Databricks Connect para Scala
Observação
Este artigo aborda o Databricks Connect para Databricks Runtime 13.3 LTS e acima.
Este artigo demonstra como começar rapidamente com o Databricks Connect usando Scala com IntelliJ IDEA e o plugin Scala.
Para a versão Python destes artigos, consulte Databricks Connect for Python.
Para a versão R destes artigos, consulte Databricks Connect for R.
O Databricks Connect permite conectar IDEs populares, como IntelliJ IDEA, servidores Notebook e outros aplicativos personalizados a clusters Databricks. Consulte O que é o Databricks Connect?.
Tutorial
Para pular este tutorial e usar um IDE diferente, consulte Próximos passos.
Requisitos
Para concluir este tutorial, você deve atender aos seguintes requisitos:
Seu destino Databricks workspace e cluster deve atender aos requisitos de configuração de computação para Databricks Connect.
Você deve ter seu ID clusters disponível. Para obter o ID dos seus clusters , no seu workspace, clique em compute na barra lateral e, em seguida, clique no nome dos seus clusters . Na barra de endereço do seu navegador, copie as strings de caracteres entre
clusterseconfigurationno URL.Você tem o Java Development Kit (JDK) instalado em sua máquina de desenvolvimento. A Databricks recomenda que a versão da instalação do JDK usada corresponda à versão do JDK nos clusters do Databricks. A tabela a seguir mostra a versão do JDK para cada Databricks Runtime compatível.
Versão Databricks Runtime
Versão JDK
13,3 LTS - 15,0, 13,3 ML LTS - 15,0 ML
JDK8
16,0
JDK 17
Observação
Se você não tiver um JDK instalado ou se tiver várias instalações do JDK em sua máquina de desenvolvimento, poderá instalar ou escolher um JDK específico posteriormente na etapa 1. Escolhendo uma instalação do JDK que esteja abaixo ou acima da versão do JDK em seus clusters pode produzir resultados inesperados ou seu código pode não ser executado.
O senhor tem o IntelliJ IDEA instalado. Este tutorial foi testado com o IntelliJ IDEA Community Edition 2023.3.6. Se o senhor usar uma versão ou edição diferente do IntelliJ IDEA, as instruções a seguir poderão variar.
Você tem o plugin Scala para IntelliJ IDEA instalado.
o passo 1: Configurar a autenticação do Databricks
Este tutorial usa a Databricks OAuth autenticação user-to-machine (U2M) e um Databricks perfil de configuração para autenticação com o seu Databricks workspace. Para usar um tipo de autenticação diferente, consulte Configurar propriedades de conexão.
Configurar a autenticação OAuth U2M requer a CLI do Databricks, da seguinte forma:
Se ainda não estiver instalado, instale a CLI do Databricks da seguinte maneira:
Use o Homebrew para instalar a CLI do Databricks executando os dois comandos a seguir:
brew tap databricks/tap brew install databricks
Você pode usar winget, Chocolatey ou Windows Subsystem for Linux (WSL) para instalar a CLI do Databricks. Se você não puder usar
winget, Chocolatey ou WSL, ignore este procedimento e use o prompt de comando ou o PowerShell para instalar a CLI do Databricks a partir da origem .Observação
Instalar a CLI do Databricks com Chocolatey é experimental.
Para usar
wingetpara instalar a CLI do Databricks, execute os dois comandos a seguir e reinicie o prompt de comando:winget search databricks winget install Databricks.DatabricksCLI
Para usar o Chocolatey para instalar a CLI do Databricks, execute o seguinte comando:
choco install databricks-cli
Para usar WSL para instalar a CLI do Databricks:
Instale
curlezippor meio do WSL. Para mais informações, consulte a documentação do seu sistema operacional.Use WSL para instalar a CLI do Databricks executando o seguinte comando:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
Confirme se a CLI do Databricks está instalada executando o comando a seguir, que exibe a versão atual da CLI do Databricks instalada. Esta versão deve ser 0.205.0 ou acima:
databricks -vObservação
Se você executar
databricksmas obtiver um erro comocommand not found: databricks, ou se executardatabricks -ve um número de versão 0,18 ou abaixo estiver listado, isso significa que sua máquina não consegue encontrar a versão correta do executável da CLI do Databricks. Para corrigir isso, consulte Verifique a instalação da CLI.
