Databricks Connect for Python
Note
This article covers Databricks Connect for Databricks Runtime 13.3 LTS and above.
This article demonstrates how to quickly get started with Databricks Connect by using Python and PyCharm.
For the R version of this article, see Databricks Connect for R.
For the Scala version of this article, see Databricks Connect for Scala.
Databricks Connect enables you to connect popular IDEs such as PyCharm, notebook servers, and other custom applications to Databricks clusters. See What is Databricks Connect?.
Tutorial
To skip this tutorial and use a different IDE instead, see Next steps.
Requirements
To complete this tutorial, you must meet the following requirements:
Your target Databricks workspace must have Unity Catalog enabled.
You have PyCharm installed. This tutorial was tested with PyCharm Community Edition 2023.3.5. If you use a different version or edition of PyCharm, the following instructions might vary.
Your compute meets the Databricks Connect for Python installation requirements.
If you are using classic compute, you will need the cluster’s ID. To get your cluster ID, in your workspace, click Compute on the sidebar, and then click your cluster’s name. In your web browser’s address bar, copy the string of characters between
clustersandconfigurationin the URL.
Step 1: Configure Databricks authentication
This tutorial uses Databricks OAuth user-to-machine (U2M) authentication and a Databricks configuration profile for authenticating to your Databricks workspace. To use a different authentication type, see Configure connection properties.
Configuring OAuth U2M authentication requires the Databricks CLI. For information about installing the Databricks CLI, see Install or update the Databricks CLI.
Initiate OAuth U2M authentication, as follows:
Use the Databricks CLI to initiate OAuth token management locally by running the following command for each target workspace.
In the following command, replace
<workspace-url>with your Databricks workspace instance URL, for examplehttps://1234567890123456.7.gcp.databricks.com.databricks auth login --configure-cluster --host <workspace-url>
Tip
To use serverless compute with Databricks Connect, see Configure a connection to serverless compute.
The Databricks CLI prompts you to save the information that you entered as a Databricks configuration profile. Press
Enterto accept the suggested profile name, or enter the name of a new or existing profile. Any existing profile with the same name is overwritten with the information that you entered. You can use profiles to quickly switch your authentication context across multiple workspaces.To get a list of any existing profiles, in a separate terminal or command prompt, use the Databricks CLI to run the command
databricks auth profiles. To view a specific profile’s existing settings, run the commanddatabricks auth env --profile <profile-name>.In your web browser, complete the on-screen instructions to log in to your Databricks workspace.
In the list of available clusters that appears in your terminal or command prompt, use your up arrow and down arrow keys to select the target Databricks cluster in your workspace, and then press
Enter. You can also type any part of the cluster’s display name to filter the list of available clusters.To view a profile’s current OAuth token value and the token’s upcoming expiration timestamp, run one of the following commands:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
If you have multiple profiles with the same
--hostvalue, you might need to specify the--hostand-poptions together to help the Databricks CLI find the correct matching OAuth token information.
