Databricks 上の LLMOps ワークフロー
この記事では、LLMOps ワークフローに固有の情報を追加することで、Databricks 上の MLOps ワークフローを補完します。 詳細については、 『The Big Book of MLOps』を参照してください。
LLM では MLOps ワークフローはどのように変わりますか?
LLM は、自由形式の質問への回答、要約、指示の実行など、さまざまなタスクにわたって、サイズとパフォーマンスの点で先行モデルを大幅に上回る自然言語処理 (NLP) モデルの一種です。
LLM の開発と評価は、従来の ML モデルとはいくつかの重要な点で異なります。 このセクションでは、LLM の主な特性と MLOps への影響について簡単に説明します。
LLM の主なプロパティ |
MLOps への影響 |
|---|---|
LLMにはさまざまな形式があります。
|
開発プロセス:プロジェクトは、既存のサードパーティまたはオープンソースのモデルから始まり、カスタムの微調整されたモデルで終わる段階的に開発されることがよくあります。 |
多くのLLMは、一般的な自然言語のクエリと命令を入力として受け取ります。 これらのクエリには、必要な応答を引き出すために慎重に設計されたプロンプトを含めることができます。 |
開発プロセス: LLM をクエリするためのテキスト テンプレートの設計は、多くの場合、新しい LLM パイプラインの開発において重要な部分です。 ML アーティファクトのパッケージ化:多くの LLM パイプラインは、既存の LLM または LLM サービング エンドポイントを使用します。 これらのパイプライン用に開発された ML ロジックは、モデル自体ではなく、プロンプト テンプレート、エージェント、またはチェーンに重点を置く場合があります。 パッケージ化されて本番運用にプロモートされるMLアーティファクトは、モデルではなくこれらのパイプラインである可能性があります。 |
多くの LLM では、クエリの回答に役立つ例、コンテキスト、その他の情報を含むプロンプトが提供されます。 |
サービス インフラストラクチャ: LLM クエリをコンテキストで拡張する場合、ベクター データベースなどの追加ツールを使用して関連するコンテキストを検索できます。 |
