モデルのデプロイ パターン
この記事では、機械学習アーティファクトをステージング環境と運用環境に移動するための 2 つの一般的なパターンについて説明します。 モデルとコードに対する変更の非同期性は、機械学習開発プロセスが従う可能性のある複数のパターンがあることを意味します。
モデルはコードによって作成されますが、結果のモデル成果物とそれらを作成したコードは非同期的に動作できます。 つまり、新しいモデル バージョンとコードの変更が同時に行われない場合があります。 たとえば、次のシナリオを考えてみます。
不正なトランザクションを検出するには、モデルを毎週再トレーニングする機械学習パイプラインを開発します。 コードはあまり頻繁には変更されないかもしれませんが、新しいデータを組み込むためにモデルが毎週再トレーニングされる可能性があります。
大型のディープニューラルネットワーク を作成して、ドキュメントを分類することができます。 この場合、モデルのトレーニングは計算コストと時間がかかり、モデルの再トレーニングはまれにしか行われない可能性があります。 ただし、このモデルをデプロイ、提供、および監視するコードは、モデルを再トレーニングせずに更新できます。
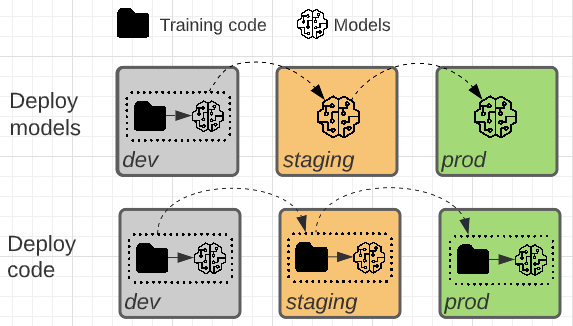
この 2 つのパターンは 、 モデル成果物または モデル成果物を生成するトレーニング コードが 運用環境に昇格されるかどうかが異なります。
コードのデプロイ (推奨)
ほとんどの場合、Databricks では "コードのデプロイ" アプローチをお勧めします。 このアプローチは、 推奨される MLOps ワークフローに組み込まれています。
このパターンでは、モデルをトレーニングするコードが開発環境で開発されます。 同じコードがステージングに移行し、次に運用環境に移行します。 モデルは、モデル開発の一環として開発環境で最初に、統合テストの一部としてステージング (データの限られたサブセットで)、最終モデルを生成するための運用環境 (完全な運用データ) で、各環境でトレーニングされます。
利点:
運用データへのアクセスが制限されている組織では、このパターンを使用すると、運用環境の運用データでモデルをトレーニングできます。
自動モデル再トレーニングは、トレーニング コードがレビュー、テスト、および運用用に承認されるため、より安全です。
サポート コードは、モデル トレーニング コードと同じパターンに従います。 どちらもステージングで統合テストを受けます。
欠点:
データサイエンティストがコードをコラボレーターに引き継ぐための学習曲線は急になる可能性があります。 定義済みのプロジェクト テンプレートとワークフローが役立ちます。
