Orquestrar o trabalho Databricks com Apache Airflow
Este artigo descreve o suporte do Apache Airflow para orquestrar o pipeline de dados com o Databricks, tem instruções para instalar e configurar o Airflow localmente e fornece um exemplo de implantação e execução de um Databricks fluxo de trabalho com o Airflow.
Job orquestração in a pipeline de dados
O desenvolvimento e a implantação de um processamento de dados pipeline geralmente exigem o gerenciamento de dependências complexas entre as tarefas. Por exemplo, um pipeline pode ler dados de uma fonte, limpar os dados, transformar os dados limpos e gravar os dados transformados em um destino. O senhor também precisa de suporte para testar, programar e solucionar erros quando operacionalizar um pipeline.
Os sistemas de fluxo de trabalho abordam esses desafios, permitindo que o senhor defina as dependências entre as tarefas, programe a execução do pipeline e monitore o fluxo de trabalho. Apache Airflow é uma solução de código aberto para gerenciar e programar pipeline de dados. Airflow representa o pipeline de dados como um gráfico acíclico direcionado (DAGs) de operações. O senhor define um fluxo de trabalho em um arquivo Python e Airflow gerencia a programação e a execução. A conexão Airflow Databricks permite que o senhor aproveite o mecanismo otimizado Spark oferecido por Databricks com o recurso programar de Airflow.
Requisitos
A integração entre o Airflow e o Databricks requer o Airflow versão 2.5.0 e posterior. Os exemplos deste artigo foram testados com o site Airflow versão 2.6.1.
O Airflow requer o Python 3.8, 3.9, 3.10 ou 3.11. Os exemplos deste artigo foram testados com o site Python 3.8.
As instruções neste artigo para instalar e executar o Airflow exigem que o pipenv crie um ambiente virtualPython .
Airflow operadores para Databricks
Um Airflow DAG é composto de tarefas, em que cada tarefa executa um Airflow Operator. Airflow Os operadores que dão suporte à integração com o site Databricks são implementados no provedorDatabricks .
O provedor Databricks inclui operadores para executar várias tarefas em um Databricks workspace, incluindo a importação de dados para uma tabela, a execução de consultas SQL e o trabalho com pastasDatabricks Git .
O provedor Databricks implementa dois operadores para acionar o Job:
O DatabricksRunNowOperator requer um trabalho existente no site Databricks e usa o POST /api/2.1/Job/execução-now Solicitação de API para acionar uma execução. Databricks recomenda o uso do
DatabricksRunNowOperatorporque ele reduz a duplicação de definições de trabalhos, e a execução de trabalhos acionados com esse operador pode ser encontrada na UI de trabalhos.O DatabricksSubmitRunOperator não exige a existência de um trabalho em Databricks e usa o POST /api/2.1/Job/execução/submit API para enviar a especificação do trabalho e acionar a execução.
Para criar um novo trabalho no site Databricks ou redefinir um trabalho existente, o provedor Databricks implementa o DatabricksCreateJobsOperator. O DatabricksCreateJobsOperator usa o POST /api/2.1/Job/create e POST /api/2.1/Job/Reset Solicitações de API. O senhor pode usar o DatabricksCreateJobsOperator com o DatabricksRunNowOperator para criar e executar um trabalho.
Observação
O uso dos operadores do Databricks para acionar um trabalho exige o fornecimento de credenciais na configuração da conexão Databricks. Consulte Criar um Databricks pessoal access token para Airflow.
Os operadores do Databricks Airflow gravam o URL da página de execução do trabalho no Airflow logs a cada polling_period_seconds (o default é de 30 segundos). Para obter mais informações, consulte a página do pacote apache-Airflow -providers-databricks no site Airflow.
Instale a integração do Airflow Databricks localmente
Para instalar o Airflow e o provedor Databricks localmente para testes e desenvolvimento, use os seguintes passos. Para outras opções de instalação do Airflow, incluindo a criação de uma instalação de produção, consulte a instalação na documentação do Airflow.
Abra um terminal e execute o seguinte comando:
mkdir airflow
cd airflow
pipenv --python 3.8
pipenv shell
export AIRFLOW_HOME=$(pwd)
pipenv install apache-airflow
pipenv install apache-airflow-providers-databricks
mkdir dags
airflow db init
airflow users create --username admin --firstname <firstname> --lastname <lastname> --role Admin --email <email>
Substitua <firstname>, <lastname> e <email> por seu nome de usuário e email. Será solicitado que o senhor digite uma senha para o usuário administrador. Certifique-se de salvar essa senha, pois ela é necessária para acessar log in na interface do usuário Airflow.
Esse script executa os seguintes passos:
Cria um diretório chamado
airflowe muda para esse diretório.Usa
pipenvpara criar e gerar um ambiente virtual Python. Databricks recomenda o uso de um ambiente virtual Python para isolar as versões do pacote e as dependências de código nesse ambiente. Esse isolamento ajuda a reduzir as incompatibilidades inesperadas de versões de pacotes e as colisões de dependências de código.Inicializa uma variável de ambiente chamada
AIRFLOW_HOMEdefinida como o caminho do diretórioairflow.Instala o Airflow e o pacote do provedor Airflow Databricks .
