ディザスタリカバリ
明確なディザスタリカバリ パターンは、 Databricksなどのクラウドネイティブ データ分析プラットフォームにとって重要です。 ハリケーンや地震などの地域的な災害、またはその他の原因によって、地域全体のクラウド サービス プロバイダーが停止するというまれな事態が発生した場合でも、データ チームがDatabricksプラットフォームを使用できることが重要です。
Databricks 、上流のデータ取り込みサービス (バッチ/ストリーミング)、Google Google Cloud Storageインテリジェント アプリなどの下流のツールとサービス、オーケストレーション ツールなど、多くのサービスを含む全体的なデータ エコシステムの中核となることがよくあります。 一部のユースケースは、地域全体のサービス停止の影響を特に受けやすい場合があります。
この記事では、 Databricksプラットフォームの地域間ディザスタリカバリ ソリューションを成功させるための概念とベスト プラクティスについて説明します。
ディザスタリカバリの概要
ディザスタリカバリには、自然災害や人為的災害が発生した後に重要な技術インフラストラクチャとシステムを復旧または継続できるようにする一連のポリシー、ツール、および手順が含まれます。 Google Cloudのような大規模なクラウド サービスは、多くの顧客にサービスを提供しており、単一の障害に対しても防御力を発揮します。 たとえば、リージョンとは、単一の電源喪失によってリージョンがシャットダウンされないことを保証するため、異なる電源に接続された建物のグループです。 ただし、クラウド リージョンの障害が発生する可能性があり、その中断の程度と組織への影響はさまざまです。
ディザスタリカバリ計画を実施する前に、ディザスタリカバリ(DR) と高可用性(HA) の違いを理解することが重要です。
高可用性は、システムの回復力特性です。 高可用性は、通常、一貫したアップタイムまたはアップタイムの割合の観点から定義される最小レベルの運用パフォーマンスを保証します。 高可用性は、プライマリシステムの機能として設計することによって、(プライマリシステムと同じリージョンに)実装されます。 たとえば、Google Cloudのようなクラウド サービスにはGoogle Cloud Storageなどの高可用性 サービスがあります。 高可用性を実現するために、Databricks の顧客による特別な明示的な準備は必要ありません。
対照的に、ディザスタリカバリ計画では、重要なシステムのより大規模な地域的停止に対処するために、特定の組織に適した決定とソリューションが必要です。 この記事では、一般的なディザスタリカバリの用語、一般的なソリューション、およびDatabricksを使用したディザスタリカバリ プランのベスト プラクティスについて説明します。
用語
地域の用語
この記事では、リージョンに次の定義を使用します。
プライマリ リージョン: ユーザーが典型的な毎日のインタラクティブおよび自動データ分析ワークロードを実行する地理的リージョン。
セカンダリ リージョン: プライマリ リージョンの停止中に IT チームがデータ分析ワークロードを一時的に移動する地理的リージョン。
地理的に冗長化されたストレージ : Google Cloudには、非同期ストレージ GCSレプリケーション プロセスを使用して、永続化された バケット用の リージョン間で地理的に冗長化されたストレージ があります。
重要
ディザスタリカバリ プロセスの場合、 Databricksでは、Google Cloud アカウント内のワークスペースごとに Databricks が作成する 2 つのGCSバケットなど、データのリージョン間複製に地理的に冗長化Databricksれたストレージに依存しないことを推奨しています。 一般的に、 Deltaテーブルにはディープ クローンを使用し、可能であればデータをDelta形式に変換して、他のデータ形式でもディープ クローンを使用します。
展開状態の用語
この記事では、デプロイの状態の次の定義を使用します。
アクティブなデプロイメント: ユーザーは、Databricks ワークスペースのアクティブなデプロイメントに接続し、ワークロードを実行できます。 ジョブは、Databricks スケジューラまたはその他のメカニズムを使用して定期的にスケジュールされます。 このデプロイメントでもデータ ストリームを実行できます。 一部のドキュメントでは、アクティブな展開を ホット展開と呼ぶ場合があります。
パッシブ展開: パッシブ展開ではプロセスは実行されません。 IT チームは、コード、構成、およびその他の Databricks オブジェクトをパッシブ展開に展開するための自動化された手順を設定できます。 デプロイがアクティブになるのは、現在アクティブなデプロイがダウンしている場合 のみ です。 一部のドキュメントでは、パッシブ展開を コールド展開と呼ぶ場合があります。
重要
プロジェクトには、必要に応じて、異なるリージョンに複数のパッシブ デプロイを含めて、リージョンの停止を解決するための追加オプションを提供できます。
一般的に、アクティブ/パッシブディザスタリカバリ戦略では、チームには一度に 1 つのアクティブなデプロイメントしかありません。 あまり一般的ではないディザスタリカバリ ソリューション戦略として、アクティブ-アクティブと呼ばれるものがあります。この戦略では、2 つのアクティブなデプロイメントが同時に存在します。
ディザスタリカバリ業界用語
チームのために理解し、定義する必要がある 2 つの重要な業界用語があります。
