Databricks は機械学習の CI/CD をどのようにサポートしていますか?
CI/CD (継続的インテグレーションと継続的デリバリー) とは、アプリケーションを開発、デプロイ、モニタリング、および保守するための自動化されたプロセスを指します。 コードのビルド、テスト、デプロイを自動化することで、開発チームは、多くの データエンジニアリング チームやデータサイエンス チームでまだ普及している手動プロセスよりも頻繁かつ確実にリリースを提供できます。 機械学習のための CI/CD は、MLOps、DataOps、ModelOps、DevOps の手法を組み合わせたものです。
この記事では、Databricks が機械学習ソリューションの CI/CD をサポートする方法について説明します。 機械学習アプリケーションでは、CI/CD はコード資産だけでなく、入力データとモデルによって生成された結果の両方を含むデータパイプラインにも適用されます。
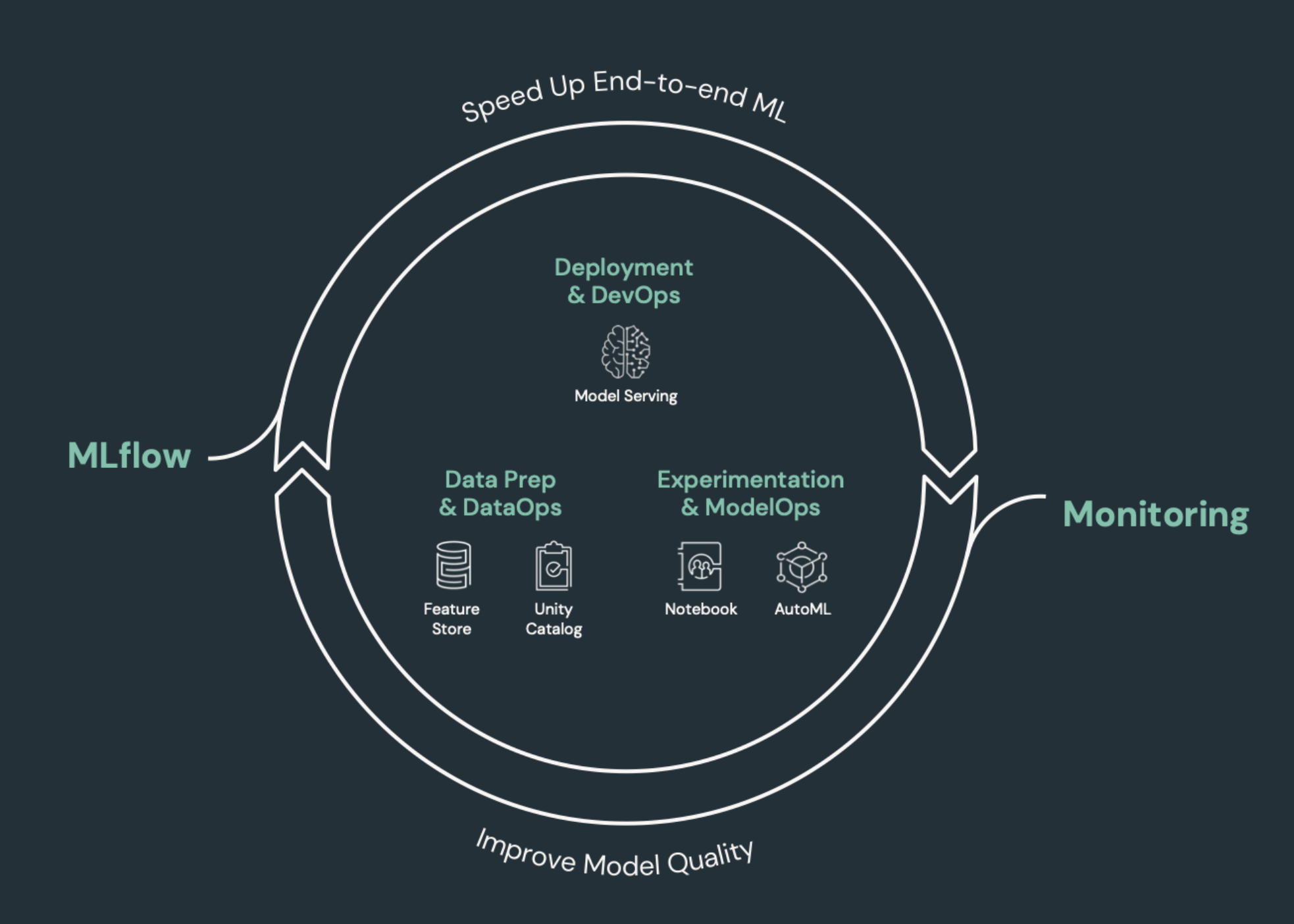
CI/CDを必要とする機械学習要素
機械学習開発の課題の1つは、さまざまなチームがプロセスのさまざまな部分を所有していることです。 チームは異なるツールに依存し、異なるリリーススケジュールを持つ場合があります。 Databricks は、統合されたツールを備えた単一の統合データと 機械学習プラットフォームを提供し、チームの効率を向上させ、データと機械学習パイプラインの一貫性と再現性を確保します。
一般に、機械学習タスクでは、自動化された CI/CD ワークフローで以下を追跡する必要があります。
データ品質、スキーマの変更、分布の変更などのトレーニング データ。
Input データパイプライン.
モデルをトレーニング、検証、および提供するためのコード。
予測とパフォーマンスをモデル化します。
Databricks を CI/CD プロセスに統合する
MLOps、DataOps、ModelOps、DevOpsは、開発プロセスと「運用」の統合を指し、プロセスとインフラストラクチャを予測可能で信頼性の高いものにします。 この一連の記事では、運用 ("ops") の原則を Databricks プラットフォーム上の機械学習ワークフローに統合する方法について説明します。
Databricks には、再現性を確保するための "コードとしての構成" や、クラウド サービスのプロビジョニングを自動化するための "コードとしてのインフラストラクチャ" を構築するツールなど、機械学習ライフサイクルに必要なすべてのコンポーネントが組み込まれています。 また、問題が発生したときに検出してトラブルシューティングするのに役立つログ記録およびアラート サービスも含まれています。