Inicie a autenticação OAuth U2M da seguinte forma:
Use a CLI do Databricks para iniciar o gerenciamento tokens OAuth localmente executando o comando a seguir para cada workspace de destino.
No comando a seguir, substitua
<workspace-url>pela URL da instância do espaço de trabalho do Databricks, por exemplohttps://1234567890123456.7.gcp.databricks.com.databricks auth login --configure-cluster --host <workspace-url>
O site Databricks CLI solicita que o senhor salve as informações inseridas como um Databricks perfil de configuração. Pressione
Enterpara aceitar o nome de perfil sugerido ou insira o nome de um perfil novo ou existente. Qualquer perfil existente com o mesmo nome é substituído pelas informações que o senhor inseriu. O senhor pode usar perfis para alternar rapidamente o contexto de autenticação em vários espaços de trabalho.Para obter uma lista de quaisquer perfis existentes, em um terminal ou prompt de comando separado, use a CLI do Databricks para executar o comando
databricks auth profiles. Para view as configurações existentes de um perfil específico, execute o comandodatabricks auth env --profile <profile-name>.No navegador da Web, siga as instruções na tela para log in no workspace do Databricks.
Na lista de clusters disponíveis que aparece em seu terminal ou prompt de comando, use as key seta para cima e seta para baixo para selecionar o cluster do Databricks de destino em seu workspace e pressione
Enter. Você também pode digitar qualquer parte do nome de exibição do cluster para filtrar a lista de clusters disponíveis.Para view o valor atual tokens OAuth de um perfil e o carimbo de data/hora de expiração futura dos tokens , execute um dos seguintes comandos:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Se você tiver vários perfis com o mesmo valor
--host, talvez seja necessário especificar as opções--hoste-pjuntas para ajudar a CLI do Databricks a encontrar as informações tokens OAuth correspondentes corretas.
o passo 2: Crie o projeto
começar IntelliJ IDEA.
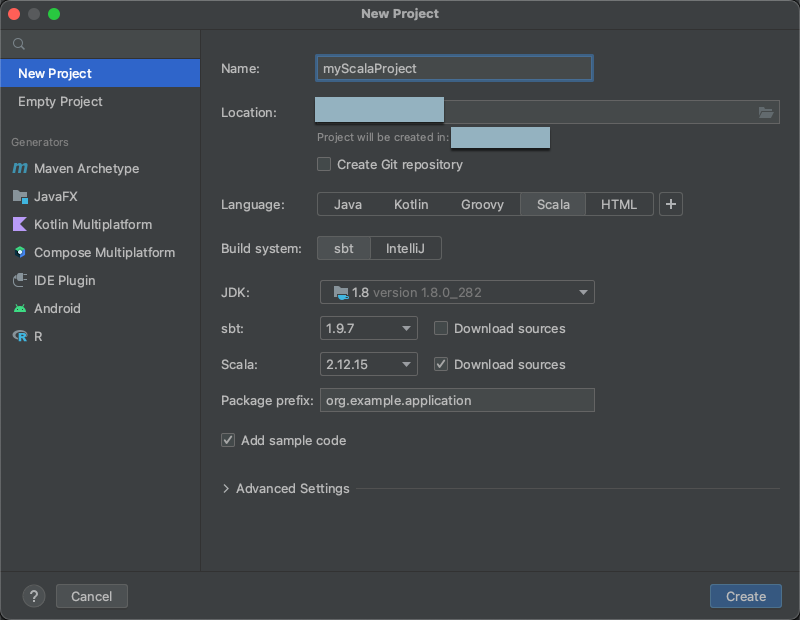
No menu principal, clique em Arquivo > Novo > Projeto.