リカバリポイント目標: リカバリポイント目標 (RPO) は、重大なインシデントにより IT サービスからデータ (トランザクション) が失われる可能性がある最大の目標期間です。 Databricks の展開では、主要な顧客データは保存されません。 これは、 Google Cloud Storageなどの別のシステムや、ユーザーが管理するその他のデータソースに保存されます。 Databricks コントロール プレーンは、ジョブやノートブックなどの一部のオブジェクトを部分的または全体的に保存します。 Databricks の場合、RPO は、ジョブやノートブックの変更などのオブジェクトが失われる可能性がある最大の目標期間として定義されます。 さらに、Google Cloud Storage または管理下にある他のデータソース内の独自の顧客データの RPO を定義する責任はお客様にあります。
目標復旧時間: 目標復旧時間 (RTO) は、災害発生後にビジネス プロセスを復旧するために必要な目標時間とサービス レベルです。
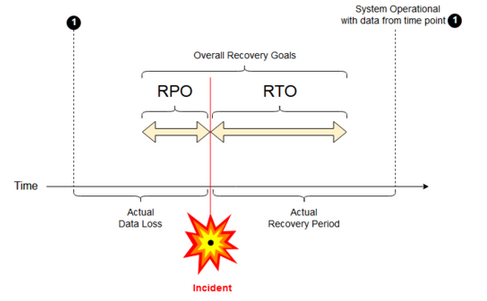
ディザスタリカバリとデータ破損
ディザスタリカバリ ソリューションでは、データ破損を軽減することはできません。 プライマリ リージョンの破損したデータは、プライマリ リージョンからセカンダリ リージョンにレプリケートされ、両方のリージョンで破損します。 この種の障害を軽減する方法は他にもあります。たとえば、 Deltaタイムトラベルなどです。
一般的な回復ワークフロー
Databricksリカバリのシナリオは、通常、次のように進行します。
プライマリ リージョンで使用する重要なサービスで障害が発生します。 これは、 Databricks展開に影響を与えるデータソース サービスまたはネットワークである可能性があります。
クラウドプロバイダーと状況を調査します。
プライマリ リージョンで問題が修復されるのを待つことができないと判断した場合は、セカンダリ リージョンへのフェールオーバーが必要であると判断できます。
同じ問題がセカンダリ リージョンにも影響しないことを確認します。
セカンダリ リージョンにフェールオーバーします。
ワークスペース内のすべてのアクティビティを停止します。 ユーザーがワークロードを停止します。 ユーザーまたは管理者は、可能であれば、最近の変更のバックアップを作成するように指示されます。 ジョブは、停止が原因でまだ失敗していない場合、シャットダウンされます。
セカンダリ リージョンで回復手順を開始します。 復旧手順では、セカンダリ リージョンへの接続とネットワーク トラフィックのルーティングと名前変更が更新されます。
テスト後、セカンダリ リージョンが操作可能であることを宣言します。 本番運用ワークロードを再開できるようになりました。 ユーザーは、現在アクティブな展開にログインできます。 スケジュールされたジョブや遅延されたジョブを再トリガーできます。
Databricksコンテキストでの詳細なステップについては、 「テスト フェールオーバー」を参照してください。
ある時点で、プライマリ リージョンの問題が軽減され、この事実を確認します。
プライマリ リージョンに復元 (フェールバック) します。
セカンダリ リージョンでのすべての作業を停止します。
プライマリ リージョンで回復手順を開始します。 回復手順では、接続とネットワーク トラフィックのルーティングと名前変更が処理され、プライマリ リージョンに戻されます。
必要に応じて、プライマリ リージョンにデータをレプリケートして戻します。 複雑さを軽減するには、レプリケートする必要があるデータの量を最小限に抑えます。 たとえば、セカンダリ デプロイメントで実行するときに一部のジョブが読み取り専用である場合、そのデータをプライマリ リージョンのプライマリ デプロイメントにレプリケートする必要がないことがあります。 ただし、実行する必要がある本番運用ジョブが 1 つあり、プライマリ リージョンへのデータ レプリケーションが必要になる場合があります。
プライマリ リージョンでデプロイをテストします。
プライマリ リージョンが運用可能であり、それがアクティブなデプロイであることを宣言します。 本番運用ワークロードを再開します。
プライマリ リージョンへの復元の詳細については、 「テスト復元 (フェイルバック)」を参照してください。
重要
これらのステップ中に、データ損失が発生する可能性があります。 組織では、許容できるデータ損失の量と、この損失を軽減するために何ができるかを定義する必要があります。
ステップ1: ビジネスニーズを理解する
最初のステップは、ビジネスニーズを定義して理解することです。 どのデータサービスが重要か、またそれらの予想されるRPO と RTO は何かを定義します。
各システムの実際の許容範囲を調査し、ディザスタリカバリのフェイルオーバーとフェイルバックにはコストがかかり、その他のリスクも伴うことに留意してください。 その他のリスクとしては、データの破損、間違った保存場所に書き込んだ場合のデータの重複、ユーザーがログインして間違った場所で変更を行うなどがあります。
ビジネスに影響するすべての Databricks 統合ポイントをマップします。
ディザスタリカバリ ソリューションでは、対話型プロセス、自動プロセス、またはその両方に対応する必要がありますか?
どのデータサービスを使用していますか? 一部はオンプレミスの場合もあります。
入力データはどのようにしてクラウドに送られるのでしょうか?
