はじめに:ノートブックからCSVデータをインポートして可視化する
この記事では、Databricks ノートブックを使用して、 health.data.ny.govの赤ちゃんの名前データを含む CSV ファイルから、Python、Scala、R を使用して Unity Catalog ボリュームにデータをインポートする方法について説明します。 また、列名の変更、データの視覚化、およびテーブルへの保存についても学習します。
要件
この記事のタスクを完了するには、次の要件を満たす必要があります。
ワークスペースでUnity Catalog が有効になっている必要があります。 Unity Catalogの使用開始に関する情報については、 Unity Catalogのセットアップと管理」を参照してください。
ボリュームに対する
WRITE VOLUME権限、親スキーマに対するUSE SCHEMA権限、および親カタログに対するUSE CATALOG権限が必要です。既存のコンピュート リソースを使用するか、新しいコンピュート リソースを作成するには、アクセス許可が必要です。 「Databricks の使用を開始する」または「Databricks 管理者に問い合わせてください」を参照してください。
ヒント
この記事の完成したノートブックについては、 「データ ノートブックのインポートと視覚化」を参照してください。
ステップ1:新しいノートブックを作成する
ワークスペースにノートブックを作成するには、サイドバーで [![]() 新規作成] をクリックし、[ノートブック] をクリックします。空白のノートブックがワークスペースで開きます。
新規作成] をクリックし、[ノートブック] をクリックします。空白のノートブックがワークスペースで開きます。
ノートブックの作成と管理の詳細については、「ノートブックの管理」を参照してください。
ステップ2:変数を定義する
このステップでは、この記事で作成するノートブックの例で使用する変数を定義します。
次のコードをコピーして、新しい空のノートブック セルに貼り付けます。
<catalog-name>、<schema-name>、および<volume-name>を、Unity Catalog ボリュームのカタログ、スキーマ、およびボリューム名に置き換えます。必要に応じて、table_name値を任意のテーブル名に置き換えます。 赤ちゃんの名前のデータは、この記事の後半でこのテーブルに保存します。Shift+Enterを押すとセルが実行され、新しい空白のセルが作成されます。catalog = "<catalog_name>" schema = "<schema_name>" volume = "<volume_name>" download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name = "baby_names.csv" table_name = "baby_names" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete path
val catalog = "<catalog_name>" val schema = "<schema_name>" val volume = "<volume_name>" val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" val fileName = "baby_names.csv" val tableName = "baby_names" val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}" val pathTable = s"${catalog}.${schema}" print(pathVolume) // Show the complete path print(pathTable) // Show the complete path
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name <- "baby_names.csv" table_name <- "baby_names" path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "") path_table <- paste(catalog, ".", schema, sep = "") print(path_volume) # Show the complete path print(path_table) # Show the complete path
ステップ 3: CSVファイルをインポートする
このステップでは、CSV health.data.ny.gov から赤ちゃんの名前データを含む ファイルをUnity Catalog ボリュームにインポートします。
次のコードをコピーして、新しい空のノートブック セルに貼り付けます。 このコードは 、Databricks dbutils
rows.csvコマンドを使用して、 health.data.ny.gov からUnity Catalog ボリュームに ファイルをコピーします。Shift+Enterを押してセルを実行し、次のセルに移動します。dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
