はじめに:データの拡張とクレンジング
この入門記事では、Databricks ノートブックを使用して、Python、Scala、R を使って Unity Catalog のテーブルに以前読み込まれたニューヨーク州の赤ちゃんの名前データをクレンジングおよび拡張する方法について説明します。この記事では、生データ テーブルから列名を変更し、大文字と小文字を変更し、各赤ちゃんの名前の性別を綴ってから、DataFrame を Silver テーブルに保存します。 次に、2021 年のデータのみが含まれるようにデータをフィルタリングし、州レベルでデータをグループ化して、カウントでデータを並べ替えます。 最後に、この DataFrame をゴールド テーブルに保存し、データを棒グラフで視覚化します。 シルバーテーブルとゴールドテーブルの詳細については、メダリオンアーキテクチャを参照してください。
重要
この概要記事は、概要: 追加データの取り込みと挿入に基づいています。 この記事を完了するには、その記事のステップを完了する必要があります。 入門記事の完全なノートブックについては、 追加データの取り込みノートブックを参照してください。
要件
この記事のタスクを完了するには、次の要件を満たす必要があります。
ワークスペースでUnity Catalog が有効になっている必要があります。 Unity Catalogの使用開始に関する情報については、 Unity Catalogのセットアップと管理を参照してください。
ボリュームに対する
WRITE VOLUME権限、親スキーマに対するUSE SCHEMA権限、および親カタログに対するUSE CATALOG権限が必要です。既存のコンピュート リソースを使用するか、新しいコンピュート リソースを作成するには、アクセス許可が必要です。 Databricks の使用を開始するを参照するか、Databricks 管理者に問い合わせてください。
ヒント
この記事の完成したノートブックについては、 データ ノートブックのクレンジングと拡張を参照してください。
ステップ1:新しいノートブックを作成する
ワークスペースにノートブックを作成するには、サイドバーで ![]() 新規作成をクリックし、ノートブックをクリックします。空白のノートブックがワークスペースで開きます。
新規作成をクリックし、ノートブックをクリックします。空白のノートブックがワークスペースで開きます。
ノートブックの作成と管理の詳細については、ノートブックの管理を参照してください。
ステップ2:変数を定義する
このステップでは、この記事で作成するノートブックの例で使用する変数を定義します。
次のコードをコピーして、新しい空のノートブック セルに貼り付けます。
<catalog-name>、<schema-name>、および<volume-name>を、Unity Catalog ボリュームのカタログ、スキーマ、およびボリューム名に置き換えます。必要に応じて、table_name値を任意のテーブル名に置き換えます。 赤ちゃんの名前のデータは、この記事の後半でこのテーブルに保存します。Shift+Enterを押すとセルが実行され、新しい空白のセルが作成されます。catalog = "<catalog_name>" schema = "<schema_name>" table_name = "baby_names" silver_table_name = "baby_names_prepared" gold_table_name = "top_baby_names_2021" path_table = catalog + "." + schema print(path_table) # Show the complete path
val catalog = "<catalog_name>" val schema = "<schema_name>" val tableName = "baby_names" val silverTableName = "baby_names_prepared" val goldTableName = "top_baby_names_2021" val pathTable = s"${catalog}.${schema}" print(pathTable) // Show the complete path
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" table_name <- "baby_names" silver_table_name <- "baby_names_prepared" gold_table_name <- "top_baby_names_2021" path_table <- paste(catalog, ".", schema, sep = "") print(path_table) # Show the complete path
ステップ3:生データを新しいDataFrameにロードします。
このステップでは、以前に Delta テーブルに保存された生データを新しい DataFrame に読み込み、このデータをクレンジングして強化し、さらに分析できるように準備します。