DataOps: 信頼性が高く安全なデータ
優れた機械学習モデルは、信頼性の高いデータパイプラインとインフラストラクチャに依存しています。 Databricksデータインテリジェンスプラットフォームでは、データの取り込みから提供されたモデルからの出力までのデータパイプライン全体が 1 つのプラットフォーム上にあり、同じツールセットを使用するため、生産性、再現性、共有、トラブルシューティングが容易になります。

Databricksの DataOps タスクとツール
次の表に、Databricks の一般的な DataOps タスクとツールを示します。
データ操作タスク |
Databricksツール |
|---|---|
データの取り込みと変換 |
Auto Loader と Apache Spark |
バージョン管理や系列を含むデータの変更を追跡する |
|
データ処理パイプラインの構築、管理、監視 |
|
データのセキュリティとガバナンスを確保する |
|
探索的データ分析とダッシュボード |
|
一般的なコーディング |
|
データパイプラインのスケジュール |
|
一般的なワークフローの自動化 |
|
モデル トレーニングのための機能の作成、保存、管理、検出 |
ModelOps: モデルの開発とライフサイクル
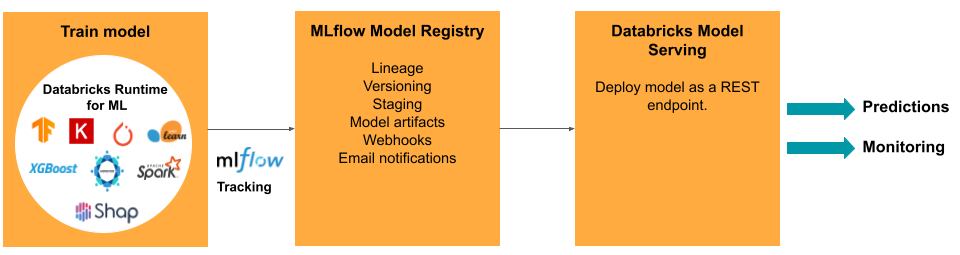
モデルの開発には、一連のエクスペリメントと、それらのエクスペリメントの条件と結果を追跡して比較する方法が必要です。 Databricksデータインテリジェンスプラットフォームには、モデル開発追跡のための MLflow と、モデル成果物のステージング、提供、保存などのモデル ライフサイクルを管理する MLflow Model Registry が含まれています。
モデルが運用環境にリリースされた後、パフォーマンスに影響を与える可能性のある多くの変更が発生する可能性があります。 モデルの予測パフォーマンスを監視するだけでなく、モデルの再トレーニングが必要になる可能性がある品質や統計特性の変化について、入力データを監視する必要もあります。
DevOps: 本番環境と自動化
Databricks プラットフォームでは、本番運用の機械学習モデルが次のようにサポートされています。
エンドツーエンドのデータとモデル系列: 本番環境のモデルから生の Data まで、同じプラットフォーム上で。
実稼働レベルの Model Serving:ビジネスニーズに基づいて自動的にスケールアップまたはスケールダウンします。
ジョブ: ジョブを自動化し、スケジュールされた機械学習ワークフローを作成します。