また、このパターンでは、データサイエンティストは ML 固有の問題を特定して修正するための知識を持っているため、運用環境からのトレーニング結果を確認できる必要があります。
運用データセット全体に対するステージングでモデルをトレーニングする必要がある場合は、コードをステージングにデプロイし、モデルをトレーニングしてから、モデルを運用環境にデプロイすることで、ハイブリッド アプローチを使用できます。 このアプローチにより、運用環境のトレーニング コストは節約されますが、ステージングでは追加の運用コストが追加されます。
モデルをデプロイする
このパターンでは、モデル成果物は開発環境のトレーニング コードによって生成されます。 その後、成果物は本番運用にデプロイされる前にステージング環境でテストされます。
このオプションは、次のうち 1 つ以上が当てはまる場合に検討してください。
モデルのトレーニングは非常に高価であるか、再現が困難です。
すべての作業は、1 つの Databricks ワークスペースで行われます。
外部リポジトリまたは CI/CD プロセスを使用していない。
利点:
データサイエンティストのためのよりシンプルなハンドオフ
モデルのトレーニングにコストがかかる場合は、モデルを一度だけトレーニングする必要があります。
欠点:
開発環境から運用データにアクセスできない場合 (セキュリティ上の理由から、このアーキテクチャは実行可能ではない可能性があります)。
このパターンでは、自動モデルの再トレーニングが難しい場合があります。 開発環境での再トレーニングを自動化することはできますが、運用環境でのモデルのデプロイを担当するチームは、結果のモデルを運用環境対応として受け入れない場合があります。
特徴エンジニアリング、推論、モニタリングに使用されるパイプラインなどのサポート コードは、運用環境に個別にデプロイする必要があります。
通常、環境 (開発、ステージング、または本番運用) は、 Unity Catalogのカタログに対応します。 このパターンの実装方法の詳細については 、アップグレード ガイドを参照してください。
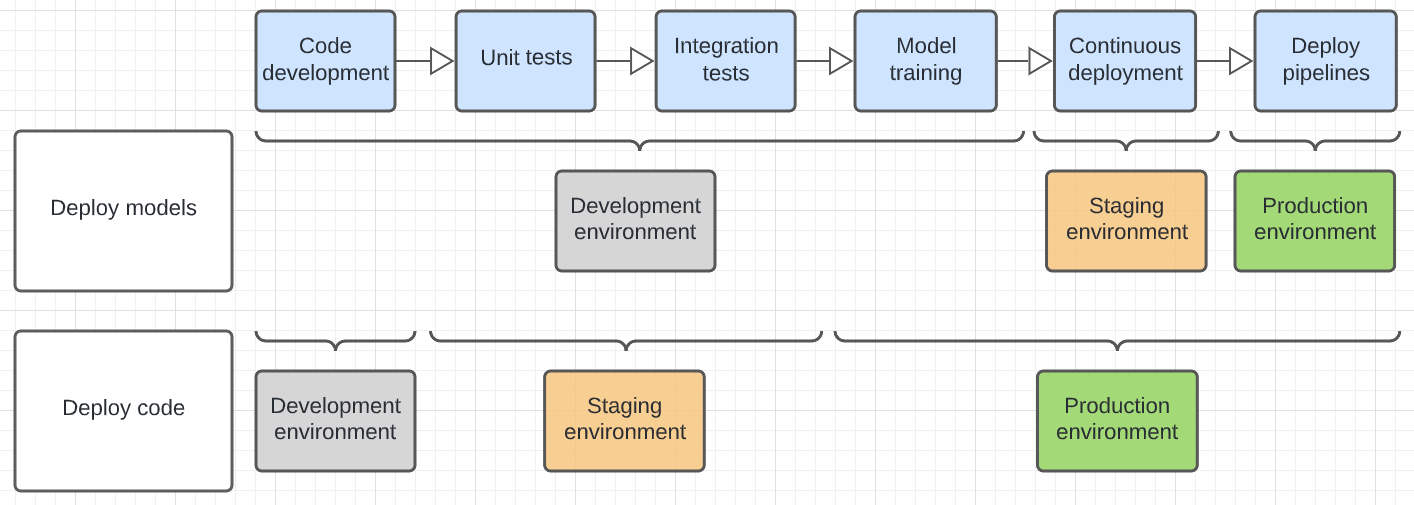
次の図は、さまざまな実行環境にわたる上記のデプロイ パターンのコード ライフサイクルを対比したものです。
図に示されている環境は、ステップが実行される最終的な環境です。 たとえば、モデルのデプロイ パターンでは、最終的な単体テストと統合テストが開発環境で実行されます。 配置コード パターンでは、単体テストと統合テストは開発環境で実行され、最終的な単体テストと統合テストはステージング環境で実行されます。