誰がこのデータを使用しますか? どのプロセスがダウンストリームでそれを消費しますか?
ディザスタリカバリの変更を認識する必要があるサードパーティ統合はありますか?
ディザスタリカバリ計画をサポートできるツールまたはコミュニケーション戦略を決定します。
ネットワーク構成をすばやく変更するために、どのようなツールを使用しますか?
ディザスタリカバリ ソリューションを自然かつ保守しやすい方法で収容できるように、構成を事前に定義してモジュール化できますか?
ディザスタリカバリのフェイルオーバーとフェイルバックの変更を社内チームとサードパーティ(統合、下流の消費者)に通知するコミュニケーション ツールとチャンネルはどれですか? そして、彼らの謝辞をどのように確認しますか?
どのようなツールや特別なサポートが必要ですか?
完全な復旧が完了するまで、どのようなサービスが停止されますか?
ステップ2: ビジネスニーズに合ったプロセスを選択する
ソリューションでは、コントロール プレーン、コンピュート プレーン、およびデータ ソースの両方で正しいデータを複製する必要があります。 ディザスタリカバリの冗長ワークスペースは、異なるリージョンの異なるコントロール プレーンにマップする必要があります。 同期ツールまたは CI/CD ワークフローのいずれかのスクリプトベースのソリューションを使用して、そのデータを定期的に同期する必要があります。 Databricks Runtimeワーカーなど、コンピュート プレーン ネットワーク自体の内部からデータを同期する必要はありません。
さらに、データソースが必要に応じてリージョン間で複製されるようにする必要があります。
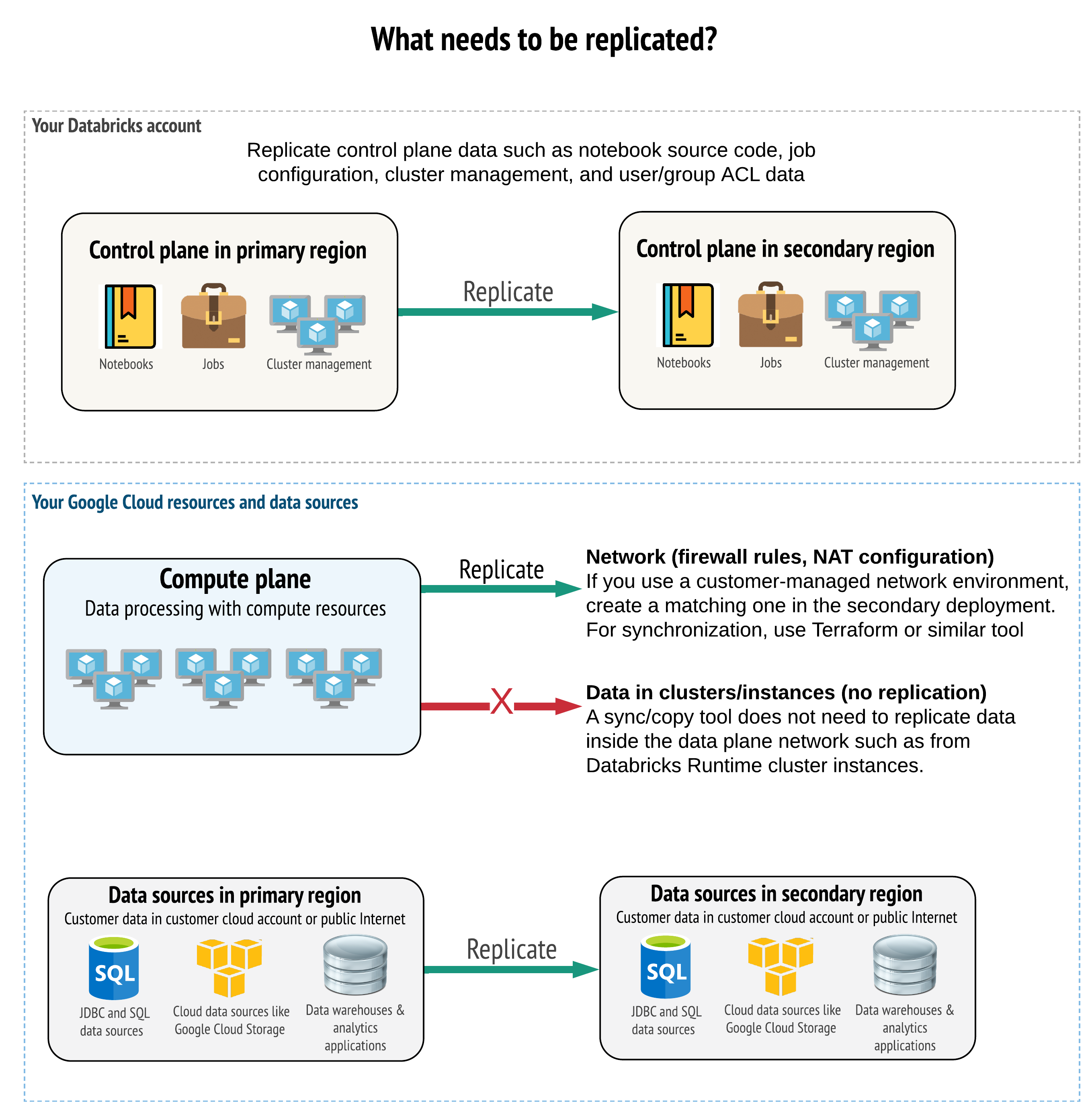
一般的なおすすめの方法
ディザスタリカバリ計画を成功させるための一般的なベストプラクティスは次のとおりです。
どのプロセスがビジネスにとって重要であり、ディザスタリカバリで実行する必要があるかを理解します。
関係するサービス、処理されるデータ、データフロー、保存場所を明確に特定する
サービスとデータを可能な限り分離します。 たとえば、ディザスタリカバリのデータ用に特別なクラウド ストレージ コンテナーを作成したり、災害時に必要となるDatabricksオブジェクトを別のワークスペースに移動したりします。
Databricks コントロール プレーンに保存されていないその他のオブジェクトについては、プライマリ展開とセカンダリ展開間の整合性を維持する責任はお客様にあります。
警告
ワークスペースの DBFS ルート アクセスに使用されるルート バケットにデータを保存 しない ことがベスト プラクティスです。GCSその DBFS ルート ストレージは本番運用顧客データではサポートされていません。 Databricks 、ライブラリ、構成ファイル、または init スクリプトをこの場所に保存しないことも推奨されています。
データソースについては、可能な場合は、レプリケーションと冗長性のためにネイティブの Google Cloud ツールを使用して、データをディザスタリカバリ リージョンに複製することをおすすめします。
回復ソリューション戦略を選択する
典型的なディザスタリカバリ ソリューションには、2 つ (またはそれ以上) のワークスペースが含まれます。 選択できる戦略はいくつかあります。 中断の潜在的な長さ (数時間または 1 日)、ワークスペースが完全に動作していることを確認するための労力、プライマリ リージョンに復元 (フェールバック) するための労力を考慮してください。
アクティブ・パッシブソリューション戦略
アクティブ/パッシブ ソリューションは最も一般的で最も簡単なソリューションであり、このタイプのソリューションがこの記事の焦点です。 アクティブ/パッシブ ソリューションは、アクティブ展開からパッシブ展開にデータとオブジェクトの変更を同期します。 必要に応じて、異なるリージョンに複数のパッシブ デプロイを行うこともできますが、この記事では、単一のパッシブ デプロイ アプローチに焦点を当てます。 ディザスタリカバリ イベント中は、セカンダリ リージョンのパッシブ デプロイメントがアクティブ デプロイメントになります。
この戦略には、主に 2 つのバリエーションがあります。
統合された (企業全体の) ソリューション: 組織全体をサポートするアクティブ展開とパッシブ展開の 1 セット。
