ワークスペースオブジェクトの識別子を取得する
この記事では、Databricks でワークスペース、クラスター、ダッシュボード、ディレクトリ、モデル、ノートブック、ジョブの識別子と URL を取得する方法について説明します。
ワークスペースインスタンス名、URL、ID
インスタンス名が、各 Databricks デプロイメントに割り当てられます。ワークロードを分離して関連するユーザのみにアクセスを許可するため、通常 Databricks の顧客は開発、ステージング、本番運用に別々のインスタンスを作成します。インスタンス名は、Databricks デプロイメントにログインする際のURLの冒頭部分です:
この場合、インスタンス名は 8757561887652360.0.gcp.databricks.comです。
Databricks ワークスペースは、Databricks プラットフォームが実行される場所です。ここから Spark クラスターを作成してワークロードをスケジュールできます。ワークスペースの種類によっては、一意のワークスペース ID を持つものがあります。デプロイメント URL に o= がある場合 (例: https://<databricks-instance>/?o=6280049833385130)、 o= の後の乱数が Databricks ワークスペース ID になります。ここでのワークスペース ID は 6280049833385130です。デプロイメント URL に o= がない場合、ワークスペース ID は 0 になります。
クラスターの URL と ID
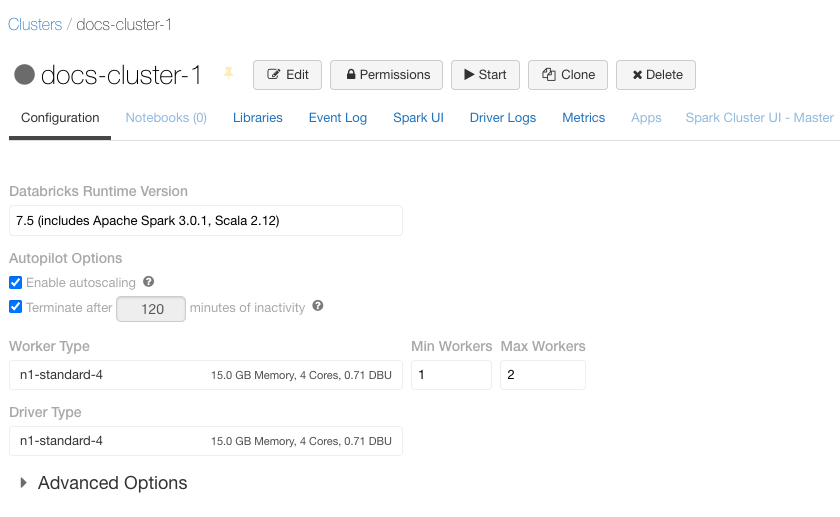
Databricks クラスターは、本番運用 ETL パイプライン、ストリーミング分析、アドホックアナリティクス、機械学習などの様々なユースケースに対応する統合プラットフォームを提供します。各クラスターにはクラスター ID と呼ばれる一意の ID があります。これは、汎用クラスターとジョブクラスターの両方に当てはまります。REST API を使用してクラスターの詳細を取得するには、クラスターID が不可欠です。
クラスター IDを取得するには、サイドバーの [クラスター] タブをクリックし、クラスター名を選択します。クラスター ID は、このページの URL の /clusters/ コンポーネントの後に続く番号です。
https://<databricks-instance>/#/setting/clusters/<cluster-id>
次のスクリーンショットでは、クラスター ID は 0206-231114-irony170です。
ダッシュボードの URL と ID
AI/BI ダッシュボード は、データの視覚化と解説のプレゼンテーションです。 各ダッシュボードには一意の ID があります。 この ID を使用して、プリセットのフィルターとパラメーター値を含む直接リンクを作成したり、REST API を使用してダッシュボードにアクセスしたりできます。
ダッシュボード URL の例:
https://8757561887652360.0.gcp.databricks.com/sql/dashboardsv3/01ef9214fcc7112984a50575bf2b460f
ダッシュボード ID の例:
01ef9214fcc7112984a50575bf2b460f
ノートブックの URL と ID
ノートブック は、実行可能なコード、視覚化、説明テキストを含むドキュメントへの Web ベースのインターフェイスです。複数のノートブックが、Databricks を操作する際の単一のインターフェイスとなります。各ノートブックには一意の ID があります。ノートブック URL にはノートブック ID が含まれるため、ノートブック URL は各ノートブックに固有のものです。ノートブックの閲覧・編集の権限があれば、そのノートブックを Databricks プラットフォーム上で誰とでも共有できます。また、ノートブックのコマンド (セル) ごとに URL は異なります。
