Começar a usar: aprimorar e limpar dados
Este artigo o orienta no uso do site Databricks Notebook para limpar e aprimorar os dados de nomes de bebês do Estado de Nova York que foram previamente carregados em uma tabela em Unity Catalog usando Python, Scala e R. Neste artigo, você altera os nomes das colunas, muda a capitalização e escreve o sexo de cada nome de bebê da tabela de dados brutos e, em seguida, salva o DataFrame em uma tabela prata. Em seguida, o senhor filtra os dados para incluir apenas os dados de 2021, agrupa os dados em nível estadual e classifica os dados por contagem. Por fim, o senhor salva esse DataFrame em uma tabela de ouro e visualiza os dados em um gráfico de barras. Para obter mais informações sobre mesas de prata e ouro, consulte arquitetura de medalhão.
Importante
Este artigo do Get Começar baseia-se no Get Começar: Ingerir e inserir dados adicionais. O senhor deve completar os passos nesse artigo para completar este artigo. Para obter o site Notebook completo para começar artigos, consulte Ingest additional data Notebook.
Requisitos
Para concluir a tarefa neste artigo, o senhor deve atender aos seguintes requisitos:
O site workspace deve ter Unity Catalog habilitado. Para obter informações sobre como começar com Unity Catalog, consulte Configurar e gerenciar Unity Catalog.
Você deve ter o privilégio
WRITE VOLUMEem um volume, o privilégioUSE SCHEMAno esquema pai e o privilégioUSE CATALOGno catálogo principal.O senhor deve ter permissão para usar um recurso compute existente ou criar um novo recurso compute. Consulte Começar com Databricks ou consulte o administrador do site Databricks.
Dica
Para obter um Notebook completo para este artigo, consulte Cleanse and enhance data Notebook.
Etapa 1: criar um novo notebook
Para criar um notebook no seu workspace, clique em ![]() Novo na barra lateral e clique em Notebook. Um notebook em branco será aberto no workspace.
Novo na barra lateral e clique em Notebook. Um notebook em branco será aberto no workspace.
Para saber mais sobre como criar e gerenciar notebooks, consulte Gerenciar notebooks.
Etapa 2: definir variáveis
Neste passo, o senhor define variáveis para uso no exemplo Notebook que criou neste artigo.
Copie e cole o código a seguir na nova célula vazia do Notebook. Substitua
<catalog-name>,<schema-name>e<volume-name>pelos nomes de catálogo, esquema e volume de um volume do Unity Catalog. Opcionalmente, substitua o valortable_namepor um nome de tabela de sua escolha. O senhor salvará os dados do nome do bebê nessa tabela mais adiante neste artigo.Pressione
Shift+Enterpara executar a célula e criar uma nova célula em branco.catalog = "<catalog_name>" schema = "<schema_name>" table_name = "baby_names" silver_table_name = "baby_names_prepared" gold_table_name = "top_baby_names_2021" path_table = catalog + "." + schema print(path_table) # Show the complete path
val catalog = "<catalog_name>" val schema = "<schema_name>" val tableName = "baby_names" val silverTableName = "baby_names_prepared" val goldTableName = "top_baby_names_2021" val pathTable = s"${catalog}.${schema}" print(pathTable) // Show the complete path
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" table_name <- "baby_names" silver_table_name <- "baby_names_prepared" gold_table_name <- "top_baby_names_2021" path_table <- paste(catalog, ".", schema, sep = "") print(path_table) # Show the complete path
Etapa 3: carregar os dados brutos em um novo DataFrame
Esse passo carrega os dados brutos salvos anteriormente em uma tabela Delta em um novo DataFrame em preparação para a limpeza e o aprimoramento desses dados para análise posterior.
Copie e cole o código a seguir na nova célula vazia do notebook.
df_raw = spark.read.table(f"{path_table}.{table_name}") display(df_raw)
val dfRaw = spark.read.table(s"${pathTable}.${tableName}") display(dfRaw)
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df_raw = sql(paste0("SELECT * FROM ", path_table, ".", table_name)) display(df_raw)
Pressione
Shift+Enterpara executar a célula e depois passe para a próxima célula.