Cria um diretório
airflow/dags. O Airflow usa o diretóriodagspara armazenar as definições de DAG.Inicializa um banco de dados SQLite que o Airflow usa para rastrear metadados. Em uma implantação de produção do Airflow, o senhor configuraria o Airflow com um banco de dados padrão. O banco de dados SQLite e a configuração default para sua implementação Airflow são inicializados no diretório
airflow.Cria um usuário administrador para o Airflow.
Dica
Para confirmar a instalação do provedor Databricks, execute o seguinte comando no diretório de instalação Airflow:
airflow providers list
Começar a Airflow servidor web e programador
O servidor da Web Airflow é necessário para view a UI Airflow. Para iniciar o servidor da Web, abra um terminal no diretório de instalação Airflow e execute o seguinte comando:
Observação
Se o servidor da Web Airflow não conseguir iniciar devido a um conflito de porta, o senhor poderá alterar a porta default na configuraçãoAirflow .
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow webserver
O programador é o componente Airflow que programa DAGs. Para iniciar o programador, abra um novo terminal no diretório de instalação Airflow e execute o seguinte comando:
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow scheduler
Teste a instalação do site Airflow
Para verificar a instalação do Airflow, o senhor pode executar um dos DAGs de exemplo incluídos no Airflow:
Em uma janela do navegador, abra
http://localhost:8080/home. Faça login na interface do usuário Airflow com o nome de usuário e a senha que você criou ao instalar o Airflow. A página Airflow DAGs é exibida.Clique no botão de alternância pausa/Unpause DAG para cancelar a pausa de um dos DAGs de exemplo, por exemplo, o
example_python_operator.Acione o DAG de exemplo clicando no botão Trigger DAG.
Clique no nome do DAG para acessar view detalhes, inclusive o status de execução do DAG.
Crie um Databricks pessoal access token para Airflow
Airflow conecta-se a Databricks usando um Databricks personal access token (PAT). Para criar um PAT, siga os passos em Databricks personal access tokens para usuários de workspace .
Observação
Como prática recomendada de segurança, quando o senhor se autenticar com ferramentas, sistemas, scripts e aplicativos automatizados, o site Databricks recomenda o uso do access tokens pessoal pertencente à entidade de serviço em vez do workspace de usuários. Para criar o site tokens para uma entidade de serviço, consulte gerenciar tokens para uma entidade de serviço.
Configurar uma Databricks Connect
Sua instalação Airflow contém uma conexão default para Databricks. Para atualizar a conexão para se conectar ao seu workspace usando o access token pessoal que o senhor criou acima:
Em uma janela do navegador, abra
http://localhost:8080/connection/list/. Se for solicitado a fazer login, digite seu nome de usuário e senha de administrador.Em Conn ID, localize default e clique no botão Edit record (Editar registro ).
Substitua o valor no campo Host pelo nome da instância do espaço de trabalho de sua implantação do Databricks, por exemplo,
https://adb-123456789.cloud.databricks.com.No campo Password (Senha ), digite sua Databricks pessoal access token.
Clique em Salvar.
Exemplo: Criar um DAG Airflow para executar um trabalho Databricks
O exemplo a seguir demonstra como criar uma implantação Airflow simples que é executada em seu computador local e implantar um DAG de exemplo para acionar a execução em Databricks. Neste exemplo, o senhor irá:
Crie um novo Notebook e adicione código para imprimir uma saudação com base em um parâmetro configurado.
Crie um Databricks Job com uma única tarefa para executar o Notebook.
Configure uma conexão Airflow para seu Databricks workspace.
Crie um DAG Airflow para acionar o trabalho do notebook. O senhor define o DAG em um script Python usando
DatabricksRunNowOperator.Use a interface de usuário Airflow para acionar o DAG e view o status da execução.
Criar um notebook
Este exemplo usa um Notebook com duas células:
A primeira célula contém um widget de textoDatabricks utilidades que define uma variável chamada
greetingdefinida como o valor defaultworld.A segunda célula imprime o valor da variável
greetingprefixada porhello.
Para criar o Notebook:
Acesse o site Databricks workspace, clique em
 New na barra lateral e selecione Notebook.
New na barra lateral e selecione Notebook.Dê um nome ao seu Notebook, como Hello Airflow, e certifique-se de que o idioma do default esteja definido como Python.
Copie o seguinte código Python e cole-o na primeira célula do notebook.
dbutils.widgets.text("greeting", "world", "Greeting") greeting = dbutils.widgets.get("greeting")
Adicione uma nova célula abaixo da primeira célula e copie e cole o seguinte código Python na nova célula:
print("hello {}".format(greeting))
Criar um job
Clique em
 fluxo de trabalho na barra lateral.
fluxo de trabalho na barra lateral.Clique em
 .