次のコードをコピーして、新しい空のノートブックのセルに貼り付けてください。
df_raw = spark.read.table(f"{path_table}.{table_name}") display(df_raw)
val dfRaw = spark.read.table(s"${pathTable}.${tableName}") display(dfRaw)
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df_raw = sql(paste0("SELECT * FROM ", path_table, ".", table_name)) display(df_raw)
Shift+Enterを押してセルを実行し、次のセルに移動します。
ステップ4:生データをクレンジングして拡張し、保存する
この手順では、Year 列の名前を変更し、First_Name 列のデータを頭文字の大文字に変更し、Sex 列の値を更新して性別をスペルアウトしてから、 DataFrame を新しいテーブルに保存します。
次のコードをコピーして、ノートブックの空のセルに貼り付けます。
from pyspark.sql.functions import col, initcap, when # Rename "Year" column to "Year_Of_Birth" df_rename_year = df_raw.withColumnRenamed("Year", "Year_Of_Birth") # Change the case of "First_Name" column to initcap df_init_caps = df_rename_year.withColumn("First_Name", initcap(col("First_Name").cast("string"))) # Update column values from "M" to "male" and "F" to "female" df_baby_names_sex = df_init_caps.withColumn( "Sex", when(col("Sex") == "M", "Male") .when(col("Sex") == "F", "Female") ) # display display(df_baby_names_sex) # Save DataFrame to table df_baby_names_sex.write.mode("overwrite").saveAsTable(f"{path_table}.{silver_table_name}")
import org.apache.spark.sql.functions.{col, initcap, when} // Rename "Year" column to "Year_Of_Birth" val dfRenameYear = dfRaw.withColumnRenamed("Year", "Year_Of_Birth") // Change the case of "First_Name" data to initial caps val dfNameInitCaps = dfRenameYear.withColumn("First_Name", initcap(col("First_Name").cast("string"))) // Update column values from "M" to "Male" and "F" to "Female" val dfBabyNamesSex = dfNameInitCaps.withColumn("Sex", when(col("Sex") equalTo "M", "Male") .when(col("Sex") equalTo "F", "Female")) // Display the data display(dfBabyNamesSex) // Save DataFrame to a table dfBabyNamesSex.write.mode("overwrite").saveAsTable(s"${pathTable}.${silverTableName}")
# Rename "Year" column to "Year_Of_Birth" df_rename_year <- withColumnRenamed(df_raw, "Year", "Year_Of_Birth") # Change the case of "First_Name" data to initial caps df_init_caps <- withColumn(df_rename_year, "First_Name", initcap(df_rename_year$First_Name)) # Update column values from "M" to "Male" and "F" to "Female" df_baby_names_sex <- withColumn(df_init_caps, "Sex", ifelse(df_init_caps$Sex == "M", "Male", ifelse(df_init_caps$Sex == "F", "Female", df_init_caps$Sex))) # Display the data display(df_baby_names_sex) # Save DataFrame to a table saveAsTable(df_baby_names_sex, paste(path_table, ".", silver_table_name), mode = "overwrite")
Shift+Enterを押してセルを実行し、次のセルに移動します。