サードパーティAPIs独自のオープンソース モデルを提供します。 |
API ガバナンス:集中型 API ガバナンスを使用すると、API プロバイダー間を簡単に切り替えることができます。 |
LLM は非常に大規模なディープラーニング モデルであり、そのサイズはギガバイトから数百ギガバイトに及ぶことがよくあります。 |
インフラストラクチャの提供: LLM には、偶数モデルのサービング用の GPU と、動的にロードする必要があるモデル用の高速ストレージが必要な場合があります。 コストとパフォーマンスのトレードオフ: モデルが大きいほど、より多くの計算が必要になり、提供にコストがかかるため、モデルのサイズと計算を縮小する手法が必要になる場合があります。 |
単一の「正しい」答えがないことが多いため、従来のMLメトリクスを使用して LLM を評価するのは困難です。 |
人間からのフィードバック: LLMの評価とテストには、人間のフィードバックが不可欠です。 テスト、モニタリング、将来のファインチューニングなど、ユーザーのフィードバックをMLOpsプロセスに直接組み込む必要があります。 |
MLOps と LLMOps の共通点
MLOps プロセスの多くの側面は LLM でも変わりません。 たとえば、次のガイドラインは LLM にも適用されます。
開発、ステージング、本番運用には別の環境を使用します。
バージョン管理には Git を使用します。
MLflow を使用してモデル開発を管理し、 Unity Catalog のモデルを使用してモデルのライフサイクルを管理します。
Delta テーブルを使用して、レイクハウス アーキテクチャにデータを保存します。
既存の CI/CD インフラストラクチャを変更する必要はありません。
MLOps のモジュール構造は同じままで、特徴量化、モデル トレーニング、モデル推論などのパイプラインが存在します。
参照アーキテクチャ図