Etapa 4: limpar e aprimorar dados brutos e salvar
Nesse passo, o senhor altera o nome da coluna Year, altera os dados da coluna First_Name para letras maiúsculas iniciais e atualiza os valores da coluna Sex para soletrar o sexo e, em seguida, salva o site DataFrame em uma nova tabela.
Copie e cole o código a seguir em uma célula vazia do notebook.
from pyspark.sql.functions import col, initcap, when # Rename "Year" column to "Year_Of_Birth" df_rename_year = df_raw.withColumnRenamed("Year", "Year_Of_Birth") # Change the case of "First_Name" column to initcap df_init_caps = df_rename_year.withColumn("First_Name", initcap(col("First_Name").cast("string"))) # Update column values from "M" to "male" and "F" to "female" df_baby_names_sex = df_init_caps.withColumn( "Sex", when(col("Sex") == "M", "Male") .when(col("Sex") == "F", "Female") ) # display display(df_baby_names_sex) # Save DataFrame to table df_baby_names_sex.write.mode("overwrite").saveAsTable(f"{path_table}.{silver_table_name}")
import org.apache.spark.sql.functions.{col, initcap, when} // Rename "Year" column to "Year_Of_Birth" val dfRenameYear = dfRaw.withColumnRenamed("Year", "Year_Of_Birth") // Change the case of "First_Name" data to initial caps val dfNameInitCaps = dfRenameYear.withColumn("First_Name", initcap(col("First_Name").cast("string"))) // Update column values from "M" to "Male" and "F" to "Female" val dfBabyNamesSex = dfNameInitCaps.withColumn("Sex", when(col("Sex") equalTo "M", "Male") .when(col("Sex") equalTo "F", "Female")) // Display the data display(dfBabyNamesSex) // Save DataFrame to a table dfBabyNamesSex.write.mode("overwrite").saveAsTable(s"${pathTable}.${silverTableName}")
# Rename "Year" column to "Year_Of_Birth" df_rename_year <- withColumnRenamed(df_raw, "Year", "Year_Of_Birth") # Change the case of "First_Name" data to initial caps df_init_caps <- withColumn(df_rename_year, "First_Name", initcap(df_rename_year$First_Name)) # Update column values from "M" to "Male" and "F" to "Female" df_baby_names_sex <- withColumn(df_init_caps, "Sex", ifelse(df_init_caps$Sex == "M", "Male", ifelse(df_init_caps$Sex == "F", "Female", df_init_caps$Sex))) # Display the data display(df_baby_names_sex) # Save DataFrame to a table saveAsTable(df_baby_names_sex, paste(path_table, ".", silver_table_name), mode = "overwrite")
Pressione
Shift+Enterpara executar a célula e depois passe para a próxima célula.
o passo 5: Agrupar e visualizar dados
Nesse passo, o senhor filtra os dados apenas para o ano de 2021, agrupa os dados por sexo e nome, agrega por contagem e ordena por contagem. Em seguida, o senhor salva o DataFrame em uma tabela e visualiza os dados em um gráfico de barras.
Copie e cole o código a seguir em uma célula vazia do notebook.
from pyspark.sql.functions import expr, sum, desc from pyspark.sql import Window # Count of names for entire state of New York by sex df_baby_names_2021_grouped=(df_baby_names_sex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count"))) # Display data display(df_baby_names_2021_grouped) # Save DataFrame to a table df_baby_names_2021_grouped.write.mode("overwrite").saveAsTable(f"{path_table}.{gold_table_name}")
import org.apache.spark.sql.functions.{expr, sum, desc} import org.apache.spark.sql.expressions.Window // Count of male and female names for entire state of New York by sex val dfBabyNames2021Grouped = dfBabyNamesSex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count")) // Display data display(dfBabyNames2021Grouped) // Save DataFrame to a table dfBabyNames2021Grouped.write.mode("overwrite").saveAsTable(s"${pathTable}.${goldTableName}")
# Filter to only 2021 data df_baby_names_2021 <- filter(df_baby_names_sex, df_baby_names_sex$Year_Of_Birth == 2021) # Count of names for entire state of New York by sex df_baby_names_grouped <- agg( groupBy(df_baby_names_2021, df_baby_names_2021$Sex, df_baby_names_2021$First_Name), Total_Count = sum(df_baby_names_2021$Count) ) # Display data display(arrange(select(df_baby_names_grouped, df_baby_names_grouped$Sex, df_baby_names_grouped$First_Name, df_baby_names_grouped$Total_Count), desc(df_baby_names_grouped$Total_Count))) # Save DataFrame to a table saveAsTable(df_baby_names_2021_grouped, paste(path_table, ".", gold_table_name), mode = "overwrite")
Pressione
Ctrl+Enterpara executar a célula.Ao lado da tab Tabela, clique em + e em Visualização.
