はじめに: Databricksで初めての機械学習モデルを構築する
この記事では、Databricks の scikit-learn ライブラリを使用して機械学習分類モデルを構築する方法について説明します。
目標は、ワインが「高品質」と見なされるかどうかを予測する分類モデルを作成することです。 データセットは、さまざまなワインの 11 の特徴 (アルコール含有量、酸度、残留糖など) と、1 から 10 の品質ランキングで構成されています。
この例では、MLflow を使用してモデル開発プロセスを追跡し、Hyperopt を使用してハイパーパラメーターチューニングを自動化する方法も示しています。
このデータセットは、 Modeling wine preferences by data mining from physicochemical properties [Cortez et al., 2009] に掲載されている UCI Machine Learningリポジトリからのものです。
始める前に
ワークスペースでUnity Catalogが有効になっている必要があります。
クラスターを作成する権限、またはクラスターにアクセスするためのアクセス許可が必要です。
カタログに対するUSE_CATALOG権限が必要です。
そのカタログ内では、スキーマに対する権限 (USE_SCHEMA、CREATE_TABLE、および CREATE_MODEL) が必要です。
ヒント
この記事のすべてのコードは、ワークスペースに直接インポートできるノートブックで使用できます。 サンプル ノートブック: 分類モデルの構築を参照してください。
ステップ 1: Databricks ノートブックを作成する
ワークスペースにノートブックを作成するには、サイドバーで ![]() 新規作成をクリックし、ノートブックをクリックします。
新規作成をクリックし、ノートブックをクリックします。
ノートブックの作成と管理の詳細については、ノートブックの管理を参照してください。
ステップ 2: コンピュート リソースへの接続
探索的データ分析とデータエンジニアリングを行うには、コンピュートにアクセスできる必要があります。
既存のコンピュート リソースに接続する手順については、「コンピュートを参照してください。 新しいコンピュート リソースを構成する手順については、 コンピュート構成リファレンスを参照してください。
この記事のステップでは、機械学習のための Databricks Runtime が必要です。 Databricks Runtime のMLバージョンを選択するための詳細情報と手順については、機械学習Databricks Runtimeを参照してください。
ステップ 3: モデルレジストリ、カタログ、スキーマを設定する
始める前に、2つの重要なステップが必要です。 まず、 MLflow クライアントをモデルレジストリとして Unity Catalog を使用するように構成する必要があります。 ノートブックの新しいセルに次のコードを入力します。
import mlflow
mlflow.set_registry_uri("databricks-uc")
また、モデルが登録されるカタログとスキーマも設定する必要があります。 カタログに対する USE CATALOG 権限と、スキーマに対する USE_SCHEMA、CREATE_TABLE、および CREATE_MODEL 権限が必要です。
Unity Catalogの使用方法の詳細については、Unity Catalogとはを参照してください。
ノートブックの新しいセルに次のコードを入力します。
# If necessary, replace "main" and "default" with a catalog and schema for which you have the required permissions.
CATALOG_NAME = "main"
SCHEMA_NAME = "default"
ステップ 4: データを読み込み、Unity Catalog テーブルを作成する
この例では、Databricks に組み込まれている 2 つの CSV ファイルを使用します。 独自のデータを取り込む方法については、Databricks レイクハウスにデータを取り込むを参照してください。
ノートブックの新しいセルに次のコードを入力します。
white_wine = spark.read.csv("dbfs:/databricks-datasets/wine-quality/winequality-white.csv", sep=';', header=True)
red_wine = spark.read.csv("dbfs:/databricks-datasets/wine-quality/winequality-red.csv", sep=';', header=True)
# Remove the spaces from the column names
for c in white_wine.columns:
white_wine = white_wine.withColumnRenamed(c, c.replace(" ", "_"))
for c in red_wine.columns:
red_wine = red_wine.withColumnRenamed(c, c.replace(" ", "_"))
# Define table names
red_wine_table = f"{CATALOG_NAME}.{SCHEMA_NAME}.red_wine"
white_wine_table = f"{CATALOG_NAME}.{SCHEMA_NAME}.white_wine"
# Write to tables in Unity Catalog
spark.sql(f"DROP TABLE IF EXISTS {red_wine_table}")
spark.sql(f"DROP TABLE IF EXISTS {white_wine_table}")
white_wine.write.saveAsTable(f"{CATALOG_NAME}.{SCHEMA_NAME}.white_wine")
