Apache Kafka と Databricks によるストリーム処理
この記事では、Databricks 上で構造化ストリーミングワークロードを実行する際に、Apache Kafka をソースまたはシンクとして使用する方法について説明します。
Kafkaの詳細については、 Kafkaのドキュメントを参照してください。
Kafka からデータを読み取る
以下に、Kafkaからのストリーミング読み込みの例を挙げています。
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "latest")
.load()
)
以下の例の通り、Databricksは、Kafka データソースのバッチ読み込みのセマンティクスもサポートしています。
df = (spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
)
増分バッチ読み込みの場合、Databricks では Kafka と Trigger.AvailableNow. 増分バッチ処理の構成を参照してください。
Databricks Runtime 13.3 LTS 以降では、Databricks は Kafka データを読み取るための SQL 関数を提供します。 SQLを使用したストリーミングはDelta Live TablesまたはDatabricks SQLのストリーミング テーブルでのみサポートされます。 「 テーブル値関数read_kafka」を参照してください。
Kafka構造化ストリーミングリーダーの構成
Databricks は、Kafka 0.10 以降への接続を構成するためのデータ形式として kafka キーワードを提供しています。
Kafka の最も一般的な構成を以下に示します。
サブスクライブするトピックを指定する方法は複数あります。次のパラメーターの 1 つのみを指定する必要があります。
オプション |
値 |
説明 |
|---|---|---|
subscribe |
トピックのコンマ区切りリスト |
サブスクライブするトピックのリストです。 |
subscribePattern |
Javaの正規表現文字列 |
トピックをサブスクライブするのに使われるパターンです。 |
assign |
JSON 文字列 |
コンシュームする特定の topicPartitions です。 |
その他の注目すべき構成:
オプション |
値 |
デフォルト値 |
説明 |
|---|---|---|---|
kafka.bootstrap.servers |
host:port のコンマ区切りリスト |
値がありません |
[必須] Kafka の |
failOnDataLoss |
|
|
[任意] データが失われた可能性がある場合にクエリーを失敗させるかどうか:トピックの削除、処理前のトピックの切り捨てなど、多くのシナリオが原因で、クエリーは Kafka からのデータの読み取りに永久に失敗する可能性があります。データが失われた可能性があるかどうかを保守的に見積もるようになっています。これにより、誤警報が引き起こされる場合があります。期待どおりに動作しない場合、またはデータが失われていてもクエリーの処理を継続したい場合は、このオプションを |
minPartitions |
整数 > = 0、0 = 無効 |
0 (無効) |
[オプション] Kafka から読み取るパーティションの最小数。 |
kafka.group.id |
Kafka コンシューマーグループの ID |
設定されていません |
[オプション] Kafka からの読み取り中に使用するグループ ID。これは注意して使用してください。デフォルトでは、各クエリはデータを読み取るための一意のグループ ID を生成します。これにより、各クエリには他のコンシューマからの干渉を受けない独自のコンシューマグループが確保され、サブスクライブされたトピックのすべてのパーティションを読み取ることができます。一部のシナリオ(Kafka グループベースの承認など)では、特定の承認されたグループ ID を使用してデータを読み取ることが必要な場合があります。必要に応じて、グループ ID を設定することができます。ただし、予期しない動作が発生する可能性があるため、細心の注意を払って実行してください。
|
startingOffsets |
earliest、latest |
latest |
[オプション] クエリが開始されるときの開始点。最も古いオフセットからの「earliest」、または各 TopicPartition の開始オフセットを指定する JSON 文字列のいずれかです。json では、オフセットとして -2 を使用して最も古いものを参照し、-1 を使用して最新のものを参照できます。注:バッチクエリの場合、latest(暗黙的または json で -1 を使用) は許可されません。ストリーミングクエリの場合、これは新しいクエリが開始された場合にのみ適用され、再開は常にクエリが中断したところから再開されます。クエリ中に新しく検出されたパーティションは、できるだけ早く開始されます。 |
他のオプションの構成については、Structured Streaming Kafka Integration Guide を参照してください。