部門またはプロジェクト別のソリューション: 各部門またはプロジェクト ドメインは、個別のディザスタリカバリ ソリューションを維持します。 一部の組織では、部門間でディザスタリカバリの詳細を切り離し、各チームの固有のニーズに基づいて、チームごとに異なるプライマリ リージョンとセカンダリ リージョンを使用したいと考えています。
読み取り専用のユースケースにパッシブデプロイを使用するなど、他のバリエーションもあります。 ユーザー クエリなどの読み取り専用のワークロードがある場合、データや、ノートブックやジョブなどの Databricks オブジェクトを変更しない限り、いつでもパッシブ ソリューションで実行できます。
アクティブ・アクティブソリューション戦略
アクティブ/アクティブ ソリューションでは、両方のリージョンのすべてのデータ プロセスを常に並行して実行します。 運用チームは、ジョブなどのデータ処理が両方のリージョンで正常に終了した場合にのみ完了としてマークされるようにする必要があります。 本番運用ではオブジェクトを変更することはできず、開発/ステージングから本番運用への厳格なCI/CDプロモーションに従う必要があります。
アクティブ/アクティブ ソリューションは最も複雑な戦略であり、ジョブが両方のリージョンで実行されるため、追加の財務コストが発生します。
アクティブ/パッシブ戦略と同様に、これを統合組織ソリューションとして、または部門ごとに実装できます。
ワークフローによっては、すべてのワークスペースに対してセカンダリ システムに同等のワークスペースが必要ない場合もあります。 たとえば、開発ワークスペースやステージングワークスペースでは複製が必要ない場合があります。 適切に設計された開発パイプラインを使用すると、必要に応じてそれらのワークスペースを簡単に再構築できる可能性があります。
ツールの選択
プライマリ リージョンとセカンダリ リージョンのワークスペース間でデータを可能な限り類似した状態に保つツールには、主に 2 つのアプローチがあります。
プライマリからセカンダリにコピーする同期クライアント: 同期クライアントは、プライマリ リージョンからセカンダリ リージョンに本番運用データとアセットをプッシュします。 通常、これはスケジュールに従って実行されます。
並列デプロイメント用のCI/CDツール: 本番運用コードとアセットの場合は、本番運用システムへの変更を両方のリージョンに同時にプッシュするCI/CDツールを使用してください。 たとえば、コードとアセットをステージング/開発から本番運用にプッシュする場合、 CI/CDシステムにより、両方のリージョンで同時に利用できるようになります。 基本的な考え方は、 Databricksワークスペース内のすべての成果物をInfrastructure-as-Codeとして扱うことです。 ほとんどのアーティファクトはプライマリ ワークスペースとセカンダリ ワークスペースの両方に同時にデプロイできますが、一部のアーティファクトはディザスタリカバリ イベントの後にのみデプロイする必要がある場合があります。 ツールについては 、「自動化スクリプト、サンプル、プロトタイプ」を参照してください。
次の図は、これら 2 つのアプローチを対比したものです。
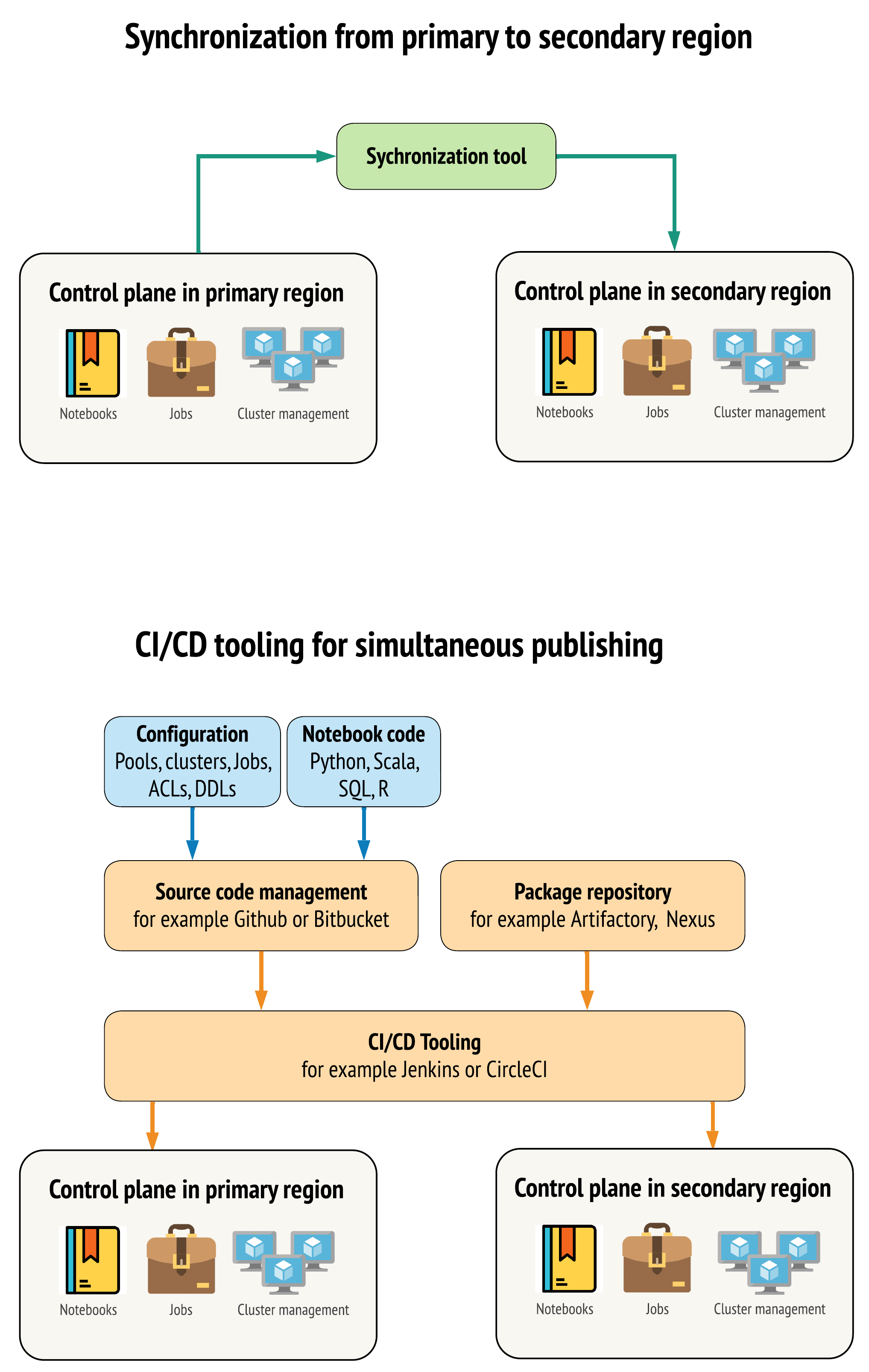
ニーズに応じて、アプローチを組み合わせることができます。 たとえば、ノートブックのソース コードには CI/CD を使用し、プールやアクセス制御などの構成には同期を使用します。
次の表は、各ツール オプションでさまざまな種類のデータを処理する方法を示しています。
説明 |
CI/CDツールでの処理方法 |
同期ツールでの処理方法 |
|---|---|---|
ソースコード: ライブラリ ソースエクスポートとパッケージ化されたライブラリのソースコード |
プライマリとセカンダリの両方に共同デプロイします。 |
プライマリからセカンダリにソース コードを同期します。 |
ユーザーとグループ |
Git でメタデータを構成として管理します。 または、両方のワークスペースに同じ ID プロバイダー (IdP) を使用します。 ユーザーとグループのデータをプライマリ展開とセカンダリ展開に共同展開します。 |
