Databricksアセットバンドルとは?
Databricks アセットバンドル (DAV) は、ソース管理、コードレビュー、テスト、継続的インテグレーションとデリバリー (CI/CD) など、ソフトウェアエンジニアリングのベストプラクティスをデータプロジェクトや AI プロジェクトに適用するためのツールです。 バンドルを使用すると、ジョブ、パイプライン、ノートブックなどの Databricks リソースをソース ファイルとして記述できます。 これらのソース ファイルは、プロジェクトの構造化、テスト、デプロイの方法など、プロジェクトのエンドツーエンドの定義を提供し、アクティブな開発中にプロジェクトでの共同作業を容易にします。
バンドルを使用すると、プロジェクトのソースファイルとともにメタデータを含めることができます。バンドルを使用してプロジェクトをデプロイすると、このメタデータはインフラストラクチャやその他のリソースのプロビジョニングに使用されます。プロジェクトのソースファイルとメタデータのコレクションは、単一のバンドルとしてターゲット環境にデプロイされます。バンドルには以下のパーツがあります。
必要なクラウドインフラストラクチャおよびワークスペースの構成
ビジネスロジックを含むノートブックやPythonファイルなどのソースファイル
Databricksジョブ、Delta Live Tablesパイプライン、モデルサービングエンドポイント、MLflowエクスペリメント、MLflow登録モデルなどのDatabricksリソースの定義と設定
ユニットテストと統合テスト
次の図は、バンドルを使用した開発およびCI/CDパイプラインの概要を示します。
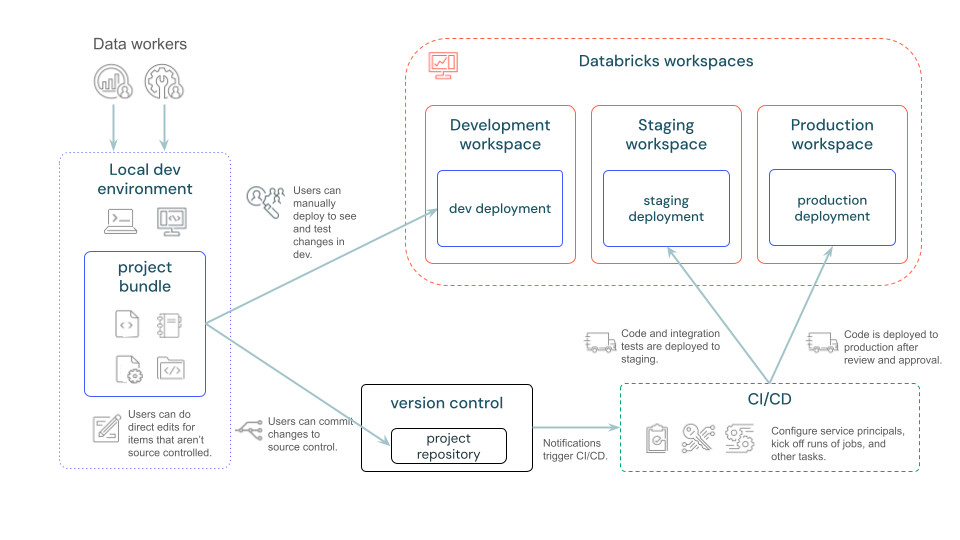
Databricksアセットバンドルはどのような場合に使用しますか?
Databricksアセットバンドルは、Databricksプロジェクトを管理するためのInfrastructure-as-Code(IaC)アプローチです。複数のコントリビューターと自動化が不可欠であり、継続的インテグレーションとデプロイ(CI/CD)が要件である複雑なプロジェクトを管理する場合に使用します。バンドルは、ソースコードと共に作成および保守するYAMLテンプレートとファイルを使用して定義および管理されるため、IaCが適切なアプローチであるシナリオに適切にマップされます。
バンドルの理想的なシナリオには、以下のものがあります。
チームベースの環境で、データ、アナリティクス、機械学習の各プロジェクトを構築します。バンドルを使用すると、さまざまなソースファイルを効率的に整理し管理できるようになります。これにより、コラボレーションがスムーズになり、プロセスも合理化されます。
機械学習の問題を迅速に反復処理します。本番運用のベストプラクティスを最初から採用している機械学習プロジェクトを使用して、機械学習のパイプラインリソース(トレーニングやバッチ推論のジョブなど)を管理します。
デフォルトの権限、サービスプリンシパル、CI/CD構成を含むカスタムバンドルテンプレートを作成することで、新しいプロジェクト向けに組織としての基準を設定できます。
規制順守:規制順守に細心の注意を払う必要のある業界でも、バンドルを活用することで、コードやインフラストラクチャ作業のバージョン管理がしやすくなります。これは適切なガバナンスに役立つだけでなく、必要なコンプライアンス基準を確実に満たす上でも効果的です。
Databricksアセットバンドルはどのように機能しますか?
