Como o Databricks oferece suporte a CI/CD para machine learning?
CI/CD (integração contínua (CI) e entrega contínua (CD)) refere-se a um processo automatizado para desenvolver, aprimorar, monitorar e manter seus aplicativos. Ao automatizar a criação, o teste e a implantação do código, as equipes de desenvolvimento podem entregar lançamentos com mais frequência e confiabilidade do que os processos manuais ainda predominantes em muitas equipes data engineering e ciência de dados. CI/CD para machine learning reúne técnicas de MLOps, DataOps, ModelOps e DevOps.
Este artigo descreve como o Databricks oferece suporte a CI/CD para soluções machine learning . Em aplicativos machine learning , CI/CD é importante não apenas para ativos de código, mas também é aplicado a pipeline de dados, incluindo dados de entrada e resultados gerados pelo modelo.
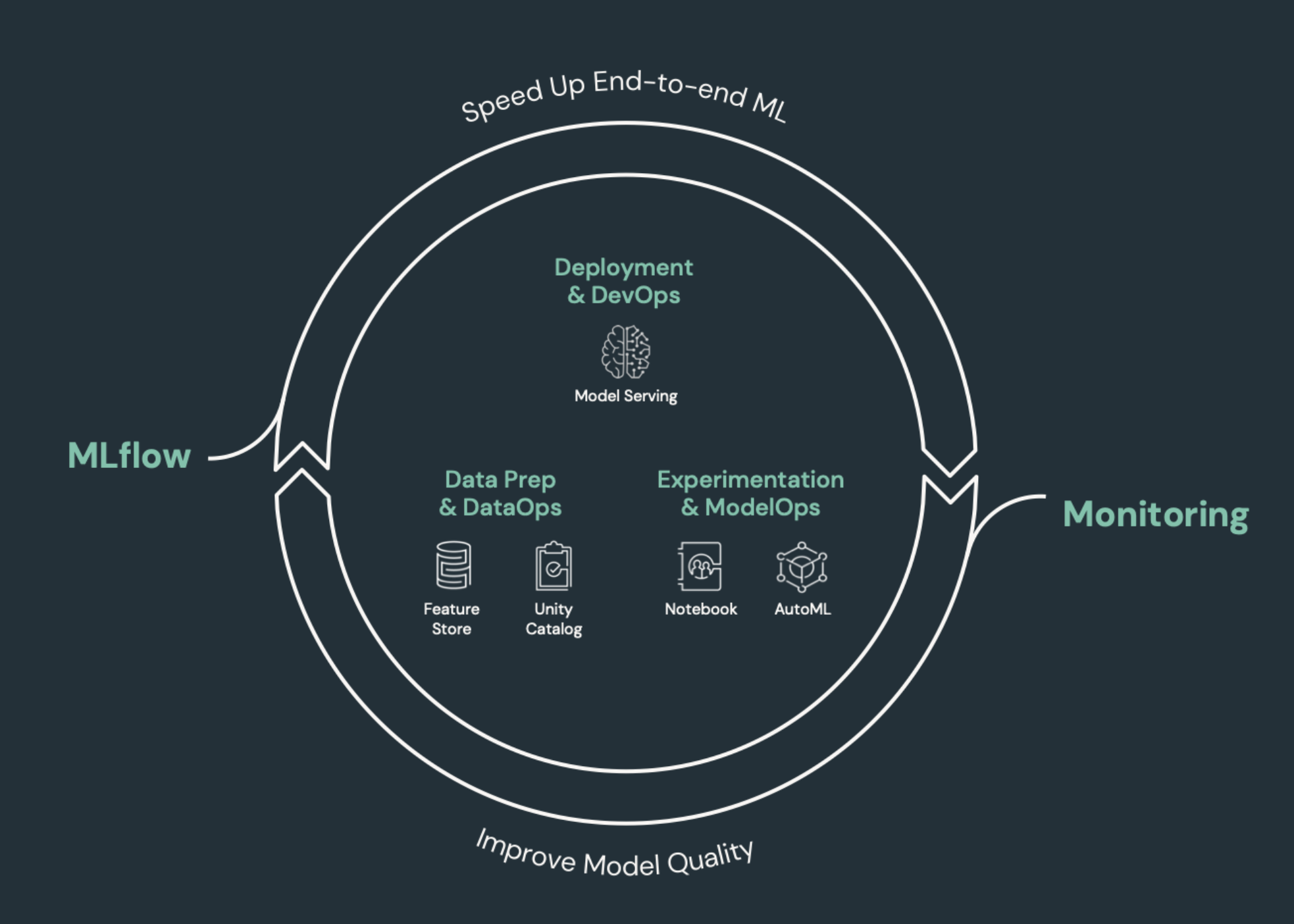
Elementos de aprendizado de máquina que precisam de CI/CD
Um dos desafios do desenvolvimento de ML é que diferentes equipes possuem diferentes partes do processo. As equipes podem contar com diferentes ferramentas e ter diferentes programadores de lançamento. O Databricks fornece uma plataforma única e unificada de dados e ML com ferramentas integradas para melhorar a eficiência das equipes e garantir consistência e repetibilidade de dados e ML pipelines.
Em geral, para tarefas machine learning , o seguinte deve ser rastreado em um fluxo de trabalho CI/CD automatizado:
Dados de treinamento, incluindo qualidade de dados, alterações de esquema e alterações de distribuição.
Pipeline de entrada de dados.
Código para treinamento, validação e atendimento do modelo.
Modelo de previsões e desempenho.
Integre Databricks em seus processos de CI/CD
MLOps, DataOps, ModelOps e DevOps referem-se à integração de processos de desenvolvimento com “operações” – tornando os processos e a infraestrutura previsíveis e confiáveis. Este conjunto de artigos descreve como integrar princípios de operações (“ops”) em seu fluxo de trabalho de ML na plataforma Databricks.