Kafka レコードのスキーマ
Kafka レコードのスキーマは次のとおりです。
列 |
タイプ |
|---|---|
キー |
binary |
値 |
binary |
topic |
string |
パーティション |
int |
offset |
long |
timestamp |
long |
timestampType |
int |
key と value は常に、ByteArrayDeserializer を持つバイト配列として逆シリアル化されます。DataFrame 操作(cast("string")など)を使用して、キーと値を明示的に逆シリアル化します。
Kafka へのデータの書き込み
以下は、Kafka へのストリーミング書き込みの例です:
(df
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.start()
)
Databricks は、次の例に示すように、Kafka データシンクへのバッチ書き込みセマンティクスもサポートしています。
(df
.write
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.save()
)
Kafka 構造化ストリーミング ライターの構成
重要
Databricks Runtime 13.3 LTS 以降には、デフォルトでべき等書き込みを有効にするkafka-clientsライブラリの新しいバージョンが含まれています。 Kafka シンクがバージョン 2.8.0 以下を使用し、ACL が設定されているがIDEMPOTENT_WRITEが有効になっていない場合、書き込みは失敗し、エラー メッセージorg.apache.kafka.common.KafkaException: Cannot execute transactional method because we are in an error stateが表示されます。
このエラーを解決するには、Kafka バージョン 2.8.0 以降にアップグレードするか、構造化ストリーミング ライターの構成時に.option(“kafka.enable.idempotence”, “false”)を設定します。
DataStreamWriter に提供されたスキーマは、Kafka シンクと対話します。次のフィールドを使用することができます。
列名 |
必須またはオプション |
タイプ |
|---|---|---|
|
オプション |
|
|
必須 |
|
|
オプション |
|
|
オプション( |
|
|
オプション |
|
以下は、Kafka への書き込み時に設定される一般的なオプションです。
オプション |
値 |
デフォルト値 |
説明 |
|---|---|---|---|
|
カンマで区切られたリスト |
なし |
[必須] Kafka の |
|
|
設定されていません |
[オプション] 書き込まれるすべての行のトピックを設定します。このオプションは、データに存在するすべてのトピック列よりも優先されます。 |
|
|
|
[オプション] Kafka ヘッダーを行に含めるかどうか。 |
他のオプションの構成については、Structured Streaming Kafka Integration Guide を参照してください。
Kafka メトリクスの取得
avgOffsetsBehindLatest 、 maxOffsetsBehindLatest 、および minOffsetsBehindLatest メトリクスを使用して、サブスクライブされたすべてのトピック間で、ストリーミングクエリが利用可能な最新のオフセットよりも遅れているオフセット数の平均、最小、最大を取得できます。メトリクスをインタラクティブに読み取るを参照ください。
注:
Databricks Runtime 9.1 以降で利用可能です。
estimatedTotalBytesBehindLatest の値を調べて、クエリプロセスがサブスクライブされたトピックから消費しなかった推定合計バイト数を取得します。この推定値は、過去 300 秒間に処理されたバッチに基づきます。推定の基準となる時間枠は、オプション bytesEstimateWindowLength を別の値に設定することで変更できます。たとえば、10 分に設定するには、次のようにします。
df = (spark.readStream
.format("kafka")
.option("bytesEstimateWindowLength", "10m") # m for minutes, you can also use "600s" for 600 seconds
)
ノートブックでストリームを実行している場合、ストリーミングクエリの進行状況ダッシュボードの 生データタブに次のメトリクスが表示されます。
{
"sources" : [ {
"description" : "KafkaV2[Subscribe[topic]]",
"metrics" : {
"avgOffsetsBehindLatest" : "4.0",
"maxOffsetsBehindLatest" : "4",
"minOffsetsBehindLatest" : "4",