red_wine.write.saveAsTable(f"{CATALOG_NAME}.{SCHEMA_NAME}.red_wine")
ステップ 5: データの前処理と分割
このステップでは、ステップ 4 で作成した Unity Catalog テーブルから Pandas DataFrames にデータをロードし、データを前処理します。 このセクションのコードでは、次のことを行います。
データを Pandas DataFramesとしてロードします。
赤ワインと白ワインを区別するために各 にBoolean 列を追加し、 を新しいDataFrameDataFrames DataFrame
data_dfに結合します。データセットには、ワインを 1 から 10 まで評価する
quality列が含まれており、10 は最高品質を示します。 このコードは、この列を 2 つの分類値に変換します。"True" は高品質のワイン (quality>= 7) を示し、"False" は高品質ではないワイン (quality< 7) を示します。DataFrameを別々のトレーニングする データセットと test データセットに分割します。
まず、必要なライブラリをインポートします。
import numpy as np
import pandas as pd
import sklearn.datasets
import sklearn.metrics
import sklearn.model_selection
import sklearn.ensemble
import matplotlib.pyplot as plt
from hyperopt import fmin, tpe, hp, SparkTrials, Trials, STATUS_OK
from hyperopt.pyll import scope
次に、データをロードして前処理します。
# Load data from Unity Catalog as Pandas dataframes
white_wine = spark.read.table(f"{CATALOG_NAME}.{SCHEMA_NAME}.white_wine").toPandas()
red_wine = spark.read.table(f"{CATALOG_NAME}.{SCHEMA_NAME}.red_wine").toPandas()
# Add Boolean fields for red and white wine
white_wine['is_red'] = 0.0
red_wine['is_red'] = 1.0
data_df = pd.concat([white_wine, red_wine], axis=0)
# Define classification labels based on the wine quality
data_labels = data_df['quality'].astype('int') >= 7
data_df = data_df.drop(['quality'], axis=1)
# Split 80/20 train-test
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(
data_df,
data_labels,
test_size=0.2,
random_state=1
)
ステップ 6: 分類モデルのトレーニング
このステップでは、デフォルトのアルゴリズム設定を用いて、勾配ブースト分類器をトレーニングします。次に、結果のモデルをテストデータセットに適用し、 ROC曲線のAUC を計算、ログ、および表示して、モデルのパフォーマンスを評価します。
まず、MLflow の自動ログ記録を有効にします。
mlflow.autolog()
次に、モデルトレーニングの実行を開始します。
with mlflow.start_run(run_name='gradient_boost') as run:
model = sklearn.ensemble.GradientBoostingClassifier(random_state=0)
# Models, parameters, and training metrics are tracked automatically
model.fit(X_train, y_train)
predicted_probs = model.predict_proba(X_test)
roc_auc = sklearn.metrics.roc_auc_score(y_test, predicted_probs[:,1])
roc_curve = sklearn.metrics.RocCurveDisplay.from_estimator(model, X_test, y_test)
# Save the ROC curve plot to a file
roc_curve.figure_.savefig("roc_curve.png")
# The AUC score on test data is not automatically logged, so log it manually
mlflow.log_metric("test_auc", roc_auc)
# Log the ROC curve image file as an artifact
mlflow.log_artifact("roc_curve.png")
print("Test AUC of: {}".format(roc_auc))
セルの結果には、計算された曲線の下の面積とROC曲線のプロットが表示されます。
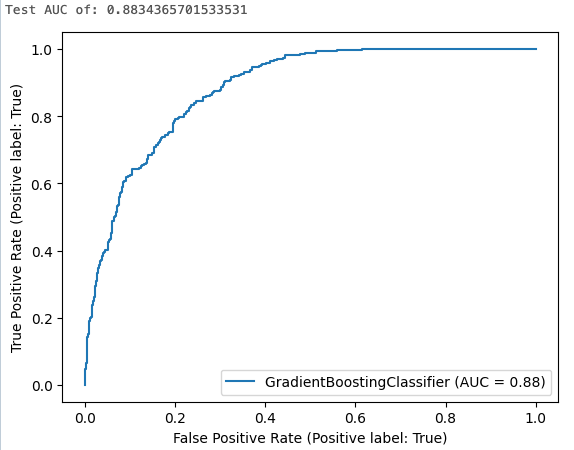
ステップ 7: MLflowでエクスペリメントランを参照
エクスペリメント追跡MLflow、モデルを反復的に開発するときにコードと結果をログに記録することで、モデル開発を追跡するのに役立ちます。
実行したトレーニング実行のログ結果を表示するには、次の図に示すように、セル出力のリンクをクリックします。
