Databricks Connect for R (英語)
注:
この記事では sparklyr Databricks Connect for Databricks Runtime 13.0 以降との統合について説明します。 この統合は、Databricks によって提供されず、Databricks によって直接サポートされていません。
ご不明な点がございましたら、 Posit コミュニティをご覧ください。
問題を報告するには、GitHub の sparklyr リポジトリの [問題] セクションに移動します。
詳細については、sparklyr ドキュメントの「Databricks Connect v2」を参照してください。
この記事では、R、 sparklyr、 RStudio Desktop を使用して Databricks Connect をすばやく開始する方法について説明します。
この記事の Python バージョンについては、「 Databricks Connect for Python」を参照してください。
この記事の Scala バージョンについては、「 Databricks Connect for Scala」を参照してください。
Databricks Connect を使用すると、RStudio Desktop、ノートブック サーバー、その他のカスタム アプリケーションなどの一般的な IDEs を Databricks クラスターに接続できます。 「 Databricks Connect とは」を参照してください。
チュートリアル
このチュートリアルでは、RStudio Desktop と Python 3.10 を使用します。 まだインストールしていない場合は、 R と RStudio Desktop と Python 3.10 をインストールします。
このチュートリアルの補足情報については、sparklyr Web サイトの「Spark Connect と Databricks Connect v2」の「Databricks Connect」セクションを参照してください。
要件
このチュートリアルを完了するには、次の要件を満たす必要があります。
ターゲットDatabricksワークスペースとクラスターは、Databricks Connectのコンピュート構成の要件を満たしている必要があります。
クラスター ID を取得している必要があります。クラスター ID を取得するには、ワークスペースでサイドバーの [ コンピュート ] をクリックし、クラスターの名前をクリックします。 Web ブラウザーのアドレスバーで、URL の
clustersからconfigurationまでの文字列をコピーします。
ステップ 1: 個人用アクセストークンを作成する
注:
Databricks Connect for R 認証では、現在、Databricks 個人用アクセストークンのみがサポートされています。
このチュートリアルでは、Databricks ワークスペースでの認証に Databricks 個人用アクセストークン認証 を使用します。
Databricks の個人用アクセストークンが既にある場合は、「ステップ 2」に進んでください。Databricks 個人用アクセストークンが既にあるかどうかわからない場合は、ユーザー アカウント内の他の Databricks 個人用アクセストークンに影響を与えることなく、このステップに従うことができます。
個人用アクセストークンを作成するには、「ワークスペース ユーザー向けの個人用アクセストークンDatabricks」の手順に従います。
ステップ2:プロジェクトを作成する
RStudio Desktop を起動します。
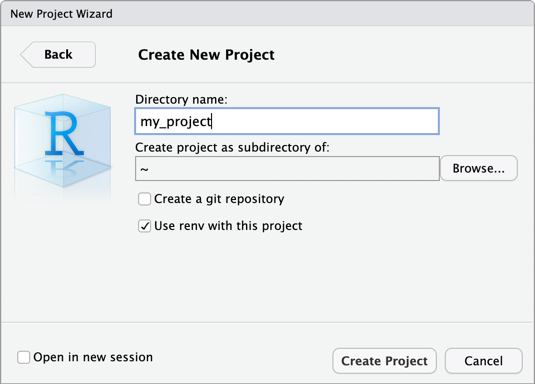
メイン メニューで、[ファイル] > [新しいプロジェクト] をクリックします。
[新しいディレクトリ] を選択します。
[ 新しいプロジェクト] を選択します。
[ ディレクトリ名 ] と [ サブディレクトリとしてプロジェクトを作成] に、新しいプロジェクト ディレクトリの名前と、この新しいプロジェクト ディレクトリを作成する場所を入力します。
[ このプロジェクトで renv を使用する] を選択します。
renvパッケージの更新バージョンをインストールするように求められたら、[はい] をクリックします。「 プロジェクトの作成」をクリックします。
ステップ 3: Databricks Connect パッケージとその他の依存関係を追加する
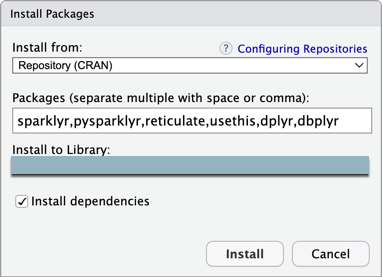
RStudio Desktop のメイン メニューで、[ ツール] > [パッケージのインストール] をクリックします。
[Install from] は [リポジトリ (CRAN)] のままにします。
[パッケージ] に、Databricks Connect パッケージとこのチュートリアルの前提条件であるパッケージの次の一覧を入力します。
sparklyr,pysparklyr,reticulate,usethis,dplyr,dbplyr
[ ライブラリにインストール ] は R 仮想環境に設定したままにします。
[ 依存関係のインストール ] が選択されていることを確認します。
「インストール」をクリックします。
「 コンソール 」ビュー (「View > Move Focus to Console」) でインストールを続行するように求めるプロンプトが表示されたら、
Yと入力します。sparklyrパッケージとpysparklyrパッケージ、およびそれらの依存関係は、R 仮想環境にインストールされます。[コンソール] ウィンドウで、