このセクションでは、2 つの LLM ベースのアプリケーションを使用して、従来の MLOps のリファレンス アーキテクチャに対するいくつかの調整について説明します。 図は、1) サードパーティAPIを使用する検索拡張生成 (RAG) アプリケーションと、2) セルフホスト型の微調整モデルを使用する RAG アプリケーションの本番運用アーキテクチャを示しています。 どちらの図もオプションのベクトル データベースを示しています。この項目は、モデルサービング エンドポイントを通じてLLMに直接クエリを実行することで置き換えることができます。
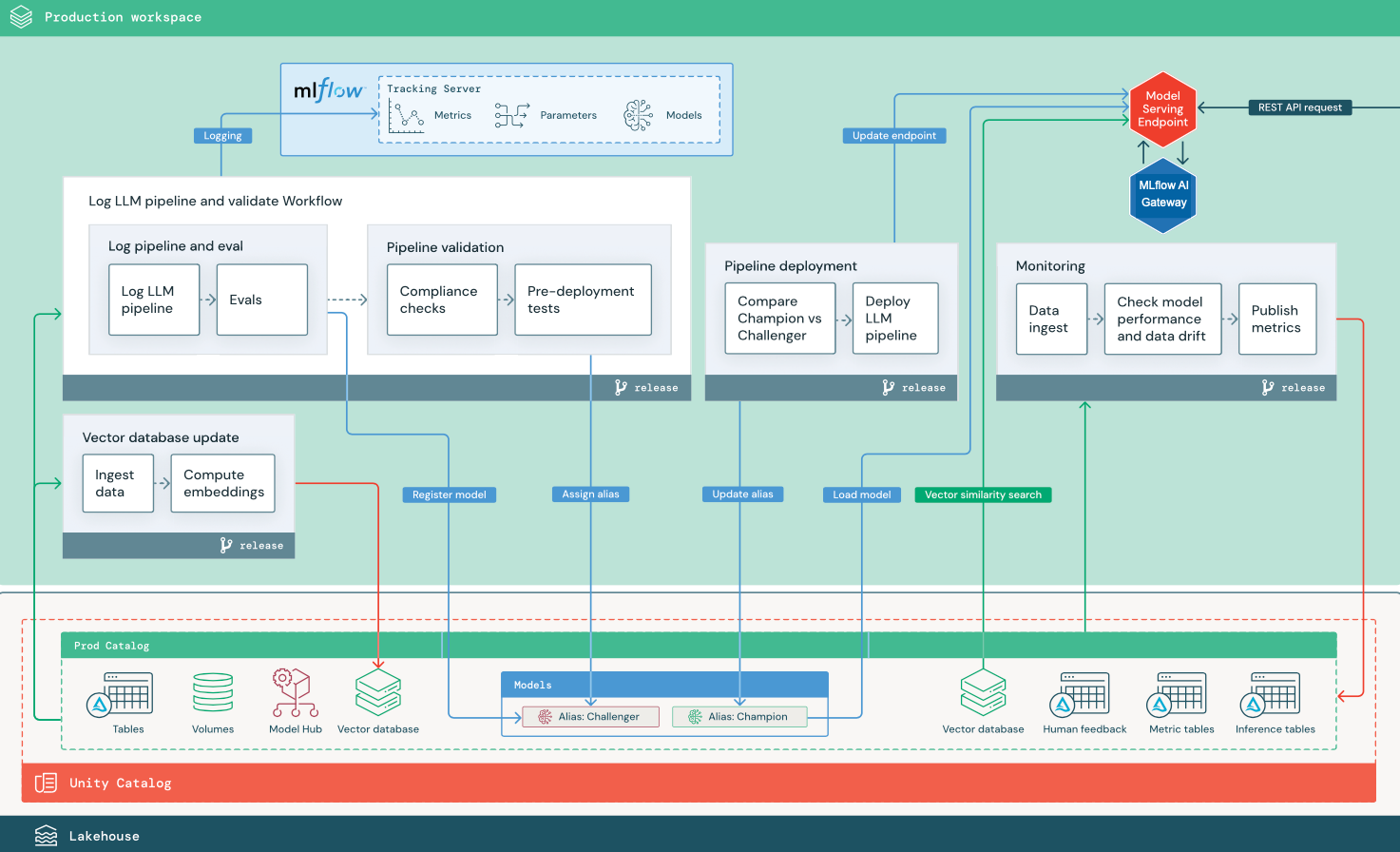
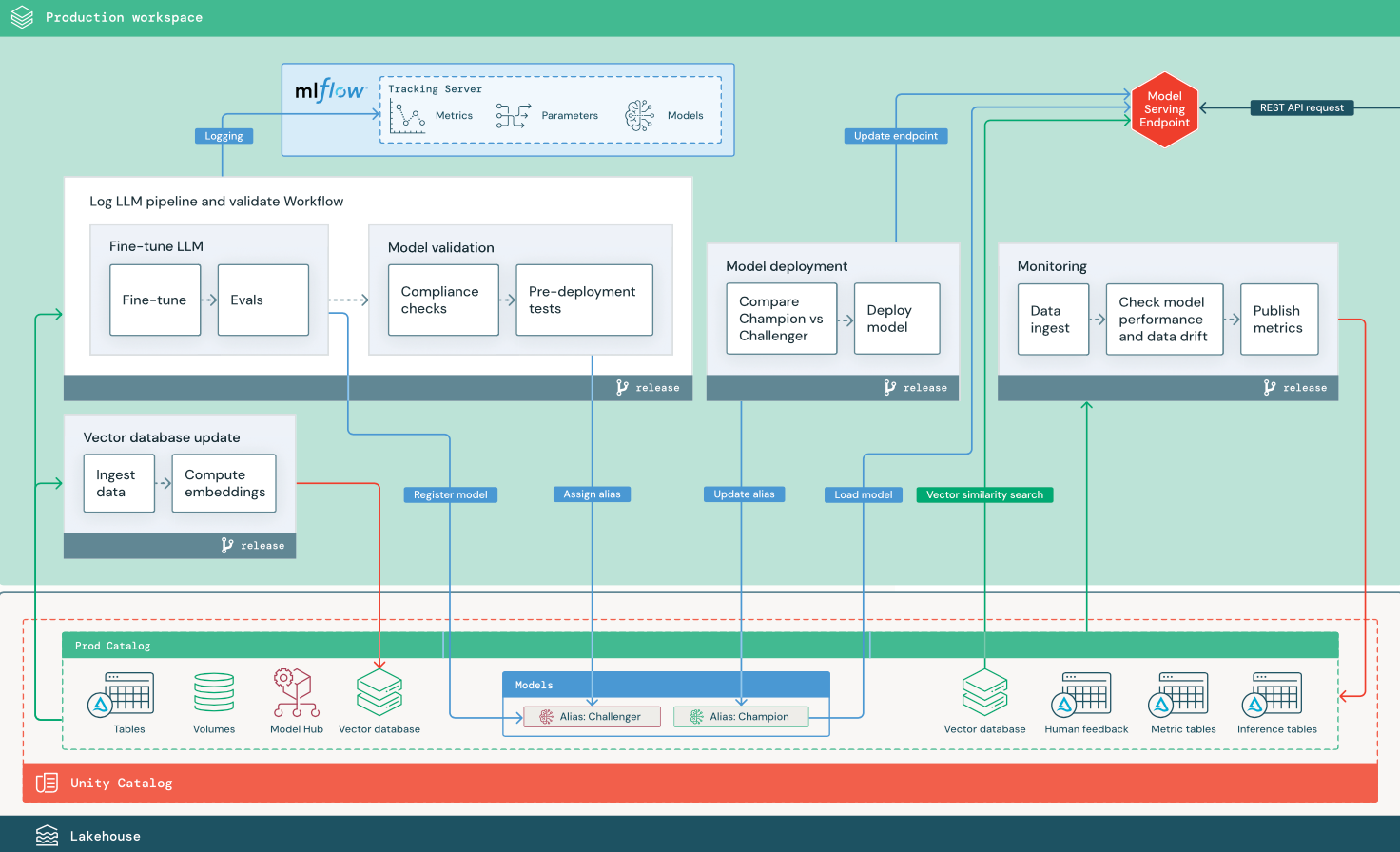
LLMOps からMLOps本番運用アーキテクチャへの変更
このセクションでは、LLMOps アプリケーションの MLOps リファレンス アーキテクチャに対する主な変更点について説明します。
モデルハブ
LLM アプリケーションでは、多くの場合、内部または外部のモデル ハブから選択された既存の事前トレーニング済みモデルが使用されます。 モデルはそのまま使用することも、微調整することもできます。
ベクターデータベース
一部の LLM アプリケーションでは、たとえば LLM クエリでコンテキストやドメインの知識を提供するため、高速な類似性検索にベクトル データベースを使用します。 Databricks、 内の テーブルをベクター データベースとして使用できるようにする統合されたコントローラー検索機能を提供します。DeltaUnity Catalogトレンド検索インデックスはDeltaテーブルと自動的に同期します。 詳細については、 「サーチ」を参照してください。
ベクトル データベースから情報を取得するためのロジックをカプセル化し、返されたデータを LLM へのコンテキストとして提供するモデル成果物を作成できます。 その後、MLflow LangChain または PyFunc モデル フレーバーを使用してモデルをログに記録できます。
LLMの微調整
LLM モデルをゼロから作成するにはコストと時間がかかるため、LLM アプリケーションでは、既存のモデルを微調整して、特定のシナリオでのパフォーマンスを向上させることがよくあります。 リファレンス アーキテクチャでは、微調整とモデルのデプロイは個別のDatabricksジョブとして表されます。 デプロイする前に微調整されたモデルを検証することは、多くの場合、手動のプロセスです。