Databricks Connect for Scala
注
この記事では、Databricks Connect for Databricks Runtime 13.3 LTS 以降について説明します。
この記事では、 IntelliJ IDEA と Scala プラグインで Scala を使用して、Databricks Connect をすぐに使い始める方法について説明します。
この記事の Python バージョンについては、「 Databricks Connect for Python」を参照してください。
この記事の R バージョンについては、「 Databricks Connect for R」を参照してください。
Databricks Connect を使用すると、IntelliJ IDEA、ノートブック サーバー、その他のカスタム アプリケーションなどの一般的な IDE を Databricks クラスターに接続できます。 「Databricks Connect とは」を参照してください。
チュートリアル
このチュートリアルをスキップして、代わりに別の IDE を使用するには、「 次の手順」を参照してください。
要件
このチュートリアルを完了するには、次の要件を満たす必要があります。
ターゲットDatabricksワークスペースとクラスターは、Databricks Connectのコンピュート構成の要件を満たしている必要があります。
クラスター ID を取得している必要があります。クラスター ID を取得するには、ワークスペースでサイドバーの [ コンピュート ] をクリックし、クラスターの名前をクリックします。 Web ブラウザーのアドレスバーで、URL の
clustersからconfigurationまでの文字列をコピーします。Java 開発キット (JDK) が開発マシンにインストールされていること。 Databricks では、使用する JDK インストールのバージョンを Databricks クラスターの JDK バージョンと一致させることをお勧めします。 次の表に、サポートされている各 Databricks Runtimeの JDK バージョンを示します。
Databricks Runtimeのバージョン
JDK のバージョン
13.3 LTS - 15.0、13.3 ML LTS - 15.0 ML
JDK 8
16.0
JDK 17 の
注
JDK がインストールされていない場合、または開発マシンに複数の JDK がインストールされている場合は、後の手順 1 で特定の JDK をインストールまたは選択できます。クラスター上の JDK バージョンより下または上位の JDK インストールを選択すると、予期しない結果が発生したり、コードがまったく実行されなかったりする可能性があります。
IntelliJ IDEA がインストールされています。 このチュートリアルは、IntelliJ IDEA Community Edition 2023.3.6 でテストされました。 IntelliJ IDEA の異なるバージョンまたはエディションを使用する場合、次の手順は異なる場合があります。
IntelliJ IDEA 用の Scala プラグイン がインストールされています。
ステップ 1: Databricks 認証を構成する
このチュートリアルでは、Databricks OAuth ユーザー対マシン (U2M) 認証と Databricks 構成プロファイル を使用して、Databricks ワークスペースで認証を行います。 代わりに別の認証の種類を使用するには、「 接続プロパティの構成」を参照してください。
OAuth U2M 認証を構成するには、次のように Databricks CLI が必要です。
まだインストールされていない場合は、 次のように Databricks CLI をインストールします。
Homebrew を使用して、次の 2 つのコマンドを実行して Databricks CLI をインストールします。
brew tap databricks/tap brew install databricks