O Databricks incorpora todos os componentes necessários para o ciclo de vida do ML, incluindo ferramentas para criar “configuração como código” para garantir reprodutibilidade e “infraestrutura como código” para automatizar o provisionamento de serviços cloud . Ele também inclui serviços de registro e alerta para ajudá-lo a detectar e solucionar problemas quando eles ocorrem.
DataOps: dados confiáveis e seguros
Bons modelos de ML dependem de pipeline de dados e infraestrutura confiáveis. Com a Databricks Data Intelligence Platform, todo o pipeline de dados, desde a ingestão de dados até as saídas do modelo servido, está em uma única plataforma e usa o mesmo conjunto de ferramentas, o que facilita a produtividade, a reprodutibilidade, o compartilhamento e a solução de problemas.

DataOps tarefas e ferramentas em Databricks
A tabela lista tarefas e ferramentas comuns de DataOps no Databricks:
DataOps tarefa |
Ferramenta em Databricks |
|---|---|
Ingestão e transformação de dados |
Autoloader e Apache Spark |
Rastreie alterações nos dados, incluindo controle de versão e linhagem |
|
Crie, gerencie e monitore pipelines de processamento de dados |
|
Garanta a segurança e a governança dos dados |
|
Análise exploratória de dados e painéis |
|
Codificação geral |
|
programar pipeline de dados |
|
Automatize o fluxo geral de trabalho |
|
Crie, armazene, gerencie e descubra recursos para treinamento de modelos |
ModelOps: desenvolvimento e ciclo de vida do modelo
O desenvolvimento de um modelo requer uma série de experimentos e uma forma de rastrear e comparar as condições e os resultados desses experimentos. A plataforma de inteligência de dados Databricks inclui o MLflow para acompanhamento do desenvolvimento do modelo e o MLflow Model Registry para gerenciar o ciclo de vida do modelo, incluindo preparação, serviço e armazenamento de artefatos do modelo.