.A aba Tarefas aparece com a caixa de diálogo de criação de tarefas.
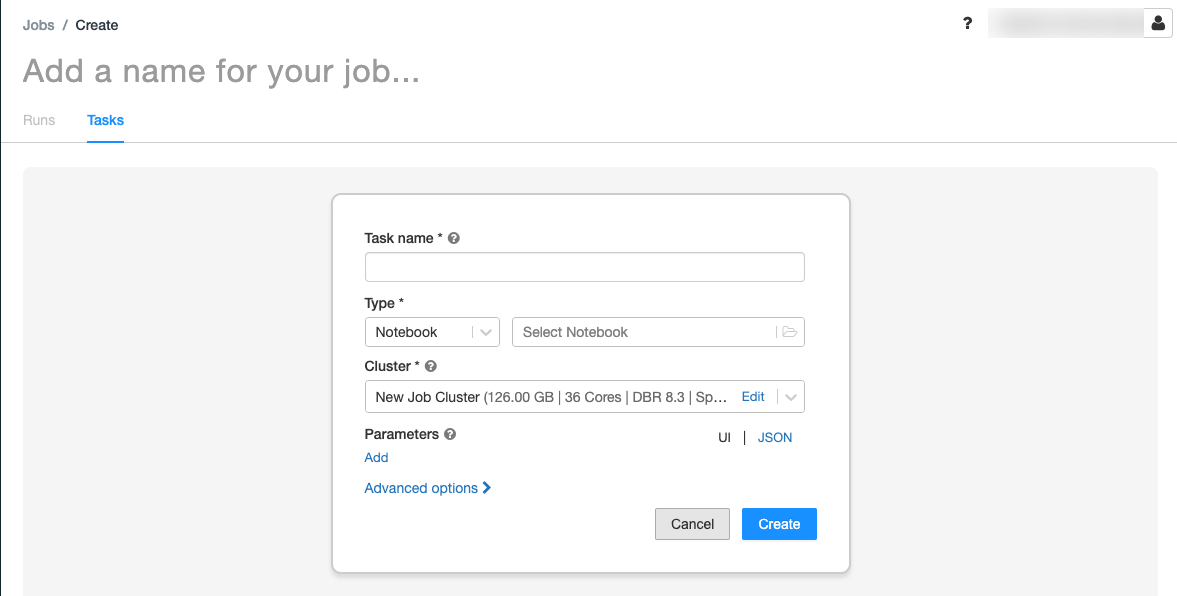
Substitua Adicione um nome para o seu trabalho… pelo nome do seu trabalho.
No campo nome da tarefa, digite um nome para a tarefa, por exemplo, greeting-tarefa.
No menu suspenso Type (Tipo ), selecione Notebook.
No menu suspenso Source (Fonte ), selecione workspace (espaço de trabalho).
Clique na caixa de texto Path (Caminho ) e use o navegador de arquivos para localizar o Notebook que o senhor criou, clique no nome do Notebook e clique em Confirm (Confirmar).
Clique em Adicionar em Parâmetros. No campo Chave, digite
greeting. No campo Valor, digiteAirflow user.Clique em Criar tarefa.
No painel de detalhesJob , copie o valor de IDJob . Esse valor é necessário para acionar o Job em Airflow.
Execute o job
Para testar o novo trabalho na interface de usuário do Databricks Jobs, clique em  no canto superior direito. Quando a execução for concluída, o senhor poderá verificar a saída visualizando os detalhes da execução do trabalho.
no canto superior direito. Quando a execução for concluída, o senhor poderá verificar a saída visualizando os detalhes da execução do trabalho.
Criar um novo DAG Airflow
O senhor define um Airflow DAG em um arquivo Python. Para criar um DAG para acionar o trabalho de exemplo do Notebook:
Em um editor de texto ou IDE, crie um novo arquivo chamado
databricks_dag.pycom o seguinte conteúdo:from airflow import DAG from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator from airflow.utils.dates import days_ago default_args = { 'owner': 'airflow' } with DAG('databricks_dag', start_date = days_ago(2), schedule_interval = None, default_args = default_args ) as dag: opr_run_now = DatabricksRunNowOperator( task_id = 'run_now', databricks_conn_id = 'databricks_default', job_id = JOB_ID )
Substitua
JOB_IDpelo valor da ID do trabalho salva anteriormente.Salve o arquivo no diretório
airflow/dags. O Airflow lê e instala automaticamente os arquivos DAG armazenados emairflow/dags/.
Instalar e verificar o DAG no Airflow
Para acionar e verificar o DAG na Airflow UI:
Em uma janela do navegador, abra
http://localhost:8080/home. A tela Airflow DAGs é exibida.Localize
databricks_dage clique no botão de alternância pausa/Unpause DAG para cancelar a pausa do DAG.Acione o DAG clicando no botão Trigger DAG.
Clique em uma execução na coluna de execução para acessar view o status e os detalhes da execução.