Databricks CLI をインストールするには、 winget、 Chocolatey 、または Windows Subsystem for Linux (WSL) を使用できます。
winget、Chocolatey、または WSL を使用できない場合は、この手順をスキップし、代わりにコマンド プロンプトまたは PowerShell を使用してソースから Databricks CLI をインストールする必要があります。注
Databricks CLI と Chocolatey のインストールは 実験段階です。
wingetを使用して Databricks CLI をインストールするには、次の 2 つのコマンドを実行し、コマンド プロンプトを再起動します。winget search databricks winget install Databricks.DatabricksCLI
Chocolatey を使用して Databricks CLI をインストールするには、次のコマンドを実行します。
choco install databricks-cli
WSL を使用して Databricks CLI をインストールするには、次のようにします。
WSL を使用して
curlとzipをインストールします。 詳細については、オペレーティング システムのマニュアルを参照してください。WSL を使用して、次のコマンドを実行して Databricks CLI をインストールします。
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
次のコマンドを実行して、Databricks CLI がインストールされ、インストールされている Databricks CLI の現在のバージョンが表示されることを確認します。 このバージョンは 0.205.0 以上である必要があります。
databricks -v注
databricksを実行してもcommand not found: databricksなどのエラーが発生した場合、またはdatabricks -vを実行してバージョン番号が 0.18 以下の場合は、マシンで Databricks CLI 実行可能ファイルの正しいバージョンが見つからないことを意味します。これを修正するには、「 CLI のインストールを確認する」を参照してください。
OAuth U2M 認証を次のように開始します。
Databricks CLI を使用して、ターゲット ワークスペースごとに次のコマンドを実行して、OAuth トークン管理をローカルで開始します。
次のコマンドで、
<workspace-url>を Databricks ワークスペース インスタンスの URL に置き換えます (例:https://1234567890123456.7.gcp.databricks.com)。databricks auth login --configure-cluster --host <workspace-url>
Databricks CLIは、入力した情報をDatabricks構成プロファイルとして保存するよう促します。
Enterを押して提案されたプロファイル名を受け入れるか、新規または既存のプロファイルの名前を入力してください。同じ名前の既存のプロファイルは、入力した情報で上書きされます。プロファイルを使用すると、複数のワークスペース間で認証コンテキストをすばやく切り替えることができます。既存のプロファイルの一覧を取得するには、別のターミナルまたはコマンド プロンプトで、Databricks CLI を使用してコマンド
databricks auth profilesを実行します。 特定のプロファイルの既存の設定を表示するには、コマンドdatabricks auth env --profile <profile-name>を実行します。Web ブラウザーで、画面の指示に従って Databricks ワークスペースにログインします。
