, seus usuários podem ter default permissões em catálogos de provisionamento automático, incluindo o catálogo main ou o catálogoworkspace (<workspace-name>). Para obter mais informações, consulte default user privileges.
Se o seu workspace foi ativado para Unity Catalog manualmente, ele inclui um esquema default chamado default no catálogo main que é acessível a todos os usuários no seu workspace. Se o seu workspace foi ativado para Unity Catalog automaticamente e inclui um catálogo <workspace-name>, esse catálogo contém um esquema chamado default que é acessível a todos os usuários no seu workspace.
Objetos de banco de dados vs. workspace dados seguros ativos
Databricks permite que o senhor gerencie vários dados de engenharia, analítica, ML e IA ativa juntamente com os objetos do seu banco de dados. O senhor não registra esses dados ativos em Unity Catalog. Em vez disso, esses ativos são gerenciados no nível workspace, usando listas de controle para controlar as permissões. Esses dados ativos incluem o seguinte:
Notebooks
Painéis
Fluxos de trabalho
workspace arquivos
Consultas SQL
Experiências
A maioria dos dados ativos contém lógica que interage com objetos de banco de dados para consultar funções de uso de dados, modelos de registro ou outras tarefas comuns. Para saber mais sobre como proteger o ativo de dados workspace, consulte Listas de controle de acesso.
Observação
O acesso a compute é controlado por listas de controle de acesso. O senhor configura o site compute com um modo de acesso e pode adicionar permissões cloud adicionais, que controlam como os usuários podem acessar os dados. Databricks recomenda o uso de políticas compute e a restrição de privilégios de criação cluster como uma prática recomendada de governança de dados. Consulte Modos de acesso.
Credenciais e infraestrutura seguras do Unity Catalog
Unity Catalog gerenciar o acesso ao armazenamento de objetos cloud, compartilhamento de dados e federação de consultas usando objetos seguros registrados no nível do metastore. A seguir, uma breve descrição desses objetos não protegíveis por dados.
Conexão do Unity Catalog ao armazenamento de objetos na nuvem
O senhor deve definir credenciais de armazenamento e locais externos para criar um novo local de armazenamento gerenciar ou para registrar tabelas ou volumes externos. Esses objetos securizáveis são registrados no Unity Catalog:
Credencial de armazenamento: Uma credencial cloud de longo prazo que fornece acesso ao armazenamento cloud.
Localização externa: Uma referência a um caminho de armazenamento de objetos cloud acessível usando a credencial de armazenamento emparelhado.
Consulte Conectar-se ao armazenamento de objetos cloud usando Unity Catalog.
Delta Sharing
Databricks registre os seguintes objetos seguros em Delta Sharing em Unity Catalog:
Compartilhar: Uma coleção somente de leitura de tabelas, volumes e outros dados ativos.
Provedor: A organização ou entidade que compartilha dados. No modelo de compartilhamento Databricks-to-Databricks, o provedor é registrado no metastore do Unity Catalog do destinatário como uma entidade exclusiva identificada por seu ID de metastore.
Destinatário: A entidade que recebe ações de um provedor. No modelo de compartilhamento Databricks-to-Databricks, o destinatário é identificado para o provedor pelo seu ID de metastore exclusivo.
Veja Compartilhar dados e IA ativo com segurança usando Delta Sharing.
Federação de Lakehouse
lakehouse A federação permite que o senhor crie catálogos externos para fornecer acesso somente leitura aos dados que residem em outros sistemas, como PostgreSQL, MySQL e Snowflake. O senhor deve definir uma conexão com o sistema externo para criar catálogos externos.
Conexão: Um objeto securizável Unity Catalog especifica um caminho e credenciais para acessar um sistema de banco de dados externo em um cenário de Federação lakehouse.
gerenciar locais de armazenamento para volumes e tabelas gerenciar
Ao criar tabelas e volumes Databricks, o senhor tem a opção de gerenciá-los ou torná-los externos. Unity Catalog gerenciar o acesso a tabelas e volumes externos do site Databricks, mas não controla os arquivos subjacentes nem gerencia totalmente o local de armazenamento desses arquivos. As tabelas e volumes gerenciados, por outro lado, são totalmente gerenciados pelo site Unity Catalog e armazenados em um local de armazenamento gerenciado associado ao esquema que os contém. Consulte Especificar um local de armazenamento gerenciar em Unity Catalog.
Databricks recomenda gerenciar volumes e gerenciar tabelas para a maioria das cargas de trabalho, porque eles simplificam a configuração, a otimização e a governança.
Unity Catalog vs. legado Hive metastore
Databricks recomenda o uso do site Unity Catalog para registrar e controlar todos os objetos do banco de dados, mas também oferece suporte legado ao site Hive metastore para gerenciar esquemas, tabelas, visualizações e funções.
Se o senhor estiver interagindo com objetos de banco de dados registrados usando Hive metastore, consulte Objetos de banco de dados no site legado Hive metastore.