How does Databricks support CI/CD for machine learning?
CI/CD (continuous integration and continuous delivery) refers to an automated process for developing, deploying, monitoring, and maintaining your applications. By automating the building, testing, and deployment of code, development teams can deliver releases more frequently and reliably than manual processes still prevalent across many data engineering and data science teams. CI/CD for machine learning brings together techniques of MLOps, DataOps, ModelOps, and DevOps.
This article describes how Databricks supports CI/CD for machine learning solutions. In machine learning applications, CI/CD is important not only for code assets, but is also applied to data pipelines, including both input data and the results generated by the model.
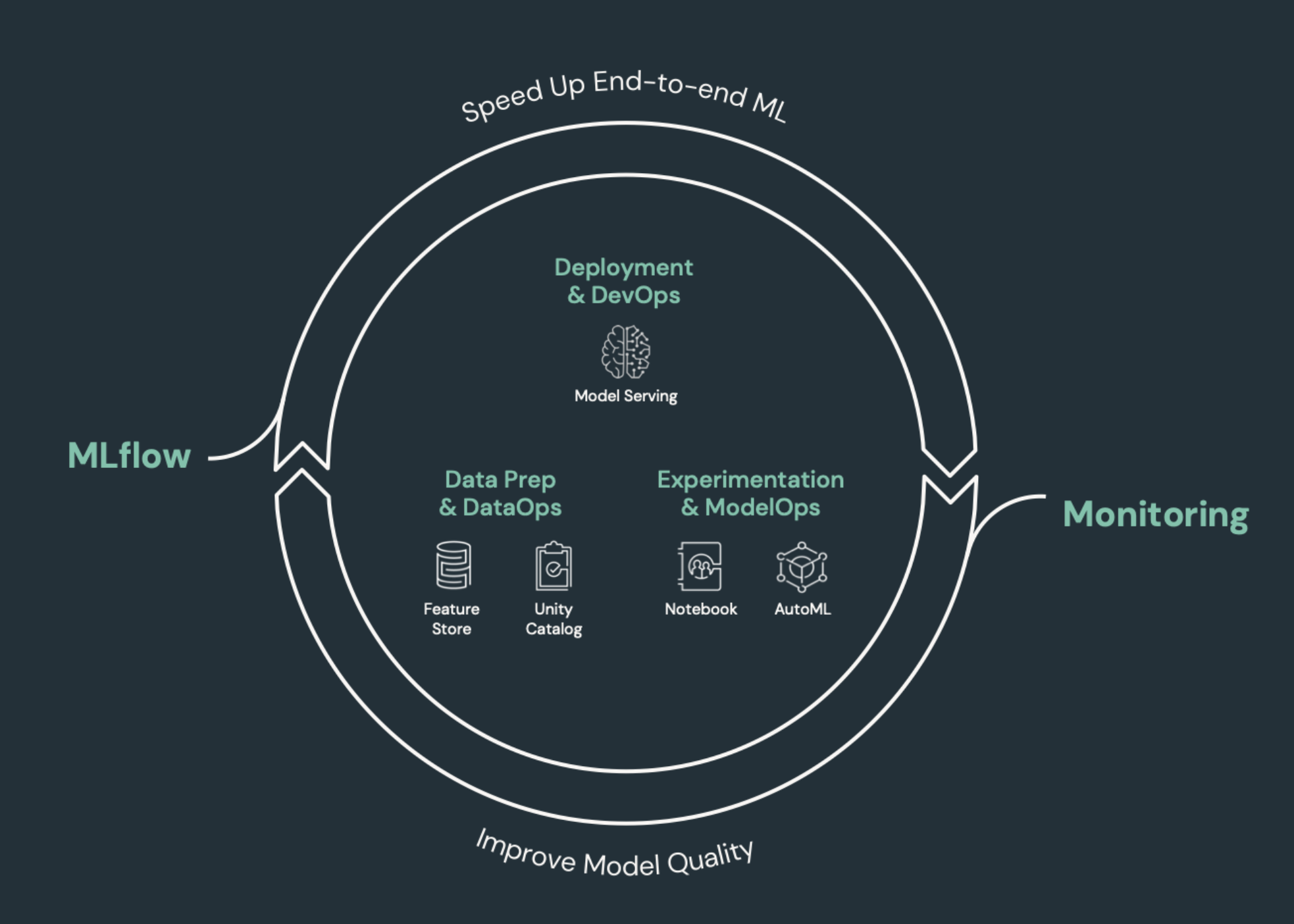
Machine learning elements that need CI/CD
One of the challenges of ML development is that different teams own different parts of the process. Teams may rely on different tools and have different release schedules. Databricks provides a single, unified data and ML platform with integrated tools to improve teams’ efficiency and ensure consistency and repeatability of data and ML pipelines.