ステップ4:DataFrameにCSVデータを読み込む
このステップでは、spark.read.csvメソッドを使用して、以前にUnity CatalogボリュームにロードしたCSVファイルからdfという名前のDataFrameを作成します。
次のコードをコピーして、新しい空のノートブックセルに貼り付けます。このコードは、CSVファイルからDataFrame「
df」に赤ちゃんの名前データをロードします。Shift+Enterを押してセルを実行し、次のセルに移動します。df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",")
val df = spark.read .option("header", "true") .option("inferSchema", "true") .option("delimiter", ",") .csv(s"${pathVolume}/${fileName}")
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df <- read.df(paste(path_volume, "/", file_name, sep=""), source="csv", header = TRUE, inferSchema = TRUE, delimiter = ",")
サポートされている様々なファイル形式からデータを読み込むことができます。
ステップ5:ノートブックからデータを可視化する
このステップでは、display()メソッドを使用してDataFrameの内容をノートブックのテーブルに表示し、ノートブックのワードクラウドチャートでデータを可視化します。
次のコードをコピーして、新しい空のノートブックのセルに貼り付け、[セルを実行] をクリックしてデータをテーブルに表示します。
display(df)
display(df)
display(df)
テーブルの結果を確認します。
[テーブル] タブの横にある [+] をクリックし、[ビジュアライゼーション] をクリックします。
可視化エディタで、[ビジュアライゼーションの種類] をクリックし、[ワードクラウド] が選択されていることを確認します。
[単語列] で [
First Name] が選択されていることを確認します。[頻度制限] で [
35] をクリックします。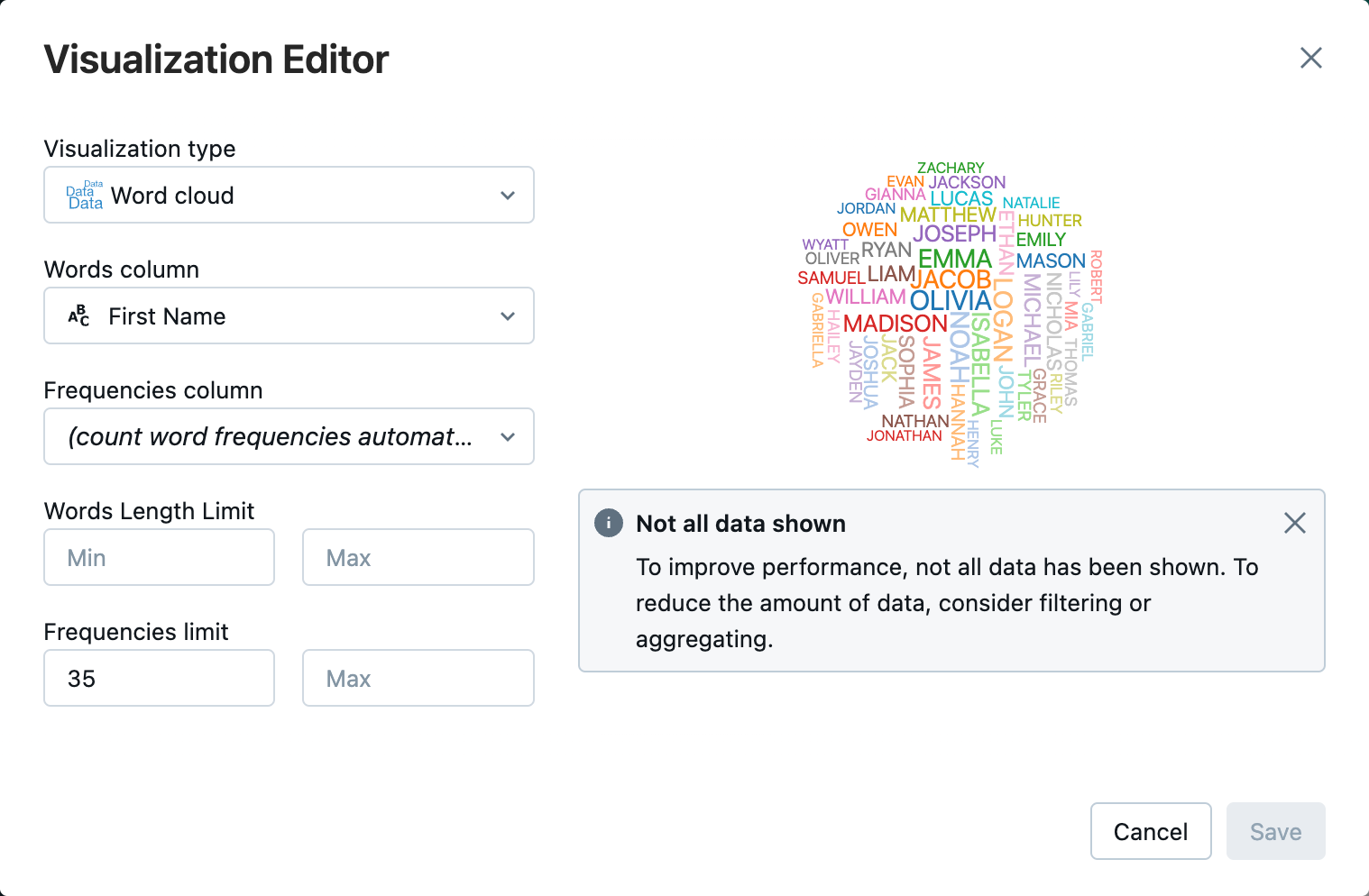
[保存]をクリックします。
ステップ6:DataFrameをテーブルに保存する
重要
DataFrame を Unity Catalog に保存するには、カタログとスキーマに対するCREATEテーブル権限が必要です。 Unity Catalogの権限に関する情報については、 「 Unity Catalogの権限とセキュリティ保護可能なオブジェクト」およびUnity Catalogの権限の管理」を参照してください。
次のコードをコピーして、ノートブックの空のセルに貼り付けます。このコードは、列名のスペースを置き換えます。スペースなどの特殊文字は、列名には使用できません。このコードはApache Spark「
withColumnRenamed()」メソッドを使用します。df = df.withColumnRenamed("First Name", "First_Name") df.printSchema
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name") // when modifying a DataFrame in Scala, you must assign it to a new variable dfRenamedColumn.printSchema()
df <- withColumnRenamed(df, "First Name", "First_Name") printSchema(df)
次のコードをコピーして、ノートブックの空のセルに貼り付けます。このコードは、この記事の冒頭で定義したテーブル名変数を使用して、DataFrameの内容をUnity Catalogのテーブルに保存します。
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")
テーブルが保存されたことを確認するには、左のサイドバーで [カタログ] をクリックして、カタログエクスプローラーUIを開きます。カタログを開き、スキーマを開いてテーブルが表示されていることを確認します。
テーブルをクリックすると、[概要] タブにテーブルスキーマが表示されます。
[サンプルデータ] をクリックすると、テーブルから100行のデータが表示されます。
データノートブックをインポートして可視化する
次のいずれかのノートブックを使用して、この記事のステップを実行します。 <catalog-name>、<schema-name>、および <volume-name> を、Unity Catalog ボリュームのカタログ、スキーマ、およびボリューム名に置き換えます。必要に応じて、 table_name 値を任意のテーブル名に置き換えます。
次のステップ
CSVファイルから既存のテーブルにデータを追加する方法については、「はじめに:追加データを取り込んで挿入する」を参照してください。
データのクレンジングと拡張の詳細については、「はじめに:データの拡張とクレンジング」を参照してください。