両方のリージョンでSCIMまたはその他の自動化を使用します。 手動で作成することはお勧め しません が、使用する場合は両方に対して同時に行う必要があります。 手動セットアップを使用する場合は、スケジュールされた自動プロセスを作成して、2 つの展開間でユーザーとグループのリストを比較します。 |
プールの構成 |
Git のテンプレートにすることができます。 プライマリとセカンダリに共同デプロイします。 ただし、ディザスタリカバリイベントまではセカンダリの |
API または CLI を使用してセカンダリ ワークスペースに同期されるときに、任意の |
ジョブ構成 |
Git のテンプレートにすることができます。 プライマリ展開の場合は、ジョブ定義をそのまま展開します。 セカンダリデプロイメントの場合は、ジョブをデプロイし、同時実行数をゼロに設定します。 これにより、このデプロイメント内のジョブが無効になり、追加の実行が防止されます。 コンカレンシー値は、セカンダリ デプロイがアクティブになった後に変更します。 |
何らかの理由でジョブが既存の |
アクセス制御リスト (ACL) |
Git のテンプレートにすることができます。 ノートブック、フォルダー、クラスターのプライマリ展開とセカンダリ展開に共同展開します。 ただし、ジョブのデータはディザスタリカバリイベントまで保持してください。 |
Permissions API を使用すると、クラスター、ジョブ、プール、ノートブック、フォルダーのアクセス制御を設定できます。 同期クライアントは、セカンダリ ワークスペース内の各オブジェクトの対応するオブジェクト ID にマップする必要があります。 Databricks では、アクセス制御を複製する前に、オブジェクトを同期しながらプライマリ ワークスペースからセカンダリ ワークスペースへのオブジェクト ID のマップを作成することをお勧めします。 |
ライブラリ |
ソース コードとクラスター/ジョブ テンプレートに含めます。 |
集中リポジトリ、DBFS、またはクラウド ストレージ (マウント可能) からカスタム ライブラリを同期します。 |
必要に応じてソース コードに含めます。 |
同期を簡単にするために、可能であれば、init スクリプトを共通フォルダー内のプライマリ ワークスペースまたは少数のフォルダーに保存します。 |
|
マウント・ポイント |
ノートブックベースのジョブまたはコマンド APIを通じてのみ作成された場合は、ソース コードに含めます。 |
ジョブを使用します。 ワークスペースが異なるリージョンにある場合、ストレージ エンドポイントが変更される可能性があることに注意してください。 これは、データ ディザスタリカバリ戦略にも大きく依存します。 |
テーブル メタデータ |
ノートブックベースのジョブまたはコマンド APIを通じてのみ作成された場合は、ソース コードに含めます。 これは、内部 Databricks メタストアと外部構成メタストアの両方に適用されます。 |
Spark Catalog APIを使用するか、ノートブックまたはスクリプトを使用してテーブルの作成を表示し、メタストア間のメタデータ定義を比較します。 基になるストレージのテーブルはリージョンベースにすることができ、メタストア インスタンス間で異なることに注意してください。 |
シークレット |
コマンド APIを通じてのみ作成された場合はソース コードに含めます。 一部のシークレットコンテンツは、プライマリとセカンダリの間で変更する必要があることに注意してください。 |
シークレットは、API を介して両方のワークスペースに作成されます。 一部のシークレットコンテンツは、プライマリとセカンダリの間で変更する必要があることに注意してください。 |
クラスター構成 |
Git のテンプレートにすることができます。 プライマリデプロイメントとセカンダリデプロイメントに共存しますが、セカンダリデプロイメント内のデプロイメントはディザスタリカバリイベントまで終了する必要があります。 |
クラスターは、API または CLI を使用してセカンダリ ワークスペースに同期された後に作成されます。 これらは、自動終了設定に応じて、必要に応じて明示的に終了できます。 |
ノートブック、ジョブ、フォルダの権限 |
Git のテンプレートにすることができます。 プライマリとセカンダリのデプロイに共同デプロイします。 |
Permissions APIを使用して複製します。 |
地域と複数のセカンダリワークスペースを選択する