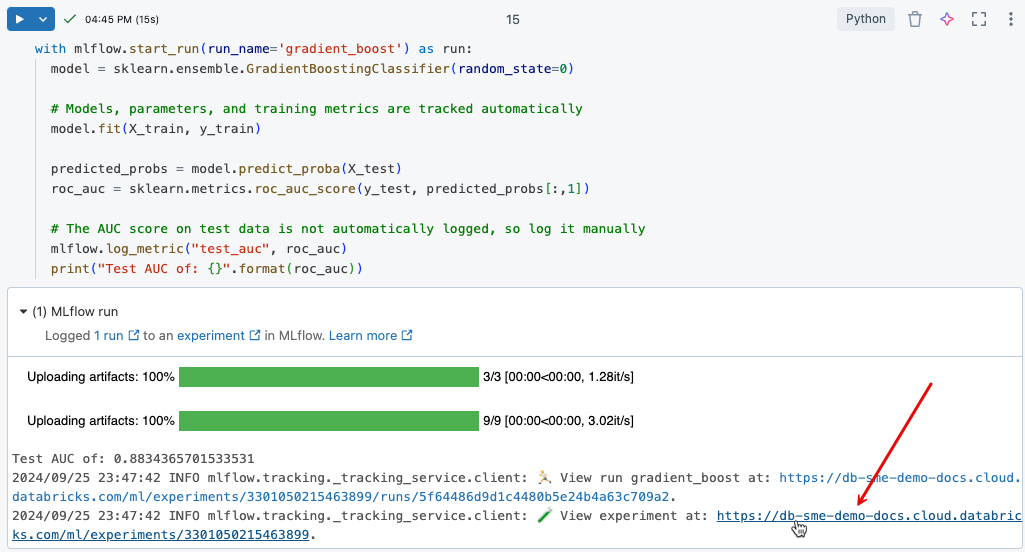
エクスペリメント ページでは、実行を比較したり、特定の実行の詳細を表示したりできます。 エクスペリメントのトラッキングMLflowを参照してください。
ステップ 8: ハイパーパラメーターチューニング
MLモデルの開発における重要なステップは、ハイパーパラメーターと呼ばれるアルゴリズムを制御するパラメーターを調整して、モデルの精度を最適化することです。
機械学習Databricks Runtimeには、ハイパーチューニングパラメーターのPythonライブラリであるHyperoptが含まれています。Hyperopt を使用してハイパーパラメータ スイープを実行し、複数のモデルを並行してトレーニングできるため、モデルのパフォーマンスを最適化するために必要な時間を短縮できます。MLflow トラッキングは、モデルとパラメーターを自動で記録するように、Hyperoptとインテグレーションされています。 Databricks でのHyperopt利用の詳細については、 ハイパーパラメーターチューニング を参照してください。
次のコードは、Hyperopt の使用例を示しています。
# Define the search space to explore
search_space = {
'n_estimators': scope.int(hp.quniform('n_estimators', 20, 1000, 1)),
'learning_rate': hp.loguniform('learning_rate', -3, 0),
'max_depth': scope.int(hp.quniform('max_depth', 2, 5, 1)),
}
def train_model(params):
# Enable autologging on each worker
mlflow.autolog()
with mlflow.start_run(nested=True):
model_hp = sklearn.ensemble.GradientBoostingClassifier(
random_state=0,
**params
)
model_hp.fit(X_train, y_train)
predicted_probs = model_hp.predict_proba(X_test)
# Tune based on the test AUC
# In production, you could use a separate validation set instead
roc_auc = sklearn.metrics.roc_auc_score(y_test, predicted_probs[:,1])
mlflow.log_metric('test_auc', roc_auc)
# Set the loss to -1*auc_score so fmin maximizes the auc_score
return {'status': STATUS_OK, 'loss': -1*roc_auc}
# SparkTrials distributes the tuning using Spark workers
# Greater parallelism speeds processing, but each hyperparameter trial has less information from other trials
# On smaller clusters try setting parallelism=2
spark_trials = SparkTrials(
parallelism=1
)
with mlflow.start_run(run_name='gb_hyperopt') as run:
# Use hyperopt to find the parameters yielding the highest AUC
best_params = fmin(
fn=train_model,
space=search_space,
algo=tpe.suggest,
max_evals=32,
trials=spark_trials)
ステップ 9: 最適なモデル特定してUnity Catalogに登録する
次のコードは、ROC 曲線の下の面積で測定された、最良の結果を生成した実行を示しています。
# Sort runs by their test auc. In case of ties, use the most recent run.
best_run = mlflow.search_runs(
order_by=['metrics.test_auc DESC', 'start_time DESC'],
max_results=10,
).iloc[0]
print('Best Run')
print('AUC: {}'.format(best_run["metrics.test_auc"]))
print('Num Estimators: {}'.format(best_run["params.n_estimators"]))
print('Max Depth: {}'.format(best_run["params.max_depth"]))
print('Learning Rate: {}'.format(best_run["params.learning_rate"]))
最適なモデルとして特定したrun_idを使用して、次のコードをそのモデルを Unity Catalogに登録します。
model_uri = 'runs:/{run_id}/model'.format(
run_id=best_run.run_id
)
mlflow.register_model(model_uri, f"{CATALOG_NAME}.{SCHEMA_NAME}.wine_quality_model")
ノートブックの例: 分類モデルを構築する
次のノートブックを使用して、この記事のステップを実行します。 ノートブックを Databricks ワークスペースにインポートする手順については、ノートブックのインポートを参照してください。