Dê ao seu projeto um nome significativo.
Para Location, clique no ícone da pasta e siga as instruções na tela para especificar o caminho para seu novo projeto Scala.
Para Idioma, clique em Scala.
Para Sistema de compilação, clique em sbt.
Na lista suspensa JDK , selecione uma instalação existente do JDK em sua máquina de desenvolvimento que corresponda à versão do JDK em seus clusters ou selecione downloads do JDK e siga as instruções na tela para downloads de um JDK que corresponda à versão do JDK em seu cluster. clusters.
Observação
Escolher uma instalação do JDK superior ouabaixo à versão do JDK em seus clusters pode produzir resultados inesperados ou seu código pode não ser executado.
Na lista suspensa sbt , selecione a versão mais recente.
Na lista suspensa Scala , selecione a versão do Scala que corresponde à versão do Scala em seus clusters. A tabela a seguir mostra a versão Scala para cada Databricks Runtime compatível:
Versão Databricks Runtime
Versão Scala
13,3 LTS - 15,0, 13,3 ML LTS - 15,0 ML
2.12.15
Observação
Escolher uma versão do Scala abaixo ou acima da versão do Scala em seus clusters pode produzir resultados inesperados ou seu código pode não ser executado.
Certifique-se de que a caixa de fontesdownloads ao lado de Scala esteja marcada.
Para Package prefix, insira algum valor de prefixo de pacote para as fontes do seu projeto, por exemplo
org.example.application.Certifique-se de que a caixa Adicionar código de amostra esteja marcada.
Clique em Criar.
o passo 3: Adicionar o pacote Databricks Connect
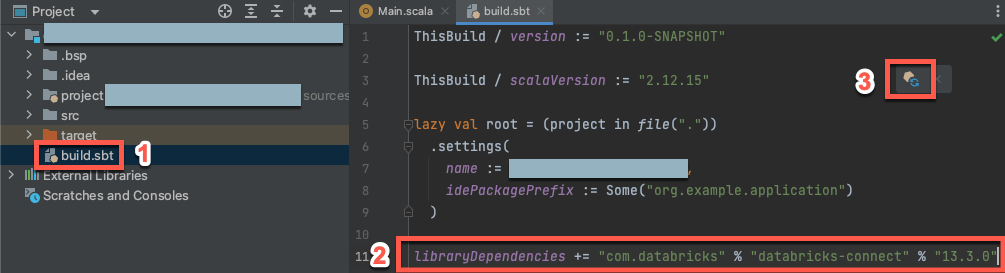
Com seu novo projeto Scala aberto, na janela de ferramentas Project (view > Tool Windows > Project), abra o arquivo chamado
build.sbt, em project-name > target.Adicione o seguinte código ao final do arquivo
build.sbt, que declara a dependência do seu projeto de uma versão específica da biblioteca Databricks Connect para Scala:libraryDependencies += "com.databricks" % "databricks-connect" % "14.3.1"
Substitua
14.3.1pela versão da biblioteca Databricks Connect que corresponde à versão do Databricks Runtime nos seus clusters. Você pode encontrar os números de versão da biblioteca do Databricks Connect no repositório central do Maven.Clique no ícone de notificação Carregar alterações do sbt para atualizar seu projeto Scala com o novo local e dependência da biblioteca.
Aguarde até que o indicador de progresso
sbtna parte inferior do IDE desapareça. O processo de carregamentosbtpode levar alguns minutos para ser concluído.
o passo 4: Adicionar código
Na janela da ferramenta Project , abra o arquivo chamado
Main.scala, em project-name > src > main > Scala.Substitua qualquer código existente no arquivo pelo código a seguir e salve o arquivo, dependendo do nome do seu perfil de configuração.
