Databricks Connectとは
注
この記事では、Databricks Runtime 13.3 LTS 以降の Databricks Connect について説明します。
Databricks Connect のレガシーバージョンに関する情報については、 Databricks Connect for Databricks Runtime 12.2 LTS 以前を参照してください。
Databricks Connect は次の言語で利用できます。
概要
Databricks ConnectIDEsVisual Studio Code、PyCharm 、RStudio Desktop、 、データベースIntelliJ IDEA サーバーなどの一般的な やその他のカスタム アプリケーションをDatabricks コンピュートに接続できます。この記事では、Databricks Connect の仕組みについて説明します。
注
Visual Studio Code の Databricks 拡張機能には Databricks Connect が含まれているため、Visual Studio Code の Databricks 拡張機能をインストールしている場合は、Databricks Connect をインストールする必要はありません。 Visual Studio Code の Databricks 拡張機能については、「Databricks Connect を使用したコードのデバッグ」を参照してください。
Databricks Connect は、Databricks Runtime のクライアント ライブラリです。 これにより、 を使用してコードを記述し、ローカルのSparkAPIs DatabricksSparkセッションではなく、 コンピュート経由でリモートで実行できるようになります。
たとえば、DataFrame を使用して コマンドspark.read.format(...).load(...).groupBy(...).agg(...).show() Databricks Connectを実行すると、コマンドの論理表現が で実行されているSpark Databricksサーバーに送信され、リモート コンピュート上で実行されます。
Databricks Connectを使用すると、次のことができます。
任意の Python、R、または Scala アプリケーションから大規模な Spark コードを実行します。 Python、
library(sparklyr)for R、import org.apache.sparkfor Scala をimport pysparkできる場所であればどこでも、IDE プラグインをインストールしたり、Spark サブミッション スクリプトを使用したりすることなく、アプリケーションから直接 Spark コードを実行できるようになりました。注
Databricks Connect for Databricks Runtime 13.3 LTS 以降では、Python アプリケーションの実行がサポートされています。 R と Scala は、Databricks Runtime 13.3 LTS 以降の Databricks Connect でのみサポートされます。
リモートクラスターを使用している場合でも、IDE でコードをステップ実行してデバッグします。
ライブラリを開発するときは、素早く反復します。各クライアント セッションはクラスター内で互いに分離されているため、Databricks Connect で Python または Scala ライブラリの依存関係を変更した後、クラスターを再起動する必要はありません。
作業を失うことなくアイドル状態のクラスターをシャットダウンします。 クライアント アプリケーションはクラスターから切り離されているため、クラスターの再起動やアップグレードの影響を受けず、通常はノートブックで定義されているすべての変数、RDD、および DataFrame オブジェクトが失われます。
Databricks Runtime 13.3 LTS 以降では、Databricks Connect はオープンソースの Spark Connect 上に構築されるようになりました。 Spark Connect は、DataFrame API と未解決の論理プランをプロトコルとして使用して Spark クラスターへのリモート接続を可能にする、Apache Spark 用の分離されたクライアント サーバー アーキテクチャを導入します。 Spark Connect に基づくこの新しいアーキテクチャにより、Databricks Connect はシンプルで使いやすいシン クライアントになります。 SparkConnectDatabricks は、IDEs 、データベース、アプリケーションなど、あらゆる場所に埋め込んで に接続できるため、個々のユーザーやパートナーが プラットフォームに基づいて新しい (インタラクティブな) ユーザーDatabricks エクスペリエンスを構築できます。Spark Connect の詳細については、 Spark Connect の紹介」を参照してください。
Databricks Connect は、次の図に示すように、コードの実行とデバッグの場所を決定します。
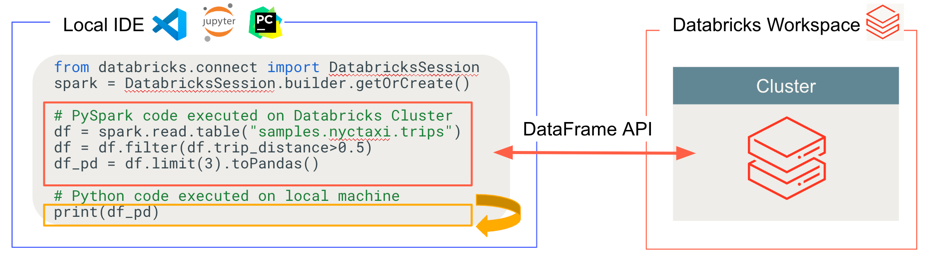
コードを実行する場合: すべてのコードはローカルで実行されますが、DataFrame 操作に関連するすべてのコードはリモート Databricks ワークスペースのクラスターで実行され、実行応答はローカルの呼び出し元に返されます。
コードをデバッグする場合: すべてのコードはローカルでデバッグされますが、すべての Spark コードはリモート Databricks ワークスペースのクラスターで引き続き実行されます。コア Spark エンジンコードをクライアントから直接デバッグすることはできません。
次のステップ
Python を使用して Databricks Connect ソリューションの開発を開始するには、 Databricks Connect for Python チュートリアルから開始します。
R を使用して Databricks Connect ソリューションの開発を開始するには、 Databricks Connect for R のチュートリアルから開始します。
Scala を使用して Databricks Connect ソリューションの開発を開始するには、 Databricks Connect for Scala チュートリアルから開始します。