ディザスタリカバリトリガーを完全に制御する必要があります。 これは、いつでも、いかなる理由でもトリガーできます。 フェイルバック(通常の本番運用)モードで運用を再開する前に、ディザスタリカバリの安定化に責任を持つ必要があります。 通常、これは、本番運用とディザスタリカバリのニーズに対応するために複数のDatabricksワークスペースを作成し、セカンダリ フェールオーバー リージョンを選択する必要があることを意味します。
Google Cloudでは、選択したセカンダリ リージョンを完全に制御できます。 すべてのリソースと製品がそのリージョンで利用可能であることを確認します。 一部のDatabricksサービスは、一部のGoogle Cloud リージョンでのみご利用いただけます。
ステップ 3: ワークスペースを準備し、1回限りのコピーを実行する
ワークスペースがすでに本番運用中の場合は、通常、1 回限りのコピー操作を実行して、パッシブなデプロイメントをアクティブなデプロイメントと同期します。 この 1 回限りのコピーでは、次の処理が行われます。
データ レプリケーション: クラウド レプリケーション ソリューションまたは Delta Deep Clone 操作を使用してレプリケートします。
トークン生成: トークン生成を使用して、レプリケーションと将来のワークロードを自動化します。
ワークスペース レプリケーション:ステップ 4: データ ソースの準備で説明されている方法を使用して、ワークスペースレプリケーションを使用します。
ワークスペースの検証: - ワークスペースとプロセスが正常に実行され、期待どおりの結果が得られるかを確認するためのテスト。
最初の 1 回限りのコピー操作の後、後続のコピーと同期のアクションはより高速になり、ツールからのログは、変更内容と変更日時のログにもなります。
ステップ4: データソースを準備する
Databricks 、バッチ処理またはデータ ストリームを使用して、さまざまなデータ ソースを処理できます。
データソース用のシステムを実装する前に、 GCSとBigQueryのレプリケーションの違いを理解することが重要です。
BigQuery の場合、データは複製されます。 破損したデータは、最大 7 日間回復できます (バックアップがない場合)。
Delta Lake を使用する GCS の場合、レプリケーションは、シングル、デュアル、マルチなどのバケット タイプによって異なります。 破損したデータは、 Vacuum の保持期間に応じて回復できます。
データソースからのバッチ処理
データがバッチで処理される場合、通常、そのデータは簡単に複製したり別のリージョンに配信したりできるデータソースに存在します。
たとえば、データは定期的にクラウド ストレージの場所にアップロードされる場合があります。 セカンダリ リージョンのディザスタリカバリ モードでは、ファイルがセカンダリ リージョン ストレージにアップロードされるようにする必要があります。 ワークロードは、セカンダリ リージョン ストレージを読み取り、セカンダリ リージョン ストレージに書き込む必要があります。
データストリーム
データ ストリームの処理はさらに大きな課題です。 ストリーミング データはさまざまなソースから取り込まれ、処理されてストリーミング ソリューションに送信できます。
KafkaやPub/Sub Liteなどのメッセージキュー
データベース チェンジデータ キャプチャ ストリーム
ファイルベースの連続処理
ファイルベースのスケジュールされた処理 (トリガー ワンスとも呼ばれます)
これらすべてのケースでは、ディザスタリカバリ モードを処理し、セカンダリ リージョンでセカンダリ デプロイメントを使用するようにデータソースを構成する必要があります。
ストリーム ライターは、処理されたデータに関する情報を含むチェックポイントを保存します。 このチェックポイントには、ストリームを正常に再開するために新しい場所に変更する必要があるデータの場所 (通常はクラウド ストレージ) が含まれる場合があります。 たとえば、チェックポイントの下のsourceサブフォルダーには、ファイルベースのクラウド フォルダーが格納されている場合があります。
このチェックポイントは、適切なタイミングでレプリケートする必要があります。 新しいクラウド レプリケーション ソリューションでは、チェックポイント間隔の同期を検討してください。