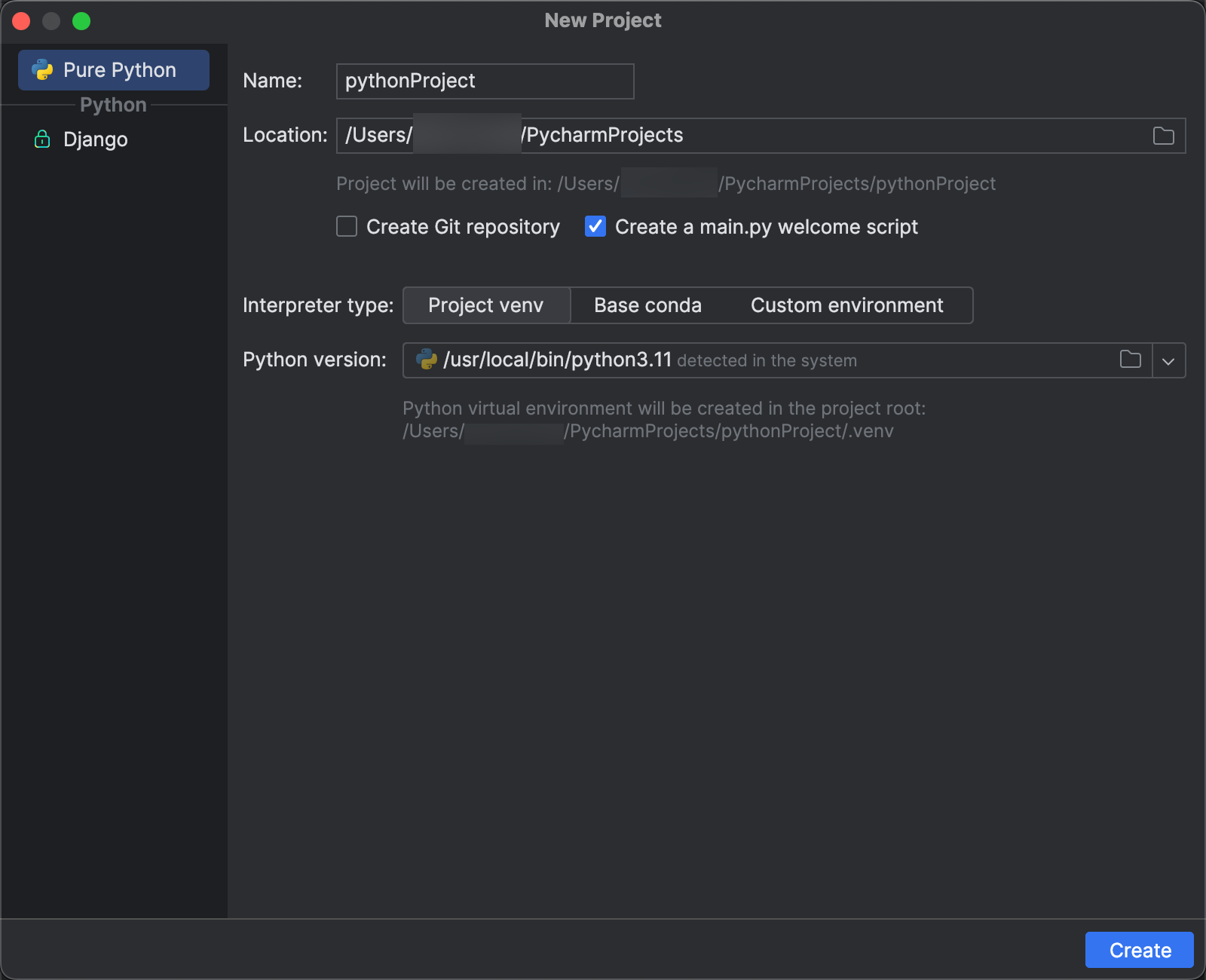
Step 2: Create the project
Start PyCharm.
On the main menu, click File > New Project.
In the New Project dialog, click Pure Python.
For Location, click the folder icon, and complete the on-screen directions to specify the path to your new Python project.
Leave Create a main.py welcome script selected.
For Interpreter type, click Project venv.
Expand Python version, and use the folder icon or drop-down list to specify the path to the Python interpreter from the preceding requirements.
Click Create.
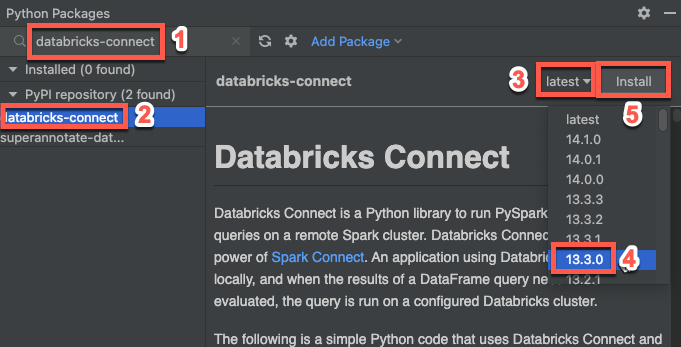
Step 3: Add the Databricks Connect package
On PyCharm’s main menu, click View > Tool Windows > Python Packages.