バンドルメタデータは、Databricksプロジェクトのアーティファクト、リソース、構成を指定するYAMLファイルを使用して定義されます。このYAMLファイルは、手動で作成することも、バンドルテンプレートを使用して生成することもできます。その後、Databricks CLIでこれらのバンドルYAMLファイルを使用してバンドルを検証、デプロイ、実行することができます。バンドルプロジェクトは、IDE、ターミナル、またはDatabricks内から直接実行することができます。この記事ではDatabricks CLIを使用します。
バンドルは手動で作成することも、テンプレートに基づいて作成することもできます。Databricks CLIはシンプルなユースケース用のデフォルトテンプレートを提供しますが、より特殊で複雑なジョブの場合は、カスタムバンドルテンプレートを作成してチームのベストプラクティスを実装し、一般的な構成の一貫性を保つことができます。
Databricks アセット バンドルの表現に使用される構成 YAML の詳細については、「 Databricks アセット バンドルの構成」を参照してください。
バンドルを使用するように環境を構成する
Databricks CLI を使用して、コマンド ラインからバンドルをデプロイします。 Databricks CLI をインストールするには、「 Databricks CLI のインストールまたは更新」を参照してください。
Databricks アセット バンドルは、Databricks CLI バージョン 0.218.0 以降で使用できます。 インストールされている Databricks CLI のバージョンを確認するには、次のコマンドを実行します。
databricks --version
Databricks CLI をインストールした後、リモート Databricks ワークスペースが正しく構成されていることを確認します。 バンドルを使用するには、ワークスペース ファイル機能を有効にする必要があります。 Databricks Runtime バージョン 11.3 LTS 以降を使用している場合、この機能はデフォルトによって有効になります。
認証
Databricks には、いくつかの認証方法が用意されています。
Webブラウザを使用してターゲットのDatabricksワークスペースにログインする手動ワークフロー(Databricks CLIのプロンプトが表示された場合)など、有人認証シナリオの場合は、OAuthユーザー対マシン(U2M)認証を使用します。この方法は、Databricksアセットバンドルの使用開始チュートリアルを試したり、バンドルを迅速に開発したりするのに最適です。
完全に自動化されたワークフローなど、Webブラウザを使用してターゲットのDatabricksワークスペースにログインする機会がない無人認証シナリオの場合は、OAuthマシン間認証(M2M認証)を使用します。この方法はDatabricksサービスプリンシパルを使用する必要がありますが、GitHubなどのCI/CDシステムでDatabricksアセットバンドルを使用するのに最適です。
OAuth U2M認証の場合は、次の手順を実行します。
Databricks CLIを使用して、ターゲットワークスペースごとに以下のコマンドを実行し、ローカルでOAuthトークン管理を開始します。
次のコマンドで、
<workspace-url>をDatabricksワークスペースインスタンスのURLに置き換えます(例:https://1234567890123456.7.gcp.databricks.com)。databricks auth login --host <workspace-url>
Databricks CLIは、入力した情報をDatabricks構成プロファイルとして保存するよう促します。
Enterを押して提案されたプロファイル名を受け入れるか、新規または既存のプロファイルの名前を入力してください。同じ名前の既存のプロファイルは、入力した情報で上書きされます。プロファイルを使用すると、複数のワークスペース間で認証コンテキストをすばやく切り替えることができます。既存のプロファイルのリストを取得するには、別のターミナルまたはコマンドプロンプトでDatabricks CLIを使用してコマンド
databricks auth profilesを実行します。特定のプロファイルの既存の設定を表示するには、コマンドdatabricks auth env --profile <profile-name>を実行します。Webブラウザで、画面の指示に従ってDatabricksワークスペースにログインします。
以下のいずれかのコマンドを実行して、プロファイルの現在のOAuthトークンの値とトークンの今後の有効期限のタイムスタンプを表示します。
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
同じ
--host値を持つプロファイルが複数ある場合、Databricks CLIが正しいOAuthトークン情報を見つけられるように--hostと-pオプションを一緒に指定する必要がある場合があります。
バンドルを検証、デプロイ、実行、破棄するときはいつでも、この構成プロファイルの名前を次の1つまたは複数の方法で使用できます。
コマンドラインオプション
-p <profile-name>を、databricks bundle validate、databricks bundle deploy、databricks bundle run、またはdatabricks bundle destroyコマンドに追加します。「Databricksアセットバンドルの開発」を参照してください。バンドル構成ファイルの最上位の