In general for machine learning tasks, the following should be tracked in an automated CI/CD workflow:
Training data, including data quality, schema changes, and distribution changes.
Input data pipelines.
Code for training, validating, and serving the model.
Model predictions and performance.
Integrate Databricks into your CI/CD processes
MLOps, DataOps, ModelOps, and DevOps refer to the integration of development processes with “operations” - making the processes and infrastructure predictable and reliable. This set of articles describes how to integrate operations (“ops”) principles into your ML workflows on the Databricks platform.
Databricks incorporates all of the components required for the ML lifecycle including tools to build “configuration as code” to ensure reproducibility and “infrastructure as code” to automate the provisioning of cloud services. It also includes logging and alerting services to help you detect and troubleshoot problems when they occur.
DataOps: Reliable and secure data
Good ML models depend on reliable data pipelines and infrastructure. With the Databricks Data Intelligence Platform, the entire data pipeline from ingesting data to the outputs from the served model is on a single platform and uses the same toolset, which facilitates productivity, reproducibility, sharing, and troubleshooting.

DataOps tasks and tools in Databricks
The table lists common DataOps tasks and tools in Databricks:
DataOps task |
Tool in Databricks |
|---|---|
Ingest and transform data |
Autoloader and Apache Spark |
Track changes to data including versioning and lineage |
|
Build, manage, and monitor data processing pipelines |
|
Ensure data security and governance |
|
Exploratory data analysis and dashboards |
|
General coding |
|
Schedule data pipelines |
|
Automate general workflows |
|
Create, store, manage, and discover features for model training |
|
Data monitoring |
ModelOps: Model development and lifecycle
Developing a model requires a series of experiments and a way to track and compare the conditions and results of those experiments. The Databricks Data Intelligence Platform includes MLflow for model development tracking and the MLflow Model Registry to manage the model lifecycle including staging, serving, and storing model artifacts.
After a model is released to production, many things can change that might affect its performance. In addition to monitoring the model’s prediction performance, you should also monitor input data for changes in quality or statistical characteristics that might require retraining the model.
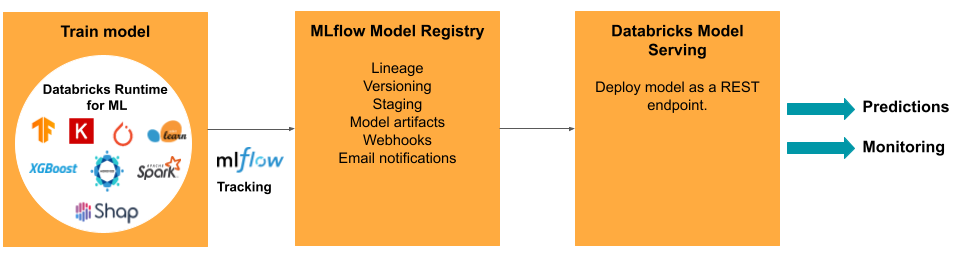
DevOps: Production and automation
The Databricks platform supports ML models in production with the following:
End-to-end data and model lineage: From models in production back to the raw data source, on the same platform.
Production-level Model Serving: Automatically scales up or down based on your business needs.
Jobs: Automates jobs and create scheduled machine learning workflows.
Git folders: Code versioning and sharing from the workspace, also helps teams follow software engineering best practices.
Databricks Terraform provider: Automates deployment infrastructure across clouds for ML inference jobs, serving endpoints, and featurization jobs.
Model serving
For deploying models to production, MLflow significantly simplifies the process, providing single-click deployment as a batch job for large amounts of data or as a REST endpoint.
The Databricks platform supports many model deployment options:
Code and containers.
Batch serving.
Online serving.
Multi-cloud, also train using one cloud and deploy with another.
For more information, see Mosaic AI Model Serving.
Jobs
Databricks Jobs allow you to automate and schedule any type of workload, from ETL to ML. Databricks also supports integrations with popular third party orchestrators like Airflow.
Git folders
The Databricks platform includes Git support in the workspace to help teams follow software engineering best practices by performing Git operations through the UI. Administrators and DevOps engineers can use APIs to set up automation with their favorite CI/CD tools. Databricks supports any type of Git deployment including private networks.
For more information about best practices for code development using Databricks Git folders, see CI/CD workflows with Git integration and Databricks Git folders and Use CI/CD. These techniques, together with the Databricks REST API, let you build automated deployment processes with GitHub Actions, Azure DevOps pipelines, or Jenkins jobs.
Unity Catalog for governance and security
The Databricks platform includes Unity Catalog, which lets admins set up fine-grained access control, security policies, and governance for all data and AI assets across Databricks.