transformação de dados com Delta Live Tables
Este artigo descreve como o senhor pode usar o site Delta Live Tables para declarar transformações no conjunto de dados e especificar como os registros são processados por meio da lógica de consulta. Ele também contém exemplos de padrões de transformações comuns para a criação do pipeline Delta Live Tables.
O senhor pode definir um dataset em relação a qualquer consulta que retorne um DataFrame. O senhor pode usar Apache Spark operações integradas, UDFs, lógica personalizada e MLflow modelos como transformações em seu Delta Live Tables pipeline. Depois que os dados forem ingeridos no site Delta Live Tables pipeline, o senhor poderá definir um novo conjunto de dados em relação às fontes upstream para criar novas tabelas de transmissão, visualizações materializadas e visualizações.
Para saber como executar com eficácia o processamento com estado com Delta Live Tables, consulte Otimizar o processamento com estado em Delta Live Tables com marcas d'água.
Quando usar visualizações, visualizações materializadas e tabelas transmitidas
Ao implementar suas consultas em pipeline, escolha o melhor tipo de dataset para garantir que elas sejam eficientes e passíveis de manutenção.
Considere usar o site view para fazer o seguinte:
Divida uma consulta grande ou complexa que o senhor deseja em consultas mais fáceis de gerenciar.
Valide os resultados intermediários usando as expectativas.
Reduza os custos de armazenamento e compute para resultados que o senhor não precisa manter. Como as tabelas são materializadas, elas exigem recursos adicionais de computação e armazenamento.
Considere o uso de uma view materializada quando:
Várias query downstream consomem a tabela. Como view são compute sob demanda, a view écompute toda vez que a view é query.
Outros pipelines, Job ou query consomem a tabela. Como view não são materializadas, você só pode usá-las no mesmo pipeline.
Você deseja view os resultados de uma query durante o desenvolvimento. Como as tabelas são materializadas e podem ser view e query fora do pipeline, o uso de tabelas durante o desenvolvimento pode ajudar a validar a exatidão dos cálculos. Após a validação, converta query que não requer materialização em view.
Considere usar uma mesa de transmissão quando:
Uma query é definida em uma fonte de dados que cresce continuamente ou de forma incremental.
os resultados query devem ser compute de forma incremental.
O site pipeline precisa de alta taxa de transferência e baixa latência.
Observação
As tabelas de transmissão são sempre definidas em relação às fontes de transmissão. O senhor também pode usar fontes de transmissão com APPLY CHANGES INTO para aplicar atualizações dos feeds do site CDC. Consulte a seção APLICAR ALTERAÇÕES APIs: Simplificar a captura de dados de alterações (CDC) com Delta Live Tables.
Excluir tabelas do esquema de destino
Se você precisar calcular tabelas intermediárias não destinadas ao consumo externo, poderá impedir que elas sejam publicadas em um esquema usando a palavra-chave TEMPORARY. As tabelas temporárias ainda armazenam e processam dados de acordo com a semântica das Delta Live Tables, mas não devem ser acessadas fora do pipeline atual. Uma tabela temporária persiste durante o tempo de vida do pipeline que a cria. Use a sintaxe a seguir para declarar tabelas temporárias:
CREATE TEMPORARY STREAMING TABLE temp_table
AS SELECT ... ;
@dlt.table(
temporary=True)
def temp_table():
return ("...")
Combine tabelas de transmissão e visualizações materializadas em um único pipeline
tabelas de transmissão herdam as garantias de processamento do Apache Spark transmissão estruturada e são configuradas para processar query de fontes de dados anexadas somente, onde novas linhas são sempre inseridas na tabela de origem em vez de modificadas.
Observação
Embora, por default, as tabelas de transmissão requeiram fonte de dados apenas anexada, quando uma fonte de transmissão é outra tabela de transmissão que requer atualizações ou exclusões, você pode substituir esse comportamento com o sinalizador skipChangeCommits.
Um padrão de transmissão comum envolve a ingestão de dados de origem para criar o conjunto de dados inicial em um pipeline. Esses conjuntos de dados iniciais são comumente chamados de tabelas de bronze e geralmente realizam transformações simples.
Por outro lado, as tabelas finais em um pipeline, comumente chamadas de tabelas de ouro, geralmente exigem agregações complicadas ou leitura de alvos de uma APPLY CHANGES INTO operação. Como essas operações criam inerentemente atualizações em vez de anexações, elas não são compatíveis como entradas para tabelas de transmissão. Essas transformações são mais adequadas para a visualização materializada.