"estimatedTotalBytesBehindLatest" : "80.0"
},
} ]
}
SSL を使用して Databricks を Kafka に接続する
Kafka への SSL 接続を有効にするには、Confluent ドキュメントEncryption and Authentication with SSLの説明に従ってください。ここで説明されている構成を、接頭辞 kafka.を付けてオプションとして指定できます。たとえば、プロパティ kafka.ssl.truststore.location でトラストストアの場所を指定します。
Databricks では、次のことをお勧めします。
証明書をクラウドオブジェクトストレージに保存します。 証明書へのアクセスを、Kafka にアクセスできるクラスターのみに制限できます。 Unity Catalogによるデータガバナンスを参照してください。
証明書のパスワードをシークレットとしてシークレットスコープに保存します。
次の例では、オブジェクトストレージの場所と Databricks シークレットを使用して SSL 接続を有効にします。
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<truststore-password-key-name>))
)
Microsoft Entra ID と Azure Event Hubsを使用したサービスプリンシパル認証
Databricks は、Event Hubs サービスを使用した Spark ジョブの認証をサポートしています。 この認証は、Microsoft Entra ID を使用した OAuth 経由で行われます。
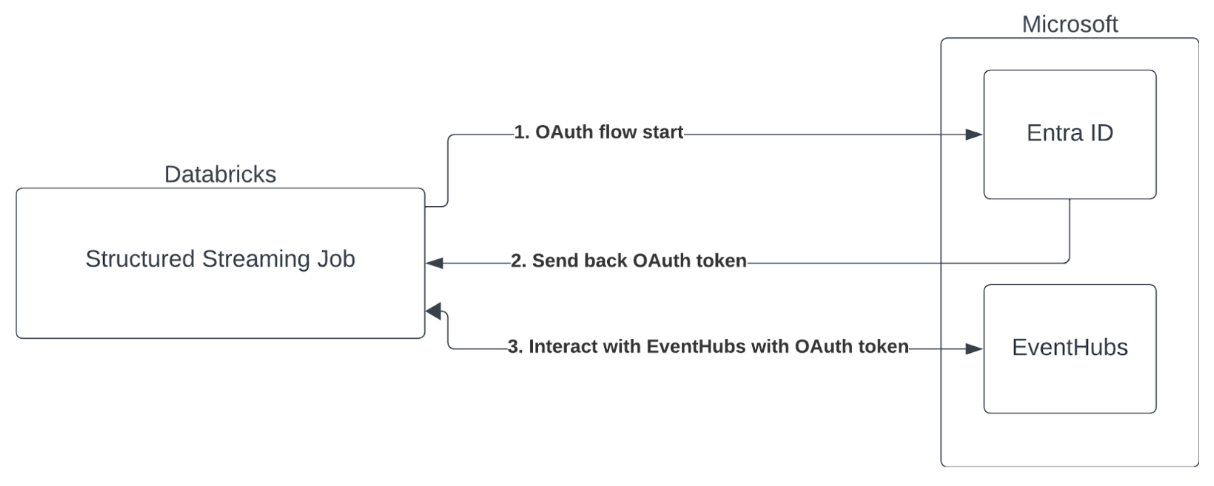
Databricks では、次のコンピュート環境で、クライアント ID とシークレットを使用した Microsoft Entra ID 認証がサポートされています。
Databricks Runtime 12.2 LTS 以降 (シングル ユーザー アクセス モードで構成されたコンピュート)。
Databricks Runtime 14.3 LTS 以降 (共有アクセス モードで構成されたコンピュート)。
Unity Catalog を使用せずに構成された Delta Live Tables パイプライン。
Databricks では、コンピュート環境、または Unity Catalog で構成された Delta Live Tables パイプラインで、証明書を使用した Microsoft Entra ID 認証はサポートされていません。
この認証は、共有クラスターまたは Unity Catalog Delta Live Tables では機能しません。
構造化ストリーミングKafka コネクターの構成
Microsoft Entra ID で認証を実行するには、次の値が必要です。
テナント ID。 これは、 Microsoft Entra ID サービス タブにあります。
clientID (アプリケーション ID とも呼ばれます)。
クライアント シークレット。 これを入手したら、シークレットとして追加する必要があります Databricks Workspace。 このシークレットを追加するには、シークレット管理を参照してください。
EventHubs トピック。 トピックの一覧は、特定の Event Hubs 名前空間ページの エンティティセクションのEvent Hubsセクションにあります。複数のトピックを操作するには、Event Hubs レベルで IAMロールを設定します。
EventHubs サーバー。 これは、特定の Event Hubs 名前空間の概要ページで確認できます。
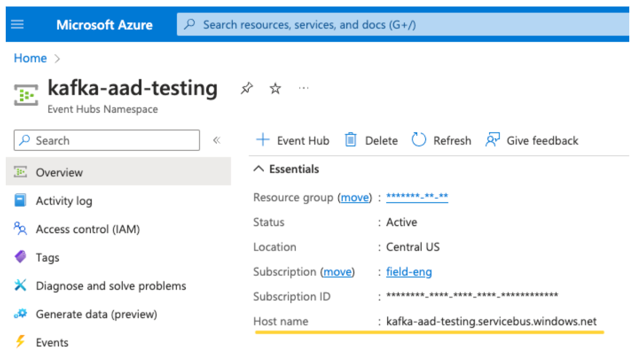
さらに、Entra ID を使用するには、OAuth SASL メカニズムを使用するように Kafka に指示する必要があります (SASL は汎用プロトコルであり、OAuth は SASL の「メカニズム」の一種です)。
kafka.security.protocolは右の値である必要がありますSASL_SSLkafka.sasl.mechanismは右の値である必要がありますOAUTHBEARERkafka.sasl.login.callback.handler.classは、影付きの Kafka クラスのログインコールバックハンドラーに対してkafkashadedの値を持つ Java クラスの完全修飾名である必要があります。 正確なクラスについては、次の例を参照してください。
例
次に、実行中の例を見てみましょう。
# This is the only section you need to modify for auth purposes!
# ------------------------------
tenant_id = "..."
client_id = "..."
client_secret = dbutils.secrets.get("your-scope", "your-secret-name")
event_hubs_server = "..."
event_hubs_topic = "..."
