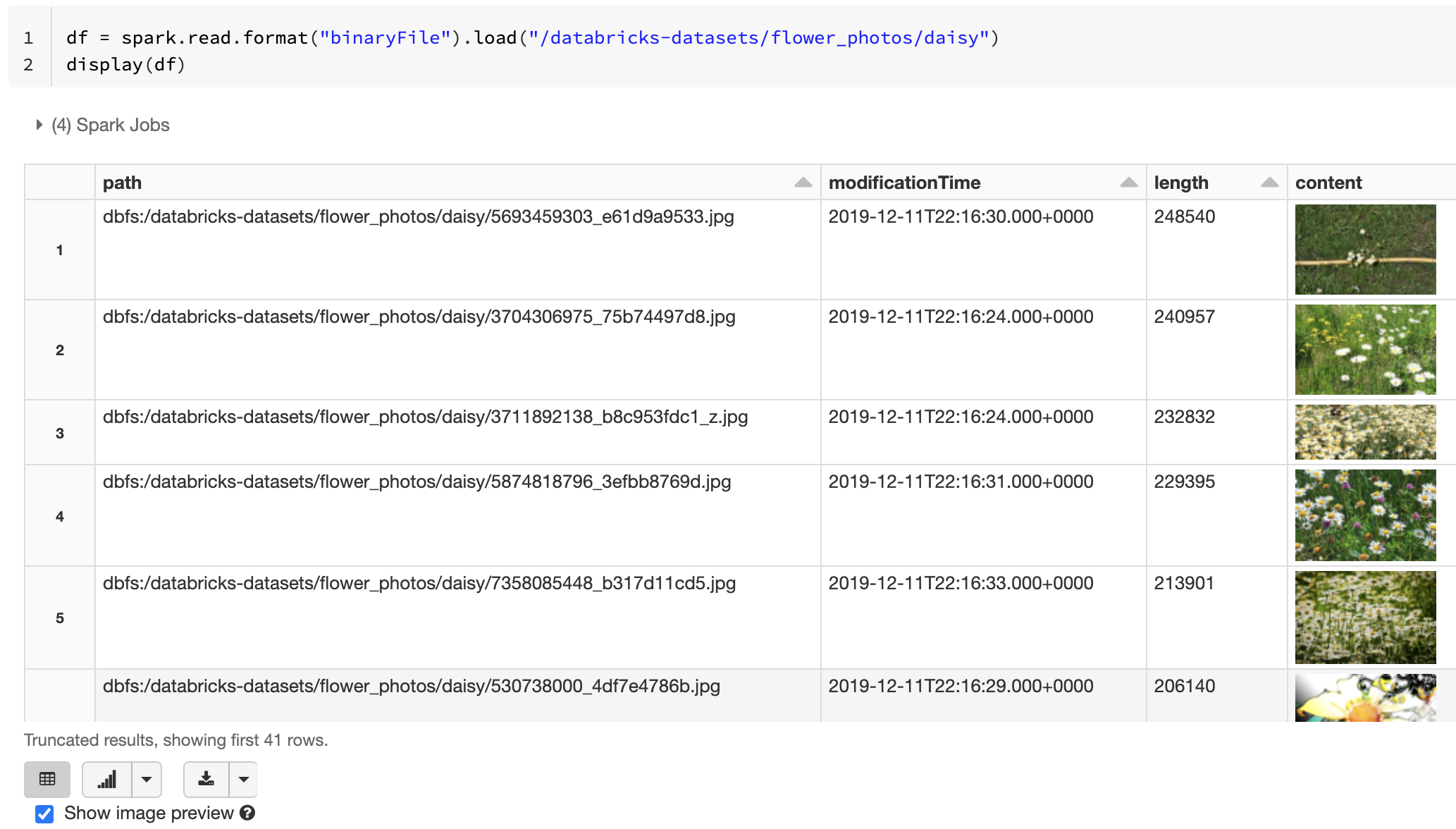
バイナリファイル
Databricks Runtime では、バイナリ ファイルを読み取り、各ファイルをファイルの生のコンテンツとメタデータを含む 1 つのレコードに変換する バイナリ ファイル データソースがサポートされています。 バイナリファイルのデータソースは、次の列と場合によってはパーティション列を含む DataFrame を生成します。
path (StringType): ファイルのパス。modificationTime (TimestampType): ファイルの変更時刻。 一部のHadoop FileSystem実装では、このパラメーターが使用できず、値がデフォルト値に設定される場合があります。length (LongType): ファイルの長さ (バイト単位)。content (BinaryType): ファイルの内容。
バイナリファイルを読み取るには、データソース format を binaryFileとして指定します。
画像
Databricks では、バイナリ ファイル データソースを使用して画像データを読み込むことをお勧めします。
Databricks display 関数では、バイナリ データソースを使用して読み込まれた画像データの表示がサポートされています。
読み込まれたすべてのファイルのファイル名に画像拡張子が付いている場合、 画像プレビューが自動的に有効になります。
df = spark.read.format("binaryFile").load("<path-to-image-dir>")
display(df) # image thumbnails are rendered in the "content" column
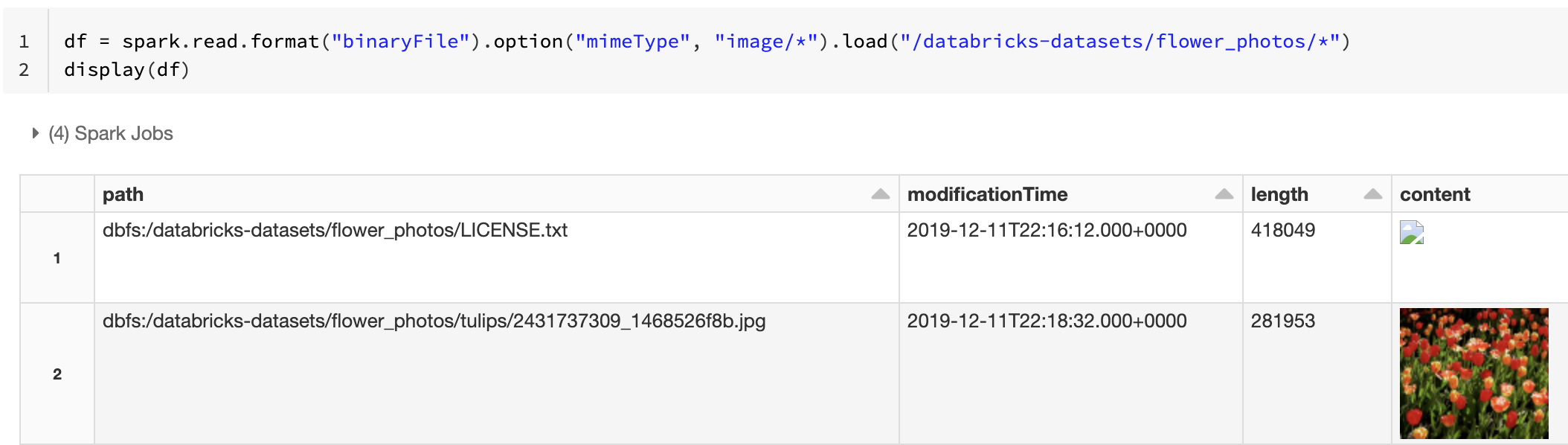
または、文字列値"image/*"で mimeType オプションを使用してバイナリ列に注釈を付けることで、画像プレビュー機能を強制することもできます。イメージは、バイナリ コンテンツ内の形式情報に基づいてデコードされます。 サポートされているイメージ タイプは、 bmp、 gif、 jpeg、 pngです。 サポートされていないファイルは、壊れた画像アイコンとして表示されます。
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("<path-to-dir>")
display(df) # unsupported files are displayed as a broken image icon
画像データを処理するための推奨ワークフローについては、 画像アプリケーションのリファレンスソリューション を参照してください。
オプション
パーティション検出の動作を維持しながら、特定のグロブパターンに一致するパスを持つファイルをロードするには、 pathGlobFilter オプションを使用できます。 次のコードは、パーティション検出を使用して入力ディレクトリからすべての JPG ファイルを読み取ります。
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("<path-to-dir>")
パーティションの検出を無視し、入力ディレクトリの下のファイルを再帰的に検索する場合は、 recursiveFileLookup オプションを使用します。 このオプションは、ネストされたディレクトリの名前が date=2019-07-01のようなパーティションの命名規則に従っていなくても検索します。次のコードは、入力ディレクトリからすべての JPG ファイルを再帰的に読み取り、パーティションの検出を無視します。
df = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("<path-to-dir>")
同様の APIs は、Scala、Java、およびRにも存在します。
注:
データをロードし直すときの読み取りパフォーマンスを向上させるために、Databricks では、バイナリ ファイルからロードされたデータを Delta テーブルを使用して保存することをお勧めします。
df.write.save("<path-to-table>")