チェックポイントの更新はライターの機能であるため、データ ストリームの取り込みや、別のストリーミング ソースでの処理と保存に適用されます。
ストリーミング ワークロードの場合、最後の障害発生時点からワークロードを再開できるように、チェックポイントが顧客管理ストレージに構成されていることを確認します。 プライマリ プロセスと並行してセカンダリ ストリーミング プロセスを実行することもできます。
ステップ5: ソリューションを実装してテストする
ディザスタリカバリのセットアップを定期的にテストして、正しく機能することを確認します。 必要なときに使用できないのであれば、ディザスタリカバリ ソリューションを維持しても意味がありません。 一部の企業は、数か月ごとに地域を切り替えます。 定期的なスケジュールでリージョンを切り替えると、前提条件とプロセスがテストされ、復旧のニーズが満たされていることが確認されます。 これにより、組織が緊急事態に関するポリシーと手順に精通していることも保証されます。
重要
ディザスタリカバリ ソリューションを実際の状況で定期的にテストします。
オブジェクトまたはテンプレートが不足していることがわかり、プライマリ ワークスペースに保存されている情報に依拠する必要がある場合は、計画を変更してこれらの障害を取り除き、この情報をセカンダリ システムに複製するか、他の方法で利用できるようにします。
プロセスと一般的な構成に必要な組織的な変更をテストします。 ディザスタリカバリ計画はデプロイメント パイプラインに影響を与えるため、チームが何を同期させる必要があるかを把握することが重要です。 ディザスタリカバリ ワークスペース をセットアップした後、インフラストラクチャ (手動またはコード)、ジョブ、ワークスペース、ライブラリ、およびその他の ワークスペース オブジェクトがセカンダリ リージョンで使用可能であることを確認する必要があります。
標準の作業プロセスと構成パイプラインを拡張して、すべてのワークスペースに変更を展開する方法についてチームと話し合ってください。 すべてのワークスペースでユーザー ID を管理します。 新しいワークスペース用に、ジョブ自動化やモニタリングなどのツールを設定することを忘れないでください。
構成ツールの変更を計画し、テストします。
取り込み: データソースがどこにあり、それらのソースがデータをどこから取得するかを理解します。 可能な場合は、ソースをパラメーター化し、セカンダリ デプロイメントとセカンダリ リージョンを操作するための別の構成テンプレートがあることを確認します。 フェールオーバーの計画を準備し、すべての前提条件をテストします。
実行の変更: ジョブやその他のアクションをトリガーするスケジューラがある場合は、セカンダリデプロイメントまたはそのデータソースで動作する別のスケジューラを構成する必要がある場合があります。 フェールオーバーの計画を準備し、すべての前提条件をテストします。
インタラクティブな接続: REST APIs 、 CLIツール、 JDBC / ODBCなどのその他のサービスを使用する場合、地域的な混乱によって構成、認証、ネットワーク接続がどのように影響を受けるかを検討します。 フェールオーバーの計画を準備し、すべての前提条件をテストします。
自動化の変更: すべての自動化ツールについて、フェールオーバーの計画を準備し、すべての前提条件をテストします。
出力: 出力データまたはログを生成するツールについては、フェールオーバーの計画を準備し、すべての前提条件をテストします。
テストのフェールオーバー
ディザスタリカバリはさまざまなシナリオによって起動できます。 予期せぬ中断によって引き起こされる可能性があります。 クラウド ネットワーク、クラウド ストレージ、その他のコア サービスなど、一部のコア機能がダウンしている可能性があります。 システムを正常にシャットダウンするためのアクセス権がないため、回復を試みる必要があります。 ただし、このプロセスは、シャットダウンや計画的な停止によって、あるいは 2 つのリージョン間でアクティブなデプロイを定期的に切り替えることによってトリガーされる可能性があります。
フェイルオーバーをテストするときは、システムに接続してシャットダウン プロセスを実行します。 すべてのジョブが完了し、クラスターが終了していることを確認します。
