Databricks Connect for Python
注記
この記事では、Databricks Runtime13.3LTLTS以降のDatabricks Connectについて説明します。
この記事では、PythonとPyCharmを使用してDatabricks Connectをすぐに導入する方法を説明します。
この記事のRバージョンについては、「Databricks Connect for R」を参照してください。
この記事のScalaのバージョンについては、「Databricks Connect for Scala」を参照してください。
Databricks Connectを使用することにより、PyCharmなどの一般的なIDE、ノートブックサーバー、その他のカスタムアプリケーションをDatabricksクラスターに接続できます。詳しくは、「Databricks Connectとは」を参照してください。
チュートリアル
このチュートリアルをスキップして別のIDEを使用するには、「 次のステップ」を参照してください。
要件
このチュートリアルを完了するには、以下の条件を満たす必要があります。
対象のDatabricksワークスペースでは、Unity Catalogが有効になっている必要があります。
PyCharmがインストールされていること。このチュートリアルは、PyCharm Community Edition 2023.3.5でテストされました。PyCharmの別のバージョンまたはエディションを使用している場合、手順が以下とは異なる可能性があります。
お使いのコンピュートでDatabricks Connect for Pythonのインストール要件を満たしている必要があります。
クラシックコンピュートを使用している場合は、クラスターのIDが必要です。クラスターIDを取得するには、ワークスペースでサイドバーの [コンピュート] をクリックし、クラスターの名前を選択ます。Webブラウザのアドレスバーに、URLの
clustersからconfigurationまでの文字列をコピーします。
ステップ 1:Databricks 認証を構成する
このチュートリアルでは、Databricks OAuth ユーザー対マシン (U2M) 認証とDatabricks構成プロファイルを使用して、Databricksワークスペースへの認証を行います。別の認証方法を使用する場合は、「接続プロパティを構成する」を参照してください。
OAuth U2M 認証を構成するには、Databricks CLI が必要です。 Databricks CLIのインストールに関する情報については、「Databricks CLIのインストールまたは更新」を参照してください。
次のように、OAuth U2M認証を開始します。
Databricks CLIを使用して、ターゲットワークスペースごとに以下のコマンドを実行し、ローカルでOAuthトークン管理を開始します。
次のコマンドで、
<workspace-url>をDatabricksワークスペース インスタンスの URLに置き換えます(例:https://1234567890123456.7.gcp.databricks.com)。databricks auth login --configure-cluster --host <workspace-url>
ヒント
サーバレス コンピュートを Databricks Connectとともに使用するには、 サーバレス コンピュートへの接続の設定を参照してください。
Databricks CLIは、入力した情報をDatabricks構成プロファイルとして保存するよう促します。