ターミナルまたはコマンド プロンプトに表示される使用可能なクラスターの一覧で、上方向キーと下方向キーを使用してワークスペース内のターゲット Databricks クラスターを選択し、
Enterを押します。 また、クラスターの表示名の任意の部分を入力して、使用可能なクラスターの一覧をフィルター処理することもできます。プロファイルの現在の OAuth トークン値とトークンの今後の有効期限のタイムスタンプを表示するには、次のいずれかのコマンドを実行します。
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
同じ
--host値を持つプロファイルが複数ある場合は、Databricks CLI で一致する正しい OAuth トークン情報を見つけられるように、--hostオプションと-pオプションを一緒に指定する必要がある場合があります。
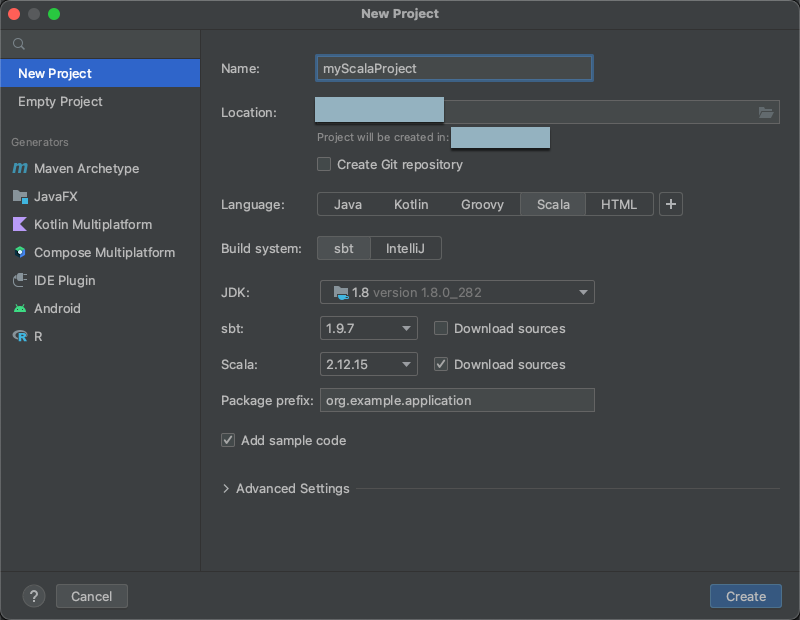
ステップ2:プロジェクトを作成する
IntelliJ IDEAを起動します。
メイン メニューで、[ファイル] > [新しい> プロジェクト] をクリックします。
プロジェクトに意味のある 名前を付けます。
[場所] でフォルダー アイコンをクリックし、画面の指示を完了して、新しい Scala プロジェクトへのパスを指定します。
[言語] で [Scala] をクリックします。
[ビルド システム] で sbt をクリックする。
「JDK」ドロップダウンリストで、クラスターの JDK バージョンと一致する開発マシン上の JDK の既存のインストールを選択するか、「JDK のダウンロード」を選択し、画面の指示に従って、クラスターの JDK バージョンと一致する JDK をダウンロードします。
注
クラスター上の JDK バージョンより上または下の JDK インストールを選択すると、予期しない結果が発生したり、コードがまったく実行されなかったりする可能性があります。
sbt のドロップダウンリストで、最新バージョンを選択する。
[Scala] ドロップダウンリストで、クラスター上の Scala バージョンと一致する Scala のバージョンを選択します。 次の表は、サポートされている各 Databricks Runtimeの Scala バージョンを示しています。
Databricks Runtimeのバージョン
Scala バージョン
13.3 LTS - 15.0、13.3 ML LTS - 15.0 ML
2.12.15
注
クラスターで Scala バージョンより下または上位の Scala バージョンを選択すると、予期しない結果が発生したり、コードがまったく実行されなかったりする可能性があります。
Scalaの横にある[ソースのダウンロード]ボックスがオンになっていることを確認します。
[ パッケージ接頭辞] に、プロジェクトのソースのパッケージ接頭辞の値 (
org.example.applicationなど) を入力します。[ サンプル コードの追加 ] ボックスがオンになっていることを確認します。
「作成」をクリックします。
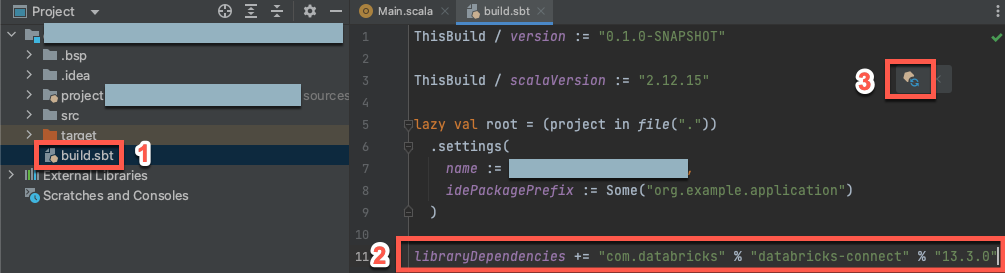
ステップ3:Databricks Connectパッケージを追加する
新しい Scala プロジェクトを開いた状態で、[プロジェクト] ツール ウィンドウ ([ツールウィンドウの表示] > [プロジェクト] > で、プロジェクト名>ターゲットで
build.sbtという名前のファイルを開きます。次のコードを
build.sbtファイルの末尾に追加して、Scala 用 Databricks Connect ライブラリの特定のバージョンに対するプロジェクトの依存関係を宣言します。libraryDependencies += "com.databricks" % "databricks-connect" % "14.3.1"