Se o seu perfil de configuração do passo 1 for denominado
DEFAULT, substitua qualquer código existente no arquivo pelo código a seguir e salve o arquivo:package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
Se o seu perfil de configuração do passo 1 não for denominado
DEFAULT, substitua qualquer código existente no arquivo pelo código a seguir. Substitua o espaço reservado<profile-name>pelo nome do seu perfil de configuração da etapa 1 e salve o arquivo:package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
o passo 5: execução do código
comece os clusters de destino em seu workspace remoto do Databricks.
Após o início dos clusters , no menu principal, clique em execução > execução 'Principal'.
Na janela da ferramenta de execução (view > Tool Windows > execução ), n a Principal tab, aparecem as 5 primeiras linhas d
samples.nyctaxi.tripsa tabela .
o passo 6: Depurar o código
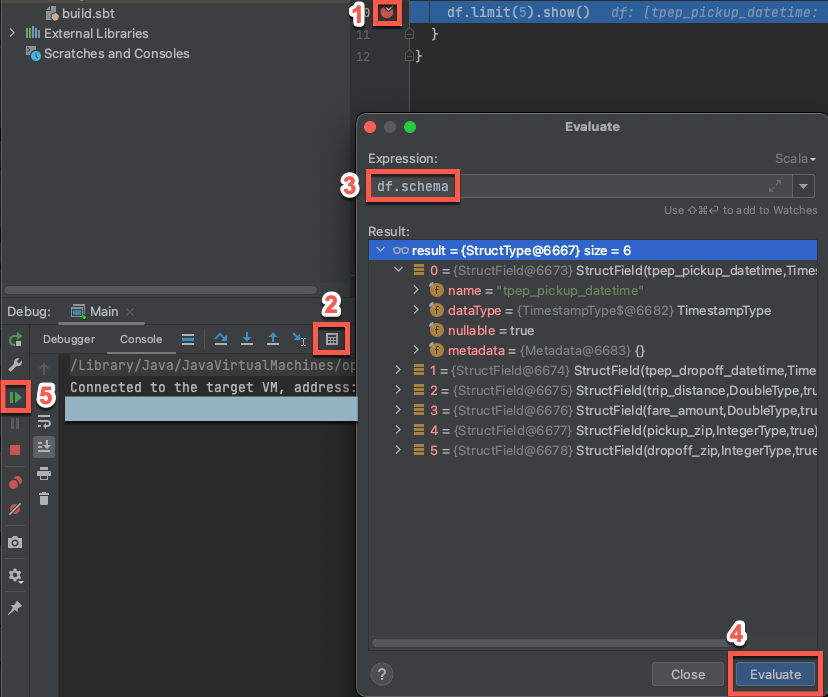
Com os clusters de destino ainda em execução, no código anterior, clique na medianiz ao lado de
df.limit(5).show()para definir um ponto de interrupção.No menu principal, clique em execução > Debug 'Principal'.
Na janela da ferramenta Debug (view > Tool Windows > Debug ), n a Consol tabe , clique no ícone da calculadora ( Avaliar Expressão ).
Insira a expressão
df.schemae clique em Avaliar para mostrar o esquema do DataFrame.Na barra lateral da janela da ferramenta Debug , clique no ícone de seta verde (Resume Program).
No painel Console , as primeiras cinco linhas da tabela
samples.nyctaxi.tripsaparecem.
Próximas etapas
Para saber mais sobre o Databricks Connect, consulte artigos como os seguintes:
Para usar tipos de autenticação do Databricks que não sejam access tokens pessoais do Databricks, consulte Configurar propriedades de conexão.
Para usar outros IDEs, consulte o seguinte:
Para view exemplos de código simples adicionais, consulte Exemplos de código para Databricks Connect for Scala.
Para view exemplos de código mais complexos, consulte os aplicativos de exemplo para repositórios do Databricks Connect no GitHub, especificamente:
Para migrar do Databricks Connect for Databricks Runtime 12.2 LTS e abaixo para o Databricks Connect for Databricks Runtime 13.3 LTS e acima, consulte Migrar para Databricks Connect for Scala.
Consulte também informações sobre solução de problemas e limitações.