What is Databricks Connect?
Note
This article covers Databricks Connect for Databricks Runtime 13.3 LTS and above.
For information about the legacy version of Databricks Connect, see Databricks Connect for Databricks Runtime 12.2 LTS and below.
Databricks Connect is available for the following languages:
Overview
Databricks Connect allows you to connect popular IDEs such as Visual Studio Code, PyCharm, RStudio Desktop, IntelliJ IDEA, notebook servers, and other custom applications to Databricks compute. This article explains how Databricks Connect works.
Note
The Databricks extension for Visual Studio Code includes Databricks Connect, so you do not need to install Databricks Connect if you have installed the Databricks extension for Visual Studio Code. See Debug code using Databricks Connect for the Databricks extension for Visual Studio Code.
Databricks Connect is a client library for the Databricks Runtime. It allows you to write code using Spark APIs and run them remotely a Databricks compute instead of in the local Spark session.
For example, when you run the DataFrame command spark.read.format(...).load(...).groupBy(...).agg(...).show() using Databricks Connect, the logical representation of the command is sent to the Spark server running in Databricks for execution on the remote compute.
With Databricks Connect, you can:
Run large-scale Spark code from any Python, R, or Scala application. Anywhere you can
import pysparkfor Python,library(sparklyr)for R, orimport org.apache.sparkfor Scala, you can now run Spark code directly from your application, without needing to install any IDE plugins or use Spark submission scripts.Note
Databricks Connect for Databricks Runtime 13.3 LTS and above support running Python applications. R and Scala are supported only in Databricks Connect for Databricks Runtime 13.3 LTS and above.
Step through and debug code in your IDE even when working with a remote cluster.
Iterate quickly when developing libraries. You do not need to restart the cluster after changing Python or Scala library dependencies in Databricks Connect, because each client session is isolated from each other in the cluster.
Shut down idle clusters without losing work. Because the client application is decoupled from the cluster, it is unaffected by cluster restarts or upgrades, which would normally cause you to lose all the variables, RDDs, and DataFrame objects defined in a notebook.
For Databricks Runtime 13.3 LTS and above, Databricks Connect is now built on open-source Spark Connect. Spark Connect introduces a decoupled client-server architecture for Apache Spark that allows remote connectivity to Spark clusters using the DataFrame API and unresolved logical plans as the protocol. With this new architecture based on Spark Connect, Databricks Connect becomes a thin client that is simple and easy to use. Spark Connect can be embedded everywhere to connect to Databricks: in IDEs, notebooks, and applications, allowing individual users and partners alike to build new (interactive) user experiences based on the Databricks platform. For more information about Spark Connect, see Introducing Spark Connect.
Databricks Connect determines where your code runs and debugs, as shown in the following figure.
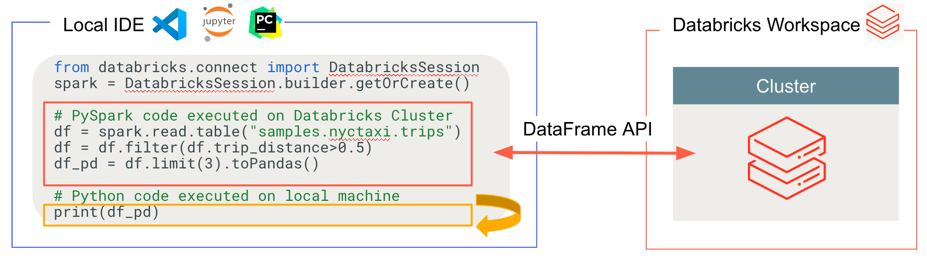
For running code: All code runs locally, while all code involving DataFrame operations runs on the cluster in the remote Databricks workspace and run responses are sent back to the local caller.
For debugging code: All code is debugged locally, while all Spark code continues to run on the cluster in the remote Databricks workspace. The core Spark engine code cannot be debugged directly from the client.
Next steps
To begin developing Databricks Connect solutions with Python, start with the Databricks Connect for Python tutorial.
To begin developing Databricks Connect solutions with R, start with the Databricks Connect for R tutorial.
To begin developing Databricks Connect solutions with Scala, start with the Databricks Connect for Scala tutorial.