Enterを押して提案されたプロファイル名を受け入れるか、新規または既存のプロファイルの名前を入力してください。同じ名前の既存のプロファイルは、入力した情報で上書きされます。プロファイルを使用すると、複数のワークスペース間で認証コンテキストをすばやく切り替えることができます。既存のプロファイルのリストを取得するには、別のターミナルまたはコマンドプロンプトでDatabricks CLIを使用してコマンド
databricks auth profilesを実行します。特定のプロファイルの既存の設定を表示するには、コマンドdatabricks auth env --profile <profile-name>を実行します。Webブラウザで、画面の指示に従ってDatabricksワークスペースにログインします。
ターミナルまたはコマンドプロンプトに表示される利用可能なクラスターのリストで、上矢印キーと下矢印キーを使用してワークスペース内の対象のDatabricksクラスターを選択し、
Enterを押します。クラスターの表示名の一部を入力して、利用可能なクラスターのリストを絞り込むこともできます。プロファイルの現在のOAuthトークンの値と、トークンの有効期限を表示するには、次のいずれかのコマンドを実行します。
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
同じ
--host値を持つプロファイルが複数ある場合、Databricks CLIが正しいOAuthトークン情報を見つけられるように--hostと-pオプションを一緒に指定する必要がある場合があります。
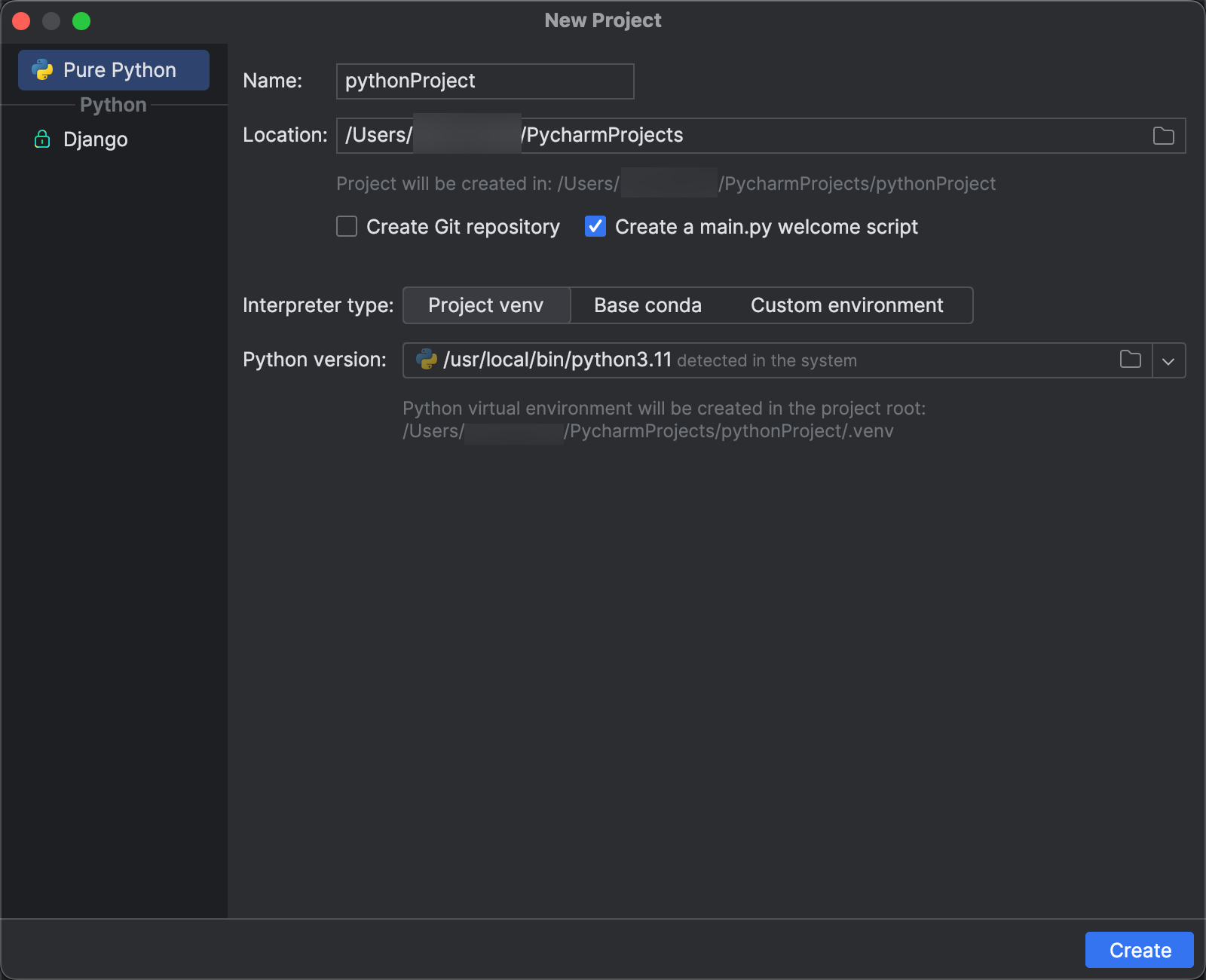
ステップ2:プロジェクトを作成する
PyCharmを起動します。
メインメニューで、[ファイル] > [新しいプロジェクト] をクリックします。
[新しいプロジェクト] ダイアログで、[Pure Python] をクリックします。
[場所] には、フォルダーアイコンをクリックし、画面上の指示に従って新しいPythonプロジェクトへのパスを指定します。
[main.py welcomeスクリプトを作成] は選択したままにしておきます。
[インタープリターのタイプ] では [Project venv] をクリックします。
[Pythonのバージョン] を展開し、フォルダアイコンまたはドロップダウンリストを使用して、前述の要件にあるPythonインタープリターへのパスを指定します。
[作成] をクリックします。
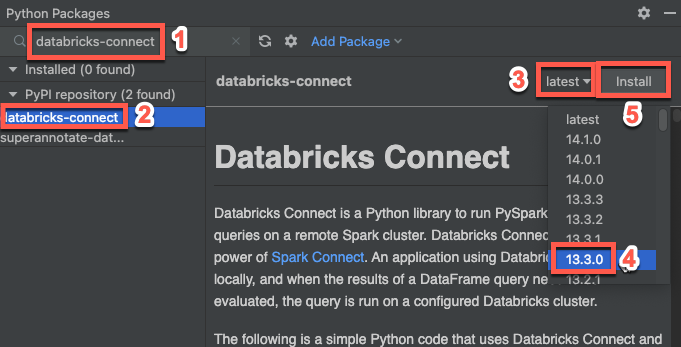
ステップ3:Databricks Connectパッケージを追加する
PyCharmのメインメニューで、 [表示] > [ツールウィンドウ] > [Pythonパッケージ] をクリックします。
検索ボックスに「
databricks-connect」と入力します。[PyPIリポジトリ] のリストから [databricks-connect] をクリックします。
結果ウィンドウの [最新] のドロップダウンリストから、クラスターのDatabricks Runtimeバージョンと一致するバージョンを選択します。たとえば、クラスターにDatabricks Runtime 14.3がインストールされている場合は、[14.3.1]を選択します。
[パッケージのインストール] をクリックします。
パッケージがインストールされたら、[Pythonパッケージ] のウィンドウを閉じてかまいません。
ステップ4:コードを追加する
[プロジェクト] ツールウィンドウでプロジェクトのルートフォルダーを右クリックし、 [新規] > [Pythonファイル]をクリックします。