# -------------------------------
sasl_config = f'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="{client_id}" clientSecret="{client_secret}" scope="https://{event_hubs_server}/.default" ssl.protocol="SSL";'
kafka_options = {
# Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers": f"{event_hubs_server}:9093",
"kafka.sasl.jaas.config": sasl_config,
"kafka.sasl.oauthbearer.token.endpoint.url": f"https://login.microsoft.com/{tenant_id}/oauth2/v2.0/token",
"subscribe": event_hubs_topic,
# You should not need to modify these
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class": "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
}
df = spark.readStream.format("kafka").options(**kafka_options)
display(df)
// This is the only section you need to modify for auth purposes!
// -------------------------------
val tenantId = "..."
val clientId = "..."
val clientSecret = dbutils.secrets.get("your-scope", "your-secret-name")
val eventHubsServer = "..."
val eventHubsTopic = "..."
// -------------------------------
val saslConfig = s"""kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="$clientId" clientSecret="$clientSecret" scope="https://$eventHubsServer/.default" ssl.protocol="SSL";"""
val kafkaOptions = Map(
// Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers" -> s"$eventHubsServer:9093",
"kafka.sasl.jaas.config" -> saslConfig,
"kafka.sasl.oauthbearer.token.endpoint.url" -> s"https://login.microsoft.com/$tenantId/oauth2/v2.0/token",
"subscribe" -> eventHubsTopic,
// You should not need to modify these
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class" -> "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
)
val scalaDF = spark.readStream
.format("kafka")
.options(kafkaOptions)
.load()
display(scalaDF)
潜在的なエラーの処理
ストリーミング オプションはサポートされていません。
Unity Catalog で構成された Delta Live Tables パイプラインでこの認証メカニズムを使用しようとすると、次のエラーが表示されることがあります。
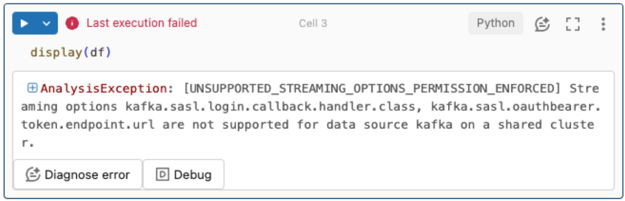
このエラーを解決するには、サポートされているコンピュート構成を使用します。 「 Microsoft Entra ID とAzure Event Hubs を使用したサービスシプリンパル認証」を参照してください。
新しい
KafkaAdminClientを作成できませんでした。これは、次の認証オプションのいずれかが正しくない場合に Kafka がスローする内部エラーです。
クライアント ID (アプリケーション ID とも呼ばれます)
テナント ID
EventHubs サーバー
このエラーを解決するには、これらのオプションの値が正しいことを確認します。
また、この例でデフォルトで提供されている設定オプション(変更しないように求められている設定オプション)を変更した場合にも、このエラーが表示されることがあります(
kafka.security.protocolなど)。返されるレコードはありません
DataFrame を表示または処理しようとしても結果が得られない場合は、UI に次のように表示されます。
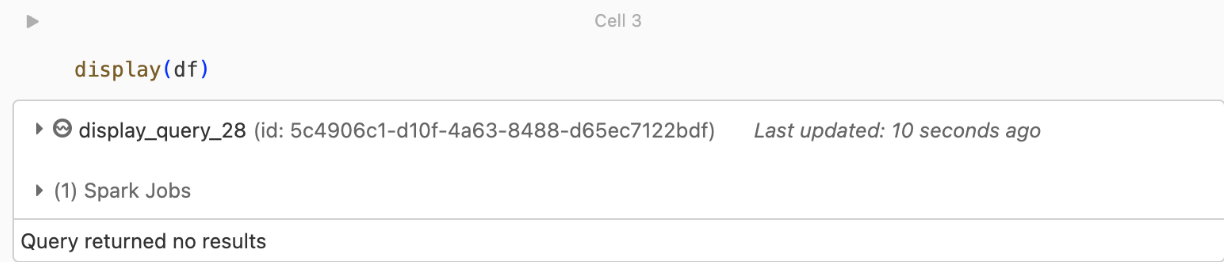
このメッセージは、認証は成功したが、EventHubs がデータを返さなかったことを意味します。 考えられる理由(ただし、すべてを網羅しているわけではありません)は次のとおりです。
間違った EventHubs トピックを指定しました。
startingOffsetsのデフォルトの Kafka 構成オプションはlatestで、現在、トピックを通じてデータを受信していません。Kafka の最も古いオフセットからデータの読み取りを開始するようにstartingOffsetstoearliestを設定できます。