No editor de visualização, clique em Visualization Type (Tipo de visualização) e verifique se Bar está selecionado.
Na coluna X, selecione`First_Name`.
Clique em Add column (Adicionar coluna ) em Y columns (Colunas Y ) e selecione Total_Count.
Em Group by, selecione Sex.
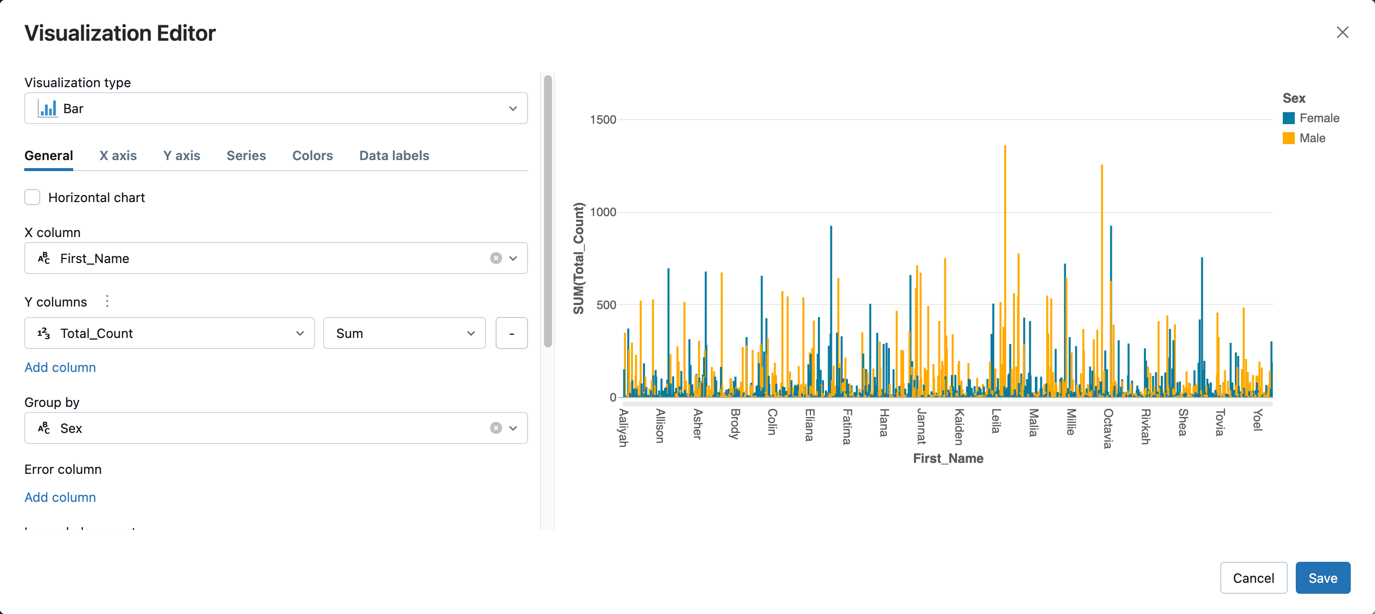
Clique em Salvar.
Limpar e aprimorar os notebooks de dados
Use um dos seguintes Notebooks para executar os passos deste artigo. Substitua <catalog-name>, <schema-name> e <volume-name> pelos nomes de catálogo, esquema e volume de um volume do Unity Catalog. Opcionalmente, substitua o valor table_name por um nome de tabela de sua escolha.