workspaceマッピングのprofileマッピングの値として(ただし、Databricksでは、バンドル構成ファイルの移植性向上のために、profileマッピングの代わりにDatabricksワークスペースのURLに設定されたhostマッピングを使用することを推奨しています)。ワークスペース内のprofileマッピングの範囲を参照してください。構成プロファイルの名前が
DEFAULTの場合、コマンドラインオプション-p <profile-name>またはprofile(またはhost)マッピングが指定されていないと、これがデフォルトで使用されます。
OAuth M2M認証の場合は、次の手順を実行します。
OAuth M2M 認証の設定手順を完了します。 「 Databricksを使用してサービスプリンシパルで へのアクセスを認証するOAuth (OAuth M2M)」 を参照してください。
以下のいずれかの方法で、ターゲットコンピュートリソースにDatabricks CLIをインストールします。
リアルタイムでコンピュートリソースにDatabricks CLIを手動でインストールするには、「Databricks CLIのインストールまたは更新」を参照してください。
GitHub Actionsを使用してGitHub仮想マシンにDatabricks CLIを自動的にインストールするには、GitHubのsetup-cliを参照してください。
他のCI/CDシステムを使用して仮想マシンにDatabricks CLIを自動的にインストールするには、CI/CDシステムプロバイダーのドキュメントと「Databricks CLIのインストールまたは更新」を参照してください。
コンピュートリソースに以下の環境変数を設定します。
DATABRICKS_HOSTをDatabricksワークスペースインスタンスのURLに設定します(例:https://1234567890123456.7.gcp.databricks.com)。DATABRICKS_CLIENT_IDをDatabricksサービスプリンシパルのアプリケーションIDの値に設定します。DATABRICKS_CLIENT_SECRETをDatabricksサービスプリンシパルのOAuthシークレットの値に設定します。
これらの環境変数を設定するには、ターゲットコンピュートリソースのオペレーティングシステムまたはCI/CDシステムのドキュメントを参照してください。
最初のDatabricksアセットバンドルを開発する
バンドル開発を開始する最速の方法は、バンドル プロジェクト テンプレートを使用することです。 Databricks CLI bundle init コマンドを使用して、最初のバンドル プロジェクトを作成します。 このコマンドは、 Databricks提供のデフォルト バンドル テンプレートの選択肢を提示し、プロジェクト変数を初期化するための一連の質問をします。
databricks bundle init
バンドルの作成は、 バンドルのライフサイクルの最初のステップです。 2 番目のステップはバンドルの開発であり、その重要な要素は、 databricks.yml とリソース構成ファイルでバンドル設定とリソースを定義することです。 バンドル設定に関する情報については、「アセットバンドル設定Databricks」を参照してください。
ヒント
バンドル設定例は、 GitHub のバンドル設定例 と バンドル例リポジトリにあります。
次のステップ
ノートブックを Databricks ワークスペースにデプロイし、そのデプロイされたノートブックを Databricks ジョブとして実行するバンドルを作成します。 「Databricks アセット バンドルを使用して Databricks でジョブを開発する」を参照してください。
ノートブックをDatabricksワークスペースにデプロイし、そのデプロイされたノートブックをDelta Live Tablesパイプラインとして実行するバンドルを作成します。「Databricksアセットバンドルを使用してDelta Live Tablesパイプラインを開発する」を参照してください。
MLOps Stackをデプロイして実行するバンドルを作成します。「MLOpsスタックのDatabricksアセットバンドル」を参照してください。
GitHubのCI/CD(継続的インテグレーション/継続的デプロイメント)ワークフローにバンドルを追加します。「DatabricksアセットバンドルとGitHub Actionsを使用してCI/CDワークフローを実行する」を参照してください。
Python wheelファイルをビルド、デプロイ、呼び出すバンドルを作成します。「Databricksアセットバンドルを使用してPython wheelファイルを開発する」を参照してください。
自分や他のユーザーがバンドルを作成するために使用できるカスタムテンプレートを作成します。 カスタム テンプレートには、デフォルト アクセス許可、サービスプリンシパル、およびカスタム CI/CD 構成が含まれる場合があります。 「Databricks Asset Bundle プロジェクト テンプレート」を参照してください。
dbx から Databricks Asset Bundle に移行します。 dbx からバンドルへの移行を参照してください。
Databricks Asset Bundle でリリースされた最新の主要な新機能をご覧ください。 「 Databricks Asset Bundles feature リリースノート」を参照してください。