ステップ 5: データをグループ化して視覚化する
このステップでは、データを 2021 年のみにフィルタリングし、性別と名前でデータをグループ化し、カウントで集計し、カウントで並べ替えます。 次に、DataFrame をテーブルに保存し、データを棒グラフで視覚化します。
次のコードをコピーして、ノートブックの空のセルに貼り付けます。
from pyspark.sql.functions import expr, sum, desc from pyspark.sql import Window # Count of names for entire state of New York by sex df_baby_names_2021_grouped=(df_baby_names_sex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count"))) # Display data display(df_baby_names_2021_grouped) # Save DataFrame to a table df_baby_names_2021_grouped.write.mode("overwrite").saveAsTable(f"{path_table}.{gold_table_name}")
import org.apache.spark.sql.functions.{expr, sum, desc} import org.apache.spark.sql.expressions.Window // Count of male and female names for entire state of New York by sex val dfBabyNames2021Grouped = dfBabyNamesSex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count")) // Display data display(dfBabyNames2021Grouped) // Save DataFrame to a table dfBabyNames2021Grouped.write.mode("overwrite").saveAsTable(s"${pathTable}.${goldTableName}")
# Filter to only 2021 data df_baby_names_2021 <- filter(df_baby_names_sex, df_baby_names_sex$Year_Of_Birth == 2021) # Count of names for entire state of New York by sex df_baby_names_grouped <- agg( groupBy(df_baby_names_2021, df_baby_names_2021$Sex, df_baby_names_2021$First_Name), Total_Count = sum(df_baby_names_2021$Count) ) # Display data display(arrange(select(df_baby_names_grouped, df_baby_names_grouped$Sex, df_baby_names_grouped$First_Name, df_baby_names_grouped$Total_Count), desc(df_baby_names_grouped$Total_Count))) # Save DataFrame to a table saveAsTable(df_baby_names_2021_grouped, paste(path_table, ".", gold_table_name), mode = "overwrite")
Ctrl+Enterを押してセルを実行します。テーブル タブの横にある + をクリックし、 ビジュアライゼーションをクリックします。
視覚化エディターで、視覚化の種類をクリックし、 バーが選択されていることを確認します。
X列で、First_Nameを選択します。
Y 列]の下の 列の追加をクリックし、Total_Count を選択します。
グループ化で、 Sexを選択します。
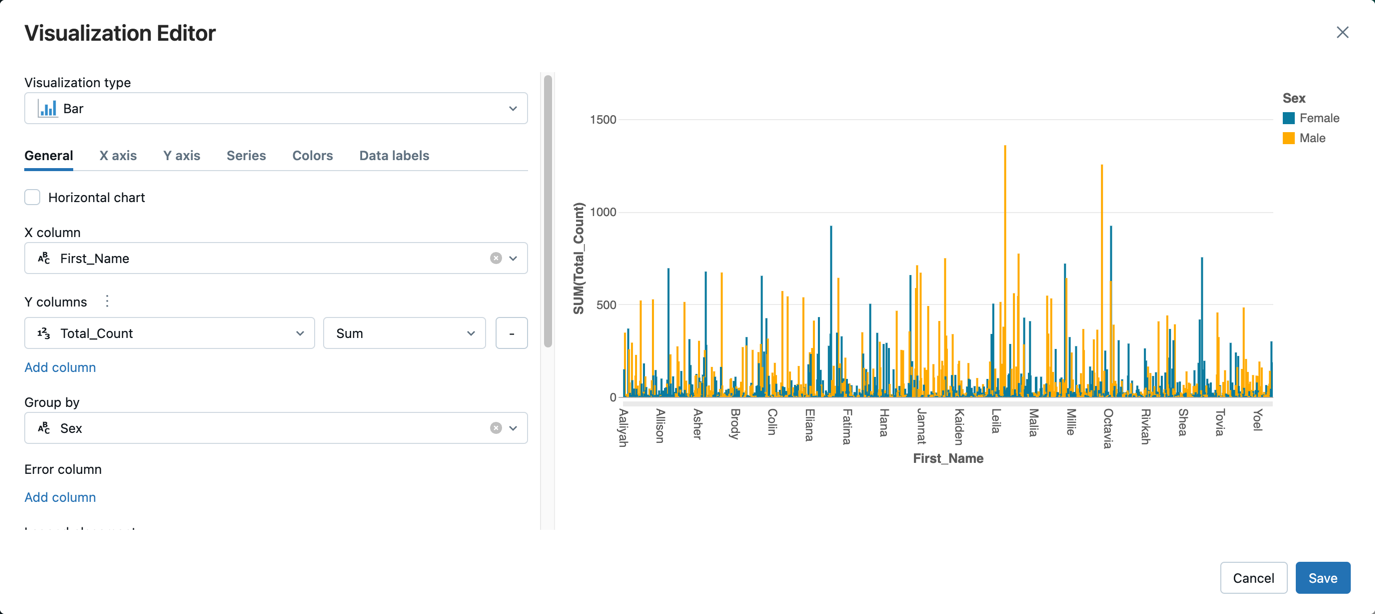
保存をクリックします。