Como funcionam as tabelas Delta
Todas as novas tabelas em Databricks são, por default, criadas como tabelas Delta. Uma tabela Delta armazena dados como um diretório de arquivos no armazenamento de objetos cloud e registra os metadados dessa tabela no metastore em um catálogo e esquema. Todas as tabelas Unity Catalog gerenciar e as tabelas de transmissão são tabelas Delta.
As tabelas Delta contêm linhas de dados que podem ser consultadas e atualizadas usando APIs SQL, Python e Scala. As tabelas Delta armazenam metadados no formato de código aberto Delta Lake. Como usuário, o senhor pode tratar essas tabelas da mesma forma que trataria as tabelas de um banco de dados: pode inserir, atualizar, excluir e merge dados nelas. A Databricks se encarrega de armazenar e organizar os dados de uma forma que ofereça suporte a operações eficientes. Como os dados são armazenados no formato aberto Delta Lake, o senhor pode lê-los e gravá-los em muitos outros produtos além do Databricks.
Embora seja possível criar tabelas em Databricks que não usam o Delta Lake, essas tabelas não oferecem as garantias transacionais ou o desempenho otimizado das tabelas Delta. Para obter mais informações sobre outros tipos de tabela que usam formatos diferentes de Delta Lake, consulte O que é uma tabela?
O código de exemplo a seguir cria uma tabela Delta a partir do conjunto de dados de viagens de táxi de Nova York, filtrando as linhas que contêm uma tarifa superior a US$ 10. Essa tabela não é atualizada quando novas linhas são adicionadas ou atualizadas em samples.nyctaxi.trips:
filtered_df = (
spark.read.table("samples.nyctaxi.trips")
.filter(col("fare_amount") > 10.0)
)
filtered_df.write.saveAsTable("catalog.schema.filtered_taxi_trips")
Agora, o senhor pode consultar essa tabela Delta usando linguagens como SQL ou Python.
Delta tabelas e visualização regular
Um view é o resultado de uma consulta em uma ou mais tabelas e visualizações em Unity Catalog. O senhor pode criar um view a partir de tabelas e de outras visualizações em vários esquemas e catálogos.
Um view regular é uma consulta cujo resultado é recalculado toda vez que o view é consultado. A principal vantagem de um view é que ele permite ocultar a complexidade da consulta dos usuários, pois eles podem consultar o view como uma tabela normal. No entanto, como a visualização regular é recalculada toda vez que uma consulta é executada, ela pode ser cara para consultas complexas ou consultas que processam muitos dados.
O diagrama a seguir mostra como funciona a visualização regular.
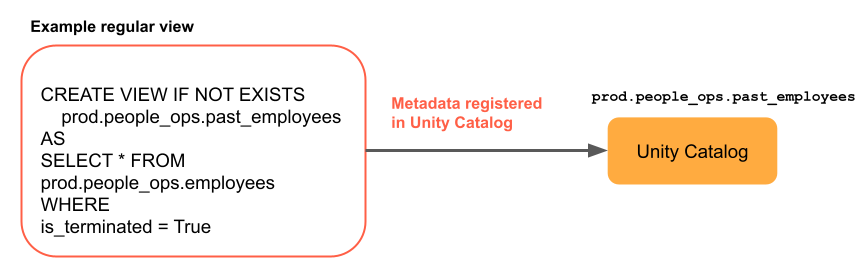
O código de exemplo a seguir cria um view regular a partir do conjunto de dados de viagens de táxi de Nova York, filtrando as linhas que contêm uma tarifa superior a US$ 10. O site view sempre retorna resultados corretos, mesmo que novas linhas sejam adicionadas ou que as linhas existentes sejam atualizadas em samples.nyctaxi.trips:
filtered_df = (
spark.read.table("samples.nyctaxi.trips")
.filter(col("fare_amount") > 10.0)
)
filtered_df.write.createOrReplaceTempView("catalog.schema.v_filtered_taxi_trips")
Agora o senhor pode consultar esse view regular usando linguagens como SQL ou Python.