Ao misturar tabelas transmitidas e view materializada em um único pipeline, você pode simplificar seu pipeline, evitar a reingestão ou reprocessamento dispendioso de dados brutos e ter todo o poder do SQL para compute agregações complexas em um dataset codificado e filtrado com eficiência. O exemplo a seguir ilustra esse tipo de processamento misto:
Observação
Esses exemplos usam o site Auto Loader para carregar arquivos do armazenamento cloud. Para carregar arquivos com o Auto Loader em um pipeline habilitado para o Unity Catalog, o senhor deve usar locais externos. Para saber mais sobre o uso do Unity Catalog com o Delta Live Tables, consulte Use o Unity Catalog com o pipeline Delta Live Tables .
@dlt.table
def streaming_bronze():
return (
# Since this is a streaming source, this table is incremental.
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("gs://path/to/raw/data")
)
@dlt.table
def streaming_silver():
# Since we read the bronze table as a stream, this silver table is also
# updated incrementally.
return spark.readStream.table("streaming_bronze").where(...)
@dlt.table
def live_gold():
# This table will be recomputed completely by reading the whole silver table
# when it is updated.
return spark.readStream.table("streaming_silver").groupBy("user_id").count()
CREATE OR REFRESH STREAMING TABLE streaming_bronze
AS SELECT * FROM read_files(
"gs://path/to/raw/data", "json"
)
CREATE OR REFRESH STREAMING TABLE streaming_silver
AS SELECT * FROM STREAM(streaming_bronze) WHERE...
CREATE OR REFRESH MATERIALIZED VIEW live_gold
AS SELECT count(*) FROM streaming_silver GROUP BY user_id
Saiba mais sobre como usar o Auto Loader para fazer a ingestão incremental de arquivos JSON do Google Cloud Storage.
junções estáticas de transmissão
join estática de transmissão é uma boa escolha ao desnormalizar uma transmissão contínua de dados apenas anexados com uma tabela de dimensão principalmente estática.
A cada atualização do pipeline, novos registros da transmissão são agregados ao Snapshot mais atual da tabela estática. Se os registros forem adicionados ou atualizados na tabela estática após o processamento dos dados correspondentes da tabela de transmissão, os registros resultantes não serão recalculados, a menos que uma refresh completa seja executada.
No pipeline configurado para execução acionada, a tabela estática retorna resultados a partir do momento em que a atualização começa. No pipeline configurado para execução contínua, a versão mais recente da tabela estática é consultada sempre que a tabela processa uma atualização.
Veja a seguir um exemplo de join estática transmitida:
@dlt.table
def customer_sales():
return spark.readStream.table("sales").join(spark.readStream.table("customers"), ["customer_id"], "left")
CREATE OR REFRESH STREAMING TABLE customer_sales
AS SELECT * FROM STREAM(sales)
INNER JOIN LEFT customers USING (customer_id)
Calcule agregados de forma eficiente
O senhor pode usar tabelas de transmissão para calcular de forma incremental agregados distributivos simples, como contagem, mínimo, máximo ou soma, e agregados algébricos, como média ou desvio padrão. A Databricks recomenda a agregação incremental para consultas com um número limitado de grupos, como uma consulta com uma cláusula GROUP BY country. Somente novos dados de entrada são lidos com cada atualização.
Para saber mais sobre como escrever consultas Delta Live Tables que executam agregações incrementais, consulte Executar agregações em janelas com marcas d'água.
Use modelos MLflow em um pipeline Delta Live Tables
Observação
Para usar modelos MLflow em um pipeline habilitado para o Unity Catalog, seu pipeline deve ser configurado para usar o canal preview . Para usar o canal current, você deve configurar seu pipeline para publicar no Hive metastore.
O senhor pode usar modelos treinados pelo MLflow no pipeline Delta Live Tables. Os modelos MLflow são tratados como transformações no Databricks, o que significa que eles agem sobre uma entrada Spark DataFrame e retornam resultados como um Spark DataFrame. Como o Delta Live Tables define o conjunto de dados em relação ao DataFrames, o senhor pode converter as cargas de trabalho do Apache Spark que usam o MLflow para o Delta Live Tables com apenas algumas linhas de código. Para saber mais sobre o MLflow, consulte MLflow for gen AI agent e ML model lifecycle.
Se o senhor já tiver um Notebook Python chamando um modelo MLflow, poderá adaptar esse código para Delta Live Tables usando o decorador @dlt.table e garantindo que as funções sejam definidas para retornar os resultados das transformações. Delta Live Tables não instala MLflow por default, portanto, confirme que o senhor instalou a biblioteca MLFlow com %pip install mlflow e importou mlflow e dlt na parte superior do Notebook. Para obter uma introdução à sintaxe do Delta Live Tables, consulte Desenvolver código de pipeline com Python.