In the search box, enter
databricks-connect.In the PyPI repository list, click databricks-connect.
In the result pane’s latest drop-down list, select the version that matches your cluster’s Databricks Runtime version. For example, if your cluster has Databricks Runtime 14.3 installed, select 14.3.1.
Click Install package.
After the package installs, you can close the Python Packages window.
Step 4: Add code
In the Project tool window, right-click the project’s root folder, and click New > Python File.
Enter
main.pyand double-click Python file.Enter the following code into the file and then save the file, depending on the name of your configuration profile.
If your configuration profile from Step 1 is named
DEFAULT, enter the following code into the file, and then save the file:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)
If your configuration profile from Step 1 is not named
DEFAULT, enter the following code into the file instead. Replace the placeholder<profile-name>with the name of your configuration profile from Step 1, and then save the file:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.profile("<profile-name>").getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)
Step 5: Run the code
Start the target cluster in your remote Databricks workspace.
After the cluster has started, on the main menu, click Run > Run ‘main’.
In the Run tool window (View > Tool Windows > Run), in the Run tab’s main pane, the first 5 rows of the
samples.nyctaxi.tripsappear.
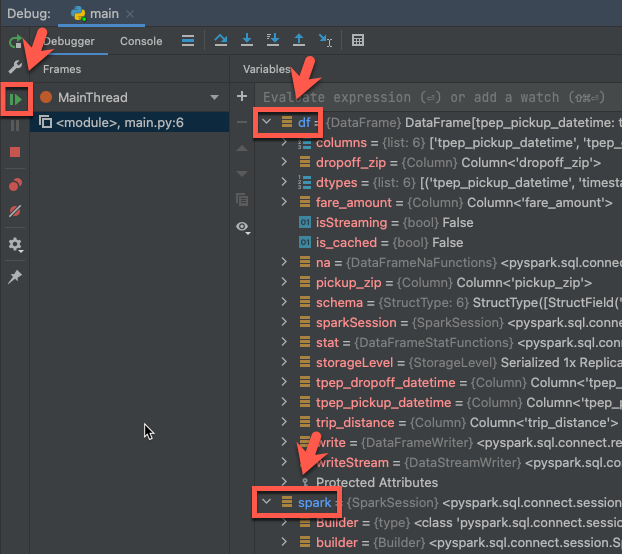
Step 6: Debug the code
With the cluster still running, in the preceding code, click the gutter next to
df.show(5)to set a breakpoint.On the main menu, click Run > Debug ‘main’.
In the Debug tool window (View > Tool Windows > Debug), in the Debugger tab’s Variables pane, expand the df and spark variable nodes to browse information about the code’s
dfandsparkvariables.In the Debug tool window’s sidebar, click the green arrow (Resume Program) icon.
In the Debugger tab’s Console pane, the first 5 rows of the
samples.nyctaxi.tripsappear.
Next steps
To learn more about Databricks Connect, see articles such as the following:
To use a different authentication type, see Configure connection properties.
To use other IDEs, notebook servers, and the Spark shell, see the following:
To view additional simple code examples, see Code examples for Databricks Connect for Python.
To view more complex code examples, see the example applications for Databricks Connect repository in GitHub, specifically:
To use Databricks Utilities with Databricks Connect, see Databricks Utilities with Databricks Connect for Python.
To migrate from Databricks Connect for Databricks Runtime 12.2 LTS and below to Databricks Connect for Databricks Runtime 13.3 LTS and above, see Migrate to Databricks Connect for Python.
See also information about troubleshooting and limitations.