ノートブックの URL または ID を見つけるには、ノートブックを開きます。セルの URL を検索するには、コマンドの内容をクリックします。
ノートブックの URL の例:
https://8757561887652360.0.gcp.databricks.com/?o=8757561887652360#notebook/1451020452210597`
ノートブック ID の例:
1451020452210597コマンド (セル) URL の例:
https://8757561887652360.0.gcp.databricks.com/?o=8757561887652360#notebook/1451020452210597/command/1451020452210598
フォルダ ID
フォルダー は、Databricks ワークスペースで使用できるファイルを格納するために使用されるディレクトリです。これらのファイルは、ノートブック、ライブラリ、またはサブフォルダーにすることができます。 各フォルダーと個々のサブフォルダーに関連付けられた特定の ID があります。 アクセス許可 API は、この ID をdirectory_idとして参照し、フォルダーのアクセス許可の設定と更新に使用されます。
directory_id を取得するには、ワークスペース API を使用します。
curl -n -X GET -H 'Content-Type: application/json' -d '{"path": "/Users/me@example.com/MyFolder"}' \
https://<databricks-instance>/api/2.0/workspace/get-status
以下に、API 呼び出し応答の例を示します。
{
"object_type": "DIRECTORY",
"path": "/Users/me@example.com/MyFolder",
"object_id": 123456789012345
}
モデル ID
モデルはMLflow 登録モデルを指します。これにより、ステージの移行とバージョン管理を通じて本番運用で MLflow モデルを管理できるようになります。 登録されたモデル ID は、 Permissions APIを介してプログラムでモデルの権限を変更するために必要です。
登録されているモデルの ID を取得するには、ワークスペース API のエンドポイント mlflow/databricks/registered-models/get を使用します。例えば、次のコードは、登録されたモデルオブジェクトとそのプロパティ (ID を含む) を返します。
curl -n -X GET -H 'Content-Type: application/json' -d '{"name": "model_name"}' \
https://<databricks-instance>/api/2.0/mlflow/databricks/registered-models/get
戻り値の形式は次のとおりです。
{
"registered_model_databricks": {
"name":"model_name",
"id":"ceb0477eba94418e973f170e626f4471"
}
}
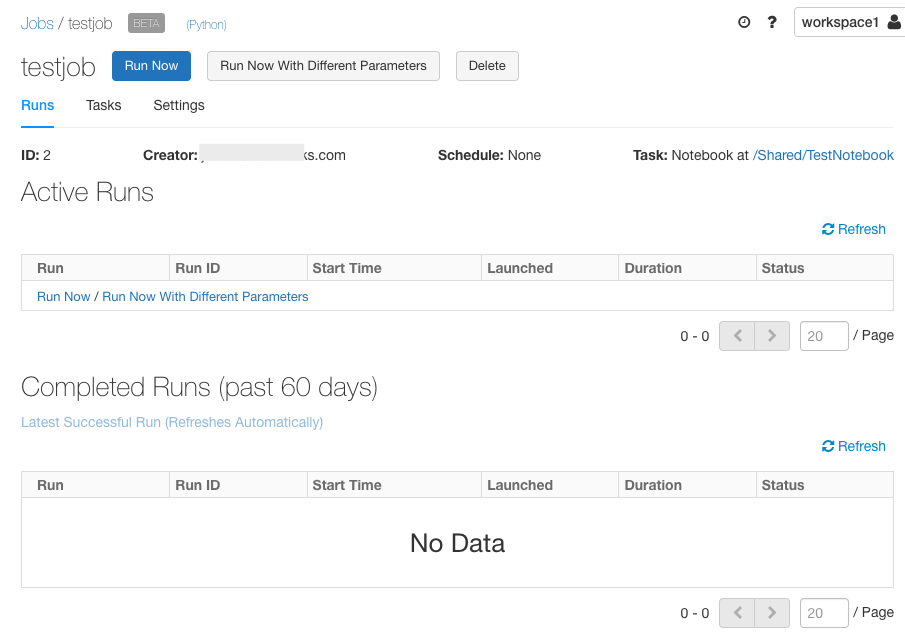
ジョブの URL と ID
ジョブは、ノートブックまたはJARをすぐに、またはスケジュールに基づいて実行する方法です。
ジョブURLを取得するには、![]() サイドバーでジョブ名をクリックします。 ジョブ ID は URL 内のテキスト
サイドバーでジョブ名をクリックします。 ジョブ ID は URL 内のテキスト#job/の後にあります。 失敗したジョブ実行の根本原因をトラブルシューティングするには、ジョブ URL が必要です。
次のスクリーンショットでは、ジョブの URL は
https://8757561887652360.0.gcp.databricks.com/?o=8757561887652360#job/2
この例では、ジョブ ID は 2です。