Depois que um modelo é liberado para produção, muitas coisas podem mudar e afetar seu desempenho. Além de monitorar o desempenho de previsão do modelo, você também deve monitorar os dados de entrada em busca de mudanças na qualidade ou nas características estatísticas que possam exigir um novo treinamento do modelo.
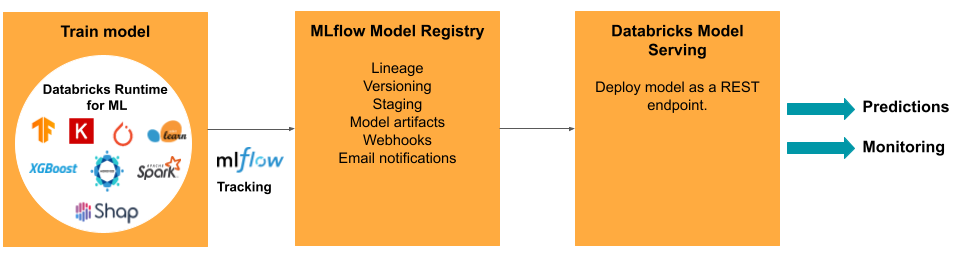
Tarefas e ferramentas ModelOps em Databricks
A tabela lista tarefas e ferramentas ModelOps comuns fornecidas pelo Databricks:
tarefa ModelOps |
Ferramenta em Databricks |
|---|---|
Acompanhar o desenvolvimento do modelo |
|
gerencia o ciclo de vida do modelo |
|
Controle e compartilhamento de versão de código de modelo |
|
Desenvolvimento de modelo sem código |
DevOps: produção e automação
A plataforma Databricks oferece suporte a modelos de ML em produção com o seguinte:
Dados de ponta a ponta e linhagem de modelos: de modelos em produção de volta à fonte de dados brutos, na mesma plataforma.
Model Serving em nível de produção: escalonar automaticamente para cima ou para baixo com base em suas necessidades de negócios.
Trabalhos: Automatiza o trabalho e cria agendamentos machine learning fluxo de trabalho.
Git pastas: O controle de versão do código e o compartilhamento do workspace também ajudam as equipes a seguir as práticas recomendadas de engenharia do software.
Provedor Databricks Terraform: automatiza a infraestrutura de implantação na cloud para Job de inferência de ML, endpoint serviço e Job de caracterização.
Serviço de modelo
Para modelos implantados em produção, o MLflow simplifica significativamente o processo, fornecendo implantação com um único clique como um trabalho em lote para grandes quantidades de dados ou como um endpoint REST.
A plataforma Databricks suporta muitas opções de implantação de modelos:
Código e contêineres.
lotes servindo.
Atendimento on-line.
clouds, também ensinando usando uma clouds e implantando outra.
Para obter mais informações, consulte Mosaic AI Model Serving.
Jobs
Databricks Os trabalhos permitem que o senhor automatize e programe qualquer tipo de carga de trabalho, de ETL a ML. Databricks também oferece suporte a integrações com orquestradores populares de terceiros , como Airflow.
Pastas do Git
A plataforma Databricks inclui suporte Git no workspace para ajudar as equipes a seguir as práticas recomendadas de engenharia software realizando Git operações por meio da interface do usuário. Os administradores e engenheiros de DevOps podem usar APIs para configurar a automação com suas ferramentas de CI/CD favoritas. A Databricks é compatível com qualquer tipo de implementação de Git, inclusive redes privadas.
Para obter mais informações sobre as práticas recomendadas para o desenvolvimento de código usando as pastas Databricks Git , consulte CI/CD fluxo de trabalho com a integração Git e as pastas Databricks Git e Use CI/CD. Essas técnicas, juntamente com o Databricks REST API, permitem que o senhor crie processos de implantação automatizados com GitHub Actions, Azure DevOps pipeline ou Jenkins Job.
Unity Catalog para governança e segurança
A plataforma Databricks inclui o Unity Catalog, que permite aos administradores configurar controle de acesso refinado, políticas de segurança e governança para todos os dados e IA ativa no Databricks.