main.pyと入力し、 [Pythonファイル] をダブルクリックします。構成プロファイルの名前に応じて、以下のコードをファイルに入力し、ファイルを保存します。
ステップ1の構成プロファイルが
DEFAULTという名前である場合は、次のコードをファイルに入力して、ファイルを保存します。from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)
ステップ1の構成プロファイルが
DEFAULTという名前でない場合は、代わりに次のコードをファイルに入力します。プレースホルダー<profile-name>をステップ1で作成した構成プロファイルの名前に置き換えて、ファイルを保存します。from databricks.connect import DatabricksSession spark = DatabricksSession.builder.profile("<profile-name>").getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)
ステップ 5:コードを実行する
リモートのDatabricksワークスペースでターゲット・クラスターを開始します。
クラスターが起動したら、メインメニューで [実行] > [‘main’ を実行] をクリックします。
[実行] ツールウィンドウ([表示] > [ツールウィンドウ] > [実行])にある [実行] タブの [メイン] ペインに、
samples.nyctaxi.tripsの最初の5行が表示されます。
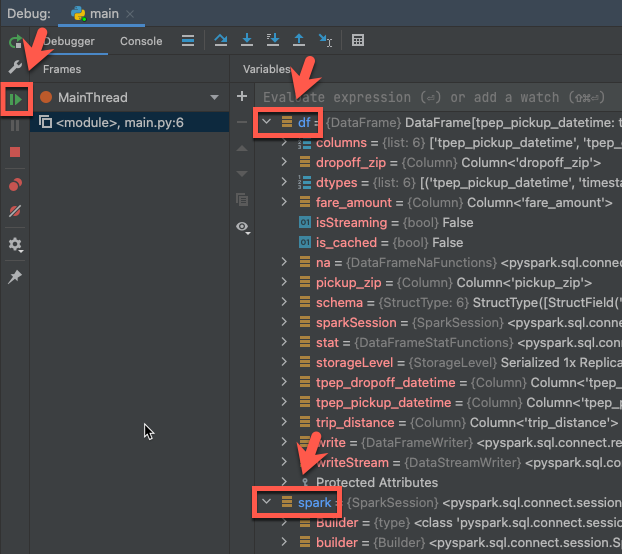
ステップ 6:コードをデバッグする
クラスターが実行されている状態で、前のコードで、
df.show(5)の横のガターをクリックしてブレークポイントを設定します。メインメニューで、[実行] > [‘main’ をデバッグ] をクリックします。
[デバッグ] ツールウィンドウ([ビュー] > [ツールウィンドウ] > [デバッグ])の [デバッガー] タブの [変数] ペインで df 変数と spark 変数ノードを展開し、コードの
df変数とspark変数の情報を参照します。[デバッグ] ツールウィンドウのサイドバーで、緑色の矢印([プログラムの再開])アイコンをクリックします。
[デバッガー] タブの [コンソール] ペインに、
samples.nyctaxi.tripsの最初の5行が表示されます。
次のステップ
Databricks Connectの詳細については、以下の記事を参照してください。
別の認証方法を使用する場合は、「接続プロパティを構成する」を参照してください。
他のIDEやノートブックサーバー、Sparkシェルを使用する場合は、以下を参照してください。
その他の簡単なコードの例については、「Databricks Connect for Python のコード例」を参照してください。
複雑なコードの例については、GitHubのサイトにあるDatabricks Connectのアプリケーション例を参照してください。具体的には以下のとおりです。
Databricks ConnectでDatabricksユーティリティを使用する場合は、「Databricks Connect for PythonでDatabricksユーティリティを使用する」を参照してください。
Databricks Connect for Databricks Runtime 12.2 LTS以前からDatabricks Connect for Databricks Runtime 13.3 LTS以降に移行する場合は、「Databricks Connect for Pythonへの移行」を参照してください。
トラブルシューティングと制限に関する情報も参照してください。