reticulateを使用して次のコマンドを実行して Python をインストールします。(Databricks Connect for R では、最初にreticulateと Python をインストールする必要があります)。 次のコマンドで、3.10を Databricks クラスターにインストールされている Python バージョンのメジャー バージョンとマイナー バージョンに置き換えます。 このメジャー バージョンとマイナー バージョンを見つけるには、「 Databricks Runtime リリースノートのバージョンと互換性」のクラスターの Databricks Runtime バージョンのリリースノートの「システム環境」セクションを参照してください。reticulate::install_python(version = "3.10")
[コンソール] ウィンドウで、次のコマンドを実行して Databricks Connect パッケージをインストールします。次のコマンドで、
13.3を Databricks クラスターにインストールされている Databricks Runtime バージョンに置き換えます。 このバージョンを見つけるには、Databricks ワークスペースのクラスターの詳細ページの [ 構成 ] タブで、 [ Databricks Runtime バージョン ] ボックスを確認します。pysparklyr::install_databricks(version = "13.3")
クラスターの Databricks Runtime バージョンがわからない場合、または検索したくない場合は、代わりに次のコマンドを実行すると、クラスターにクエリー
pysparklyr、使用する正しい Databricks Runtime バージョンが決定されます。pysparklyr::install_databricks(cluster_id = "<cluster-id>")
先ほど指定したものと同じ Databricks Runtime バージョンを持つ別のクラスターに後でプロジェクトを接続する場合、
pysparklyrでは同じ Python 環境が使用されます。 新しいクラスターの Databricks Runtime バージョンが異なる場合は、新しい Databricks Runtime バージョンまたはクラスター ID を使用してpysparklyr::install_databricksコマンドを再度実行する必要があります。
ステップ 4: ワークスペース URL、アクセストークン、クラスター ID の環境変数を設定する
Databricks では、Databricks ワークスペース URL、Databricks 個人用アクセストークン、Databricks クラスター ID などの機密性の高い値や変更される値を R スクリプトにハードコーディングすることはお勧めしません。 代わりに、これらの値を個別に格納します (たとえば、ローカル環境変数に格納します)。 このチュートリアルでは、RStudio Desktop の組み込みサポートを使用して、環境変数を .Renviron ファイルに格納します。
環境変数を格納する
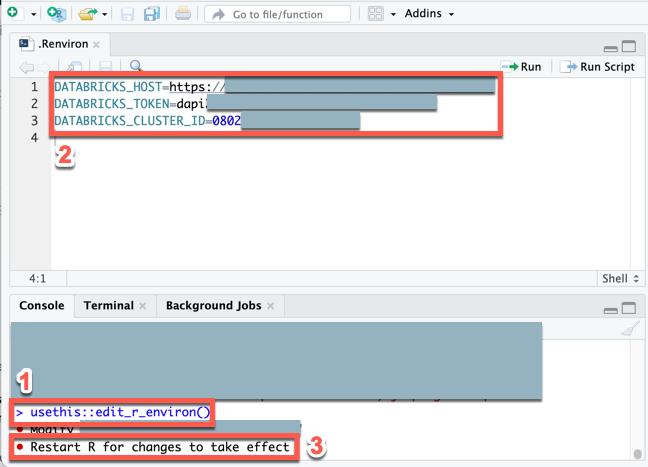
.Renvironファイルが存在しない場合は作成し、このファイルを開いて編集します。 RStudio Desktop Console で、次のコマンドを実行します。usethis::edit_r_environ()
表示される
.Renvironファイル([表示]>[フォーカスをソースに移動])に、次の内容を入力します。 このコンテンツでは、次のプレースホルダーを置き換えます。<workspace-url>をワークスペース インスタンスの URL に置き換えます (例:https://1234567890123456.7.gcp.databricks.com)。<personal-access-token>をステップ 1 の Databricks 個人用アクセストークンに置き換えます。<cluster-id>を、このチュートリアルの要件のクラスター ID に置き換えます。
DATABRICKS_HOST=<workspace-url> DATABRICKS_TOKEN=<personal-access-token> DATABRICKS_CLUSTER_ID=<cluster-id>
.Renvironファイルを保存します。環境変数を R にロードします: メイン メニューで、[ セッション] > [R の再起動] をクリックします。
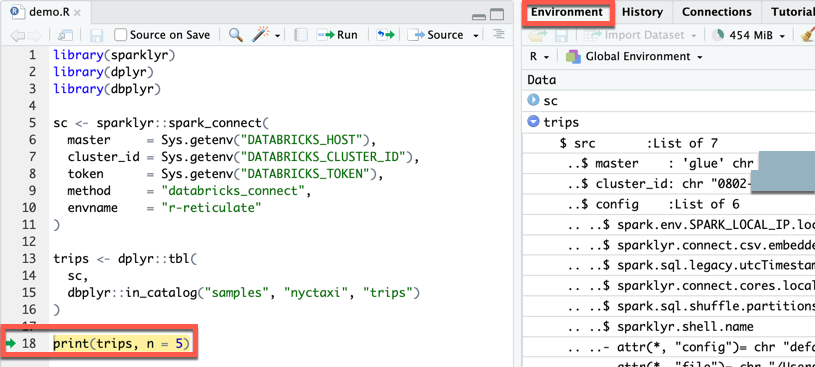
ステップ 5: コードを追加する
RStudio Desktop のメイン メニューで、[ファイル] > [R スクリプト>新しいファイル] をクリックします。
次のコードをファイルに入力し、ファイルを
demo.R次のように保存します ([ファイル] > [保存])。library(sparklyr) library(dplyr) library(dbplyr) sc <- sparklyr::spark_connect( master = Sys.getenv("DATABRICKS_HOST"), cluster_id = Sys.getenv("DATABRICKS_CLUSTER_ID"), token = Sys.getenv("DATABRICKS_TOKEN"), method = "databricks_connect", envname = "r-reticulate" ) trips <- dplyr::tbl( sc, dbplyr::in_catalog("samples", "nyctaxi", "trips") ) print(trips, n = 5)
![プロジェクトの [接続] ビュー](../../../_images/connections-view-rstudio.png)