O que é o Databricks Connect?
Observação
Este artigo abrange Databricks Connect para Databricks Runtime 13.3 LTS e acima.
Para obter informações sobre a versão herdada do Databricks Connect, consulte Databricks Connect para Databricks Runtime 12.2 LTS e abaixo.
O Databricks Connect está disponível para os seguintes idiomas:
Visão geral
Databricks Connect permite que o senhor conecte o popular IDEs, como o Visual Studio Code, PyCharm, RStudio Desktop, IntelliJ IDEA, Notebook servers e outros aplicativos personalizados ao Databricks compute. Este artigo explica como funciona o site Databricks Connect.
Observação
A extensão Databricks para Visual Studio Code inclui o Databricks Connect, portanto o senhor não precisa instalar o Databricks Connect se tiver instalado a extensão Databricks para Visual Studio Code. Consulte Depurar código usando o Databricks Connect para a extensão Databricks para Visual Studio Code.
O Databricks Connect é uma biblioteca cliente para o Databricks Runtime. Ele permite que o senhor escreva códigos usando Spark APIs e os execute remotamente em Databricks compute em vez de na sessão local Spark.
Por exemplo, quando o senhor executa o comando DataFrame spark.read.format(...).load(...).groupBy(...).agg(...).show() usando o site Databricks Connect, a representação lógica do comando é enviada para o servidor Spark em execução no site Databricks para execução no site remoto compute.
Com o Databricks Connect, você pode:
execução de código Spark em grande escala a partir de qualquer aplicativo Python, R ou Scala. Em qualquer lugar onde você possa
import pysparkpara Python,library(sparklyr)para R ouimport org.apache.sparkpara Scala, agora você pode executar o código Spark diretamente do seu aplicativo, sem precisar instalar plug-ins IDE ou usar scripts de envio do Spark.Observação
Databricks Connect para Databricks Runtime 13.3 LTS e acima suportam a execução de aplicativos Python. R e Scala são suportados apenas em Databricks Connect para Databricks Runtime 13.3 LTS e acima.
passo e código de depuração em seu IDE, mesmo ao trabalhar com clusters remotos.
Itere rapidamente ao desenvolver a biblioteca. Não é necessário reiniciar os clusters depois de alterar as dependências da biblioteca Python ou Scala no Databricks Connect, porque cada sessão do cliente está isolada uma da outra nos clusters.
Desligue clusters Parado sem perder trabalho. Como o aplicativo cliente é desacoplado dos clusters, ele não é afetado pelas reinicializações ou atualizações clusters , o que normalmente faria com que você perdesse todas as variáveis, RDDs e objetos DataFrame definidos em um Notebook.
Para Databricks Runtime 13.3 LTS e acima, Databricks Connect agora é construído com base no código aberto Spark Connect. O Spark Connect apresenta uma arquitetura cliente-servidor desacoplada para o Apache Spark que permite a conectividade remota aos clusters do Spark usando a API DataFrame e planos lógicos não resolvidos como protocolo. Com essa nova arquitetura baseada no Spark Connect, o Databricks Connect se torna um thin client simples e fácil de usar. Spark O Connect pode ser incorporado em qualquer lugar para se conectar a Databricks: em IDEs, Notebook e aplicativos, permitindo que usuários individuais e parceiros criem novas experiências de usuário (interativas) com base na plataforma Databricks. Para obter mais informações sobre o Spark Connect, consulte Introducing Spark Connect.
O Databricks Connect determina onde seu código é executado e depurado, conforme mostrado na figura a seguir.
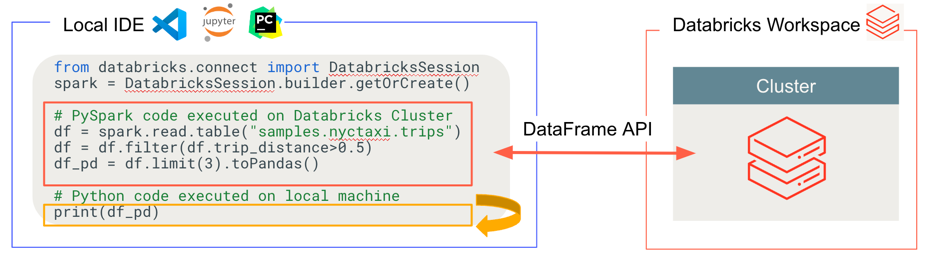
Para execução de código: todo o código é executado localmente, enquanto todo o código que envolve operações DataFrame é executado nos clusters no workspace remoto do Databricks e as respostas de execução são enviadas de volta ao chamador local.
Para depuração de código: todo o código é depurado localmente, enquanto todo o código Spark continua a ser executado nos clusters no workspace remoto do Databricks. O código principal do mecanismo Spark não pode ser depurado diretamente do cliente.
Próximas etapas
Para começar a desenvolver soluções Databricks Connect com Python, comece com o tutorial Databricks Connect for Python .
Para começar a desenvolver soluções Databricks Connect com R, comece com o tutorial Databricks Connect for R.
Para começar a desenvolver soluções Databricks Connect com Scala, comece com o tutorial Databricks Connect for Scala .