Processamento de transmissão com o Apache Kafka e o Databricks
Este artigo descreve como você pode usar o Apache Kafka como fonte ou coletor quando executar cargas de trabalho de Structured Streaming no Databricks.
Para mais informações sobre o Kafka, consulte a documentação do Kafka.
Leia os dados da Kafka
Veja a seguir um exemplo de leitura de transmissão do Kafka:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "latest")
.load()
)
O Databricks também oferece suporte à semântica de leitura em lote para fontes de dados do Kafka, conforme mostrado no exemplo a seguir:
df = (spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
)
Para carregamento incremental de lotes, a Databricks recomenda usar Kafka com Trigger.AvailableNow. Consulte Configurando o processamento de lotes incrementais.
Em Databricks Runtime 13.3 LTS e acima, Databricks fornece uma função SQL para leitura de dados Kafka. A transmissão com SQL é suportada somente em Delta Live Tables ou com tabelas de transmissão em Databricks SQL. Consulte a função de valor de tabela read_kafka.
Configurar o leitor de transmissão estruturada do Kafka
O Databricks fornece a palavra-chave kafka como formato de dados para configurar conexões com o Kafka 0.10+.
A seguir estão as configurações mais comuns para o Kafka:
Há várias maneiras de especificar quais tópicos assinar. Você deve fornecer somente um destes parâmetros:
Opção |
Valor |
Descrição |
|---|---|---|
assinar |
Uma lista de tópicos separados por vírgula. |
A lista de tópicos para se inscrever. |
subscribePattern |
String Java regex. |
O padrão usado para assinar tópicos. |
atribuir |
Sequência JSON |
Tópico específico Partições a serem consumidas. |
Outras configurações notáveis:
Opção |
Valor |
Valor padrão |
Descrição |
|---|---|---|---|
kafka.bootstrap.servers |
Lista separada por vírgula de host:port. |
vazio |
[Obrigatório] A configuração do Kafka |
failOnDataLoss |
|
|
[Opcional] Se a consulta deve falhar quando houver a possibilidade de os dados terem sido perdidos. As consultas podem falhar definitivamente na leitura de dados do Kafka devido a vários cenários, como tópicos excluídos, truncamento de tópicos antes do processamento e assim por diante. Tentamos estimar de forma conservadora se os dados foram possivelmente perdidos ou não. Às vezes, isso pode causar alarmes falsos. Defina essa opção como |
minPartitions |
Inteiro >= 0, 0 = desabilitado. |
0 (desativado) |
[Opcional] Número mínimo de partições para ler de Kafka. Você pode configurar o Spark para utilizar um mínimo arbitrário de partições para ler a partir do Kafka utilizando a opção |
kafka.group.id |
Uma ID do grupo de consumidores Kafka. |
não definido |
[Opcional] ID do grupo a ser usado durante a leitura do Kafka. Use com cautela. Por padrão, cada consulta gera uma ID de grupo exclusiva para leitura de dados. Isso garante que cada consulta tenha seu próprio grupo de consumidores que não enfrente interferência de nenhum outro consumidor e, portanto, possa ler todas as partições de seus tópicos assinados. Em alguns cenários (por exemplo, autorização baseada em grupo Kafka), convém usar IDs de grupo autorizados específicos para ler dados. Opcionalmente, você pode definir a ID do grupo. No entanto, faça isso com extrema cautela, pois pode causar um comportamento inesperado.
|
startingOffsets |
earliest , latest |
latest |
[Opcional] O ponto inicial quando uma consulta é iniciada, seja "earliest", que é a partir dos primeiros deslocamentos, ou uma cadeia de caracteres json especificando um deslocamento inicial para cada TopicPartition. No json, -2 como deslocamento pode ser usado para fazer referência ao mais antigo, -1 ao mais recente. Observação: para consultas em lote, a opção latest (implicitamente ou com -1 em json) não é permitida. Para consultas de transmissão, isso só se aplica quando uma nova consulta for iniciada, e essa retomada sempre continuará de onde a consulta parou. As partições recém-descobertas durante uma consulta começarão o mais cedo possível. |
Consulte o Guia de integração de transmissão estruturada do Kafka para obter outras configurações opcionais.
Esquema de registros do Kafka
O esquema dos registros do Kafka é:
Coluna |
Tipo |
|---|---|
chave |
binário |
valor |
binário |
tópico |
string |
partição |
int |
deslocamento |
long |
timestamp |
long |
timestampType |
int |
O key e o value são sempre desserializados como matrizes de bytes com o ByteArrayDeserializer. Utilize operações do DataFrame (como cast("string")) para desserializar explicitamente as chaves e valores.