同期クライアント (または CI/CD ツール) は、関連する Databricks オブジェクトとリソースをセカンダリ ワークスペースに複製できます。 セカンダリ ワークスペースをアクティブ化するには、次のプロセスの一部またはすべてを実行する必要があります。
テストを実行して、プラットフォームが最新であることを確認します。
プライマリ リージョンのプールとクラスターを無効にして、障害が発生したサービスがオンラインに戻った場合にプライマリ リージョンが新しいデータの処理を開始しないようにします。
回復プロセス:
最新の同期データの日付を確認します。 ディザスタリカバリの業界用語を参照してください。 このステップの詳細は、データの同期方法と固有のビジネス ニーズによって異なります。
データソースを安定させ、すべてが利用可能であることを確認します。 Google CloudSQL 、 BigQuery 、Pub/Sub などのすべての外部データソースと、 Delta Lake 、 Parquet 、その他のファイルを含めます。
ストリーミング回復ポイントを見つけます。 そこから再開するプロセスを設定し、潜在的な重複を識別して排除するプロセスを準備します (Delta Lake を使用すると、これが簡単になります)。
データフロープロセスを完了し、ユーザーに通知します。
関連するプールを開始します (または、
min_idle_instancesを関連する数に増やします)。関連するクラスターを起動します (終了していない場合)。
ジョブの並列実行と関連するジョブの実行を変更します。 これらは、1 回限りの実行または定期的な実行である可能性があります。
Databricksワークスペースの URL またはドメイン名を使用する外部ツールの場合は、新しいコントロール プレーンの アカウント に構成を更新します。 たとえば、 REST APIsおよびJDBC / ODBC接続の URL を更新します。 コントロール プレーンが変更されると、Databricks Web アプリケーションの顧客向け URL も変更されるため、組織のユーザーに新しい URL を通知します。
テスト復元 (フェールバック)
フェールバックは制御が容易で、メンテナンス期間内に実行できます。 このプランには、次の一部またはすべてを含めることができます。
プライマリ リージョンが復元されたことの確認を取得します。
新しいデータの処理が開始されないように、セカンダリ リージョンのプールとクラスターを無効にします。
セカンダリ ワークスペース内の新規または変更されたアセットをプライマリ デプロイメントに同期します。 フェイルオーバー スクリプトの設計によっては、同じスクリプトを実行して、セカンダリ (ディザスタリカバリ) リージョンからプライマリ (本番運用) リージョンにオブジェクトを同期できる場合があります。
新しいデータ更新をプライマリ展開に同期します。 ログとDeltaテーブルの監査証跡を使用して、データが失われないことを保証できます。 一部の管理対象データソースでは、自動ログインを使用した回復の時間枠が限られていることに注意してください。 たとえば、Google BigQuery ではデータの復元に 7 日間の制限があります。
ディザスタリカバリ領域内のすべてのワークロードをシャットダウンします。
ジョブとユーザーの URL をプライマリ リージョンに変更します。
テストを実行して、プラットフォームが最新であることを確認します。
関連するプールを開始します (または
min_idle_instancesを適切な数に増やします)。関連するクラスターを起動します (終了していない場合)。
ジョブの並列実行を変更し、関連するジョブを実行します。 これらは、1 回限りの実行または定期的な実行である可能性があります。
必要に応じて、将来のディザスタリカバリのためにセカンダリ リージョンを再度設定します。
自動化スクリプト、サンプル、プロトタイプ
ディザスタリカバリ プロジェクトで検討すべき自動化スクリプト:
Databricks では、独自の同期プロセスを開発するためにDatabricks Terraform プロバイダーを使用することをお勧めします。
サンプルの自動化およびプロトタイプ スクリプトについては、 Databricks Workspace移行ツールも参照してください。
Databricks Sync (DBSync)プロジェクトは、Databricks ワークスペースをバックアップ、復元、同期するオブジェクト同期ツールです。