Git フォルダー: コードのバージョン管理とワークスペースからの共有は、チームがソフトウェア エンジニアリングのベスト プラクティスに従うのにも役立ちます。
Databricks Terraform プロバイダー: 機械学習推論ジョブ、エンドポイントの提供、特徴付けジョブのために、クラウド全体のデプロイ インフラストラクチャを自動化します。
モデルサービング
モデルを本番運用にデプロイする場合、MLflow ではプロセスが大幅に簡素化され、大量のデータのバッチジョブとして、または REST エンドポイントとしてシングルクリックでデプロイできます。
Databricks プラットフォームでは、多くのモデル デプロイ オプションがサポートされています。
コードとコンテナー。
バッチサービング。
オンライン配信。
マルチクラウド、また、1つのクラウドを使用してトレーニングし、別のクラウドで展開します。
詳細については、 Mosaic AI Model Servingを参照してください。
ジョブ
Databricks ジョブを使用すると、ETL から ML まで、あらゆる種類のワークロードを自動化およびスケジュールできます。Databricks は、Airflow などの一般的なサードパーティ オーケストレーターとの統合もサポートしています。
Git フォルダー
Databricks プラットフォームには、ワークスペースに Git サポートが含まれており、UI を通じて Git 操作を実行することで、チームがソフトウェア エンジニアリングのベスト プラクティスに従うのに役立ちます。 管理者とDevOpsエンジニアはAPIsを使用して、お気に入りのCI/CDツールで自動化を設定できます。 Databricks は、プライベート ネットワークを含むあらゆるタイプの Git デプロイメントをサポートします。
フォルダーを使用したコード開発のベスト プラクティスの詳細については、DatabricksGit CI/CD統合を使用した ワークフロー」と フォルダー」Git DatabricksGitおよび の使用」CI/CD を参照してください。これらの手法と Databricks REST API を組み合わせることで、GitHub Actions、Azure DevOps パイプライン、または Jenkins ジョブを使用して自動化されたデプロイ プロセスを構築できます。
ガバナンスとセキュリティーのためのUnity Catalog
Databricks プラットフォームには Unity Catalog が含まれており、管理者は Databricks 全体のすべてのデータと AI 資産に対してきめ細かなアクセス制御、セキュリティ ポリシー、ガバナンスを設定できます。