14.3.1、クラスター上の Databricks Runtime バージョンと一致するバージョンの Databricks Connect ライブラリに置き換えます。 Databricks Connect ライブラリのバージョン番号は、 Maven の中央リポジトリで確認できます。sbt の変更をロードする通知アイコンをクリックして、Scala プロジェクトを新しいライブラリの場所と依存関係で更新する。
IDE の下部にある
sbt進行状況インジケーターが消えるまで待ちます。sbtロード プロセスが完了するまでに数分かかる場合があります。
ステップ4:コードを追加する
プロジェクトツールウィンドウで、 [プロジェクト名] > src > main > scala にある
Main.scalaという名前のファイルを開きます。ファイル内の既存のコードを次のコードに置き換え、構成プロファイルの名前に応じてファイルを保存します。
ステップ 1 の構成プロファイルの名前が
DEFAULTの場合は、ファイル内の既存のコードを次のコードに置き換えて、ファイルを保存します。package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
ステップ 1 の構成プロファイルの名前が
DEFAULTでない場合は、ファイル内の既存のコードを次のコードに置き換えてください。 プレースホルダ<profile-name>をステップ 1 の構成プロファイルの名前に置き換えて、ファイルを保存します。package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
ステップ 5: コードを実行する
リモートのDatabricksワークスペースでターゲット・クラスターを開始します。
クラスターが起動したら、メイン メニューで [ 実行] をクリックし> ['Main' の実行] をクリックします。
[ 実行 ] ツール ウィンドウ ([実行] > [ツール ウィンドウの表示]> [ メイン ] タブに、
samples.nyctaxi.tripsテーブルの最初の 5 行が表示されます。
ステップ 6: コードをデバッグする
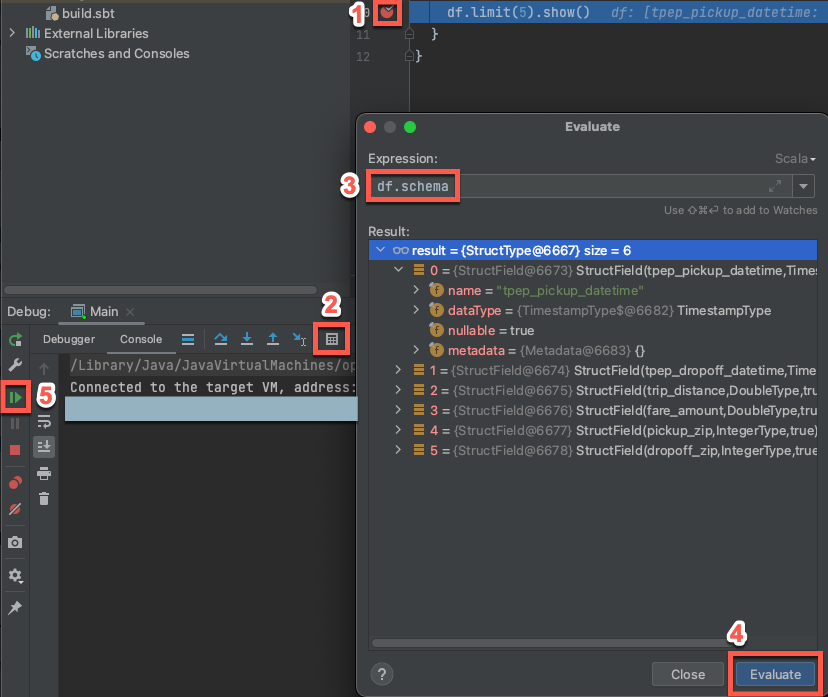
ターゲット クラスターがまだ実行されている状態で、上記のコードで [
df.limit(5).show()] の横にある余白をクリックしてブレークポイントを設定します。メイン メニューで、[実行] > [' Main'] のデバッグをクリックします。
[デバッグ] ツール ウィンドウ ([デバッグ] >> [ツール] ウィンドウの表示) の [コンソール] タブで、電卓 ([式の評価]) アイコンをクリックします。
式
df.schemaを入力し、[ 評価] をクリックして DataFrameのスキーマを表示します。[デバッグ] ツールウィンドウのサイドバーで、緑色の矢印([プログラムの再開])アイコンをクリックします。
[コンソール] ウィンドウに、
samples.nyctaxi.tripsテーブルの最初の 5 行が表示されます。
次のステップ
Databricks Connect の詳細については、次のような記事を参照してください。
Databricks個人用アクセストークン以外のDatabricks認証タイプを使用するには、「接続プロパティを構成する」を参照してください。
他の IDE を使用するには、以下を参照してください。
その他の簡単なコード例については、「 Databricks Connect for Scala のコード例」を参照してください。
より複雑なコード例を表示するには、GitHub の Databricks Connect リポジトリのサンプル アプリケーション を参照してください。
Databricks Connect for Databricks Runtime 12.2 LTS 以下から Databricks Connect for Databricks Runtime 13.3 LTS 以降に移行するには、「 Databricks Connect for Scala への移行」を参照してください。
トラブルシューティングと制限事項に関する情報も参照してください。