Para usar modelos MLflow em Delta Live Tables, conclua as passos a seguir:
Obtenha o ID de execução e o nome do modelo do modelo MLflow. O ID de execução e o nome do modelo são usados para construir o URI do modelo MLflow.
Use o URI para definir um Spark UDF para carregar o modelo MLflow.
Chame o UDF em suas definições de tabela para usar o modelo MLflow.
O exemplo a seguir mostra a sintaxe básica desse padrão:
%pip install mlflow
import dlt
import mlflow
run_id= "<mlflow-run-id>"
model_name = "<the-model-name-in-run>"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
@dlt.table
def model_predictions():
return spark.read.table(<input-data>)
.withColumn("prediction", loaded_model_udf(<model-features>))
Como um exemplo completo, o código a seguir define uma UDF Spark chamada loaded_model_udf que carrega um modelo MLflow treinado em dados de risco de empréstimo. As colunas de dados usadas para fazer a previsão são passadas como um argumento para o UDF. A tabela loan_risk_predictions calcula previsões para cada linha em loan_risk_input_data.
%pip install mlflow
import dlt
import mlflow
from pyspark.sql.functions import struct
run_id = "mlflow_run_id"
model_name = "the_model_name_in_run"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
categoricals = ["term", "home_ownership", "purpose",
"addr_state","verification_status","application_type"]
numerics = ["loan_amnt", "emp_length", "annual_inc", "dti", "delinq_2yrs",
"revol_util", "total_acc", "credit_length_in_years"]
features = categoricals + numerics
@dlt.table(
comment="GBT ML predictions of loan risk",
table_properties={
"quality": "gold"
}
)
def loan_risk_predictions():
return spark.read.table("loan_risk_input_data")
.withColumn('predictions', loaded_model_udf(struct(features)))
Manter exclusões ou atualizações manuais
Delta Live Tables permite que você exclua ou atualize manualmente os registros de uma tabela e faça uma operação refresh para recalcular as tabelas downstream.
Por default, Delta Live Tables recomputa os resultados da tabela com base nos dados de entrada sempre que um pipeline é atualizado, portanto, é preciso garantir que o registro excluído não seja recarregado a partir dos dados de origem. A definição da propriedade pipelines.reset.allowed table como false impede a atualização de uma tabela, mas não impede gravações incrementais nas tabelas ou o fluxo de novos dados para a tabela.
O diagrama a seguir ilustra um exemplo usando duas tabelas transmitidas:
raw_user_tableingere dados brutos do usuário de uma fonte.bmi_tablecompute de forma incremental as pontuações de IMC usando peso e altura deraw_user_table.
Você deseja excluir ou atualizar manualmente os registros do usuário do raw_user_table e recalcular o bmi_table.
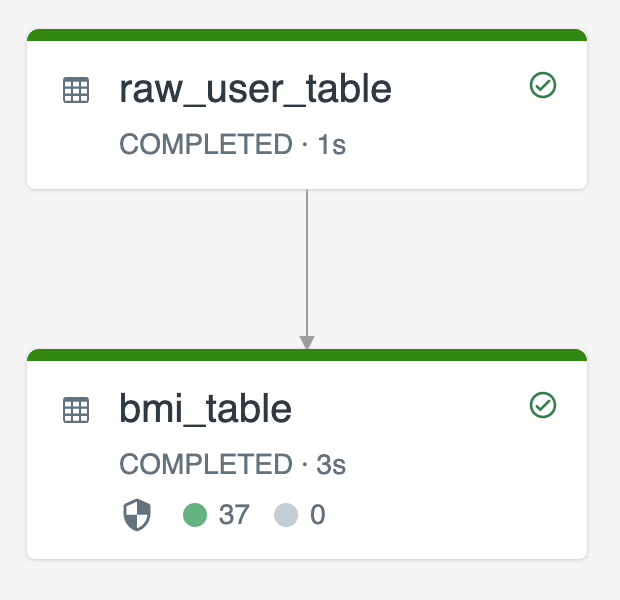
O código a seguir demonstra a configuração da propriedade da tabela pipelines.reset.allowed como false para desabilitar refresh completa para raw_user_table para que as alterações pretendidas sejam retidas ao longo do tempo, mas as tabelas downstream são recalculadas quando uma atualização de pipeline é executada:
CREATE OR REFRESH STREAMING TABLE raw_user_table
TBLPROPERTIES(pipelines.reset.allowed = false)
AS SELECT * FROM read_files("/databricks-datasets/iot-stream/data-user", "csv");
CREATE OR REFRESH STREAMING TABLE bmi_table
AS SELECT userid, (weight/2.2) / pow(height*0.0254,2) AS bmi FROM STREAM(raw_user_table);