Gravar dados no Kafka
Veja a seguir um exemplo de uma gravação em transmissão para o Kafka:
(df
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.start()
)
O Databricks também oferece suporte à semântica de gravação em lote nos coletores de dados do Kafka, conforme mostrado no exemplo a seguir:
(df
.write
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.save()
)
Configurar o gravador Kafka transmissão estructurada
Importante
Databricks Runtime 13.3 LTS e acima incluem uma versão mais recente da biblioteca kafka-clients que permite gravações idempotentes por default. Se um sink Kafka usar a versão 2.8.0 ou abaixo com ACLs configuradas, mas sem IDEMPOTENT_WRITE ativado, a gravação falhará com a mensagem de erro org.apache.kafka.common.KafkaException:. Cannot execute transactional method because we are in an error state.
Para solucionar esse erro, atualize para a versão 2.8.0 ou superior do Kafka ou defina .option(“kafka.enable.idempotence”, “false”) ao configurar o gravador de transmissão estruturada.
O esquema fornecido ao DataStreamWriter interage com o sink do Kafka. Você pode usar os seguintes campos:
Nome da coluna |
Obrigatório ou opcional |
Tipo |
|---|---|---|
|
opcional |
|
|
obrigatório |
|
|
opcional |
|
|
Opcional (ignorado se |
|
|
opcional |
|
Veja a seguir as opções comuns definidas ao gravar no Kafka:
Opção |
Valor |
Valor padrão |
Descrição |
|---|---|---|---|
|
Uma lista delimitada por vírgulas de |
nenhum |
[Obrigatório] A configuração do Kafka |
|
|
não definido |
[Opcional] Define o tópico para todas as linhas a serem gravadas. Essa opção substitui todas as colunas de tópico existentes nos dados. |
|
|
|
[Opcional] Se os cabeçalhos do Kafka devem ser incluídos na linha. |
Consulte o Guia de integração de transmissão estruturada do Kafka para obter outras configurações opcionais.
Recuperar métricas de Kafka
Você pode obter a média, o mínimo e o máximo do número de deslocamentos em que a consulta de transmissão estiver atrás do último deslocamento disponível entre todos os tópicos inscritos com as métricas avgOffsetsBehindLatest, maxOffsetsBehindLatest e minOffsetsBehindLatest. Consulte Leitura interativa de métricas.
Observação
Disponível no Databricks Runtime 9.1e acima.
Obtenha o número total estimado de bytes que o processo de consulta não consumiu dos tópicos inscritos examinando o valor de estimatedTotalBytesBehindLatest. Essa estimativa baseia-se nos lotes que foram processados nos últimos 300 segundos. O período de tempo em que a estimativa se baseia pode ser alterado definindo-se a opção bytesEstimateWindowLength com um valor diferente. Por exemplo, para defini-lo com 10 minutos:
df = (spark.readStream
.format("kafka")
.option("bytesEstimateWindowLength", "10m") # m for minutes, you can also use "600s" for 600 seconds
)
Se você estiver executando a transmissão em um notebook, poderá ver essas métricas na aba Dados brutos no painel de progresso da consulta de transmissão:
{
"sources" : [ {
"description" : "KafkaV2[Subscribe[topic]]",
"metrics" : {
"avgOffsetsBehindLatest" : "4.0",
"maxOffsetsBehindLatest" : "4",
"minOffsetsBehindLatest" : "4",
"estimatedTotalBytesBehindLatest" : "80.0"
},
} ]
}
Use SSL para conectar o Databricks ao Kafka
Para ativar as conexões SSL com o Kafka, siga as instruções da documentação do Confluent Encryption and Authentication with SSL. Você pode fornecer as configurações descritas aqui, prefixadas com kafka., como opções. Por exemplo, você especifica o local do armazenamento de confiança na propriedade kafka.ssl.truststore.location.
A Databricks recomenda que você:
Armazene seus certificados no armazenamento de objetos na nuvem. O senhor pode restringir o acesso aos certificados apenas aos clusters que podem acessar o Kafka. Veja a governança de dados com o Unity Catalog.
Armazene suas senhas de certificado como segredos em um escopo secreto.
O exemplo a seguir usa locais de armazenamento de objetos e segredos de Databricks para habilitar uma conexão SSL:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<truststore-password-key-name>))
)
autenticação de entidade de serviço com Microsoft Entra ID e Azure Event Hubs
Databricks suporta a autenticação do Spark Job com o serviço Event Hubs. Essa autenticação é feita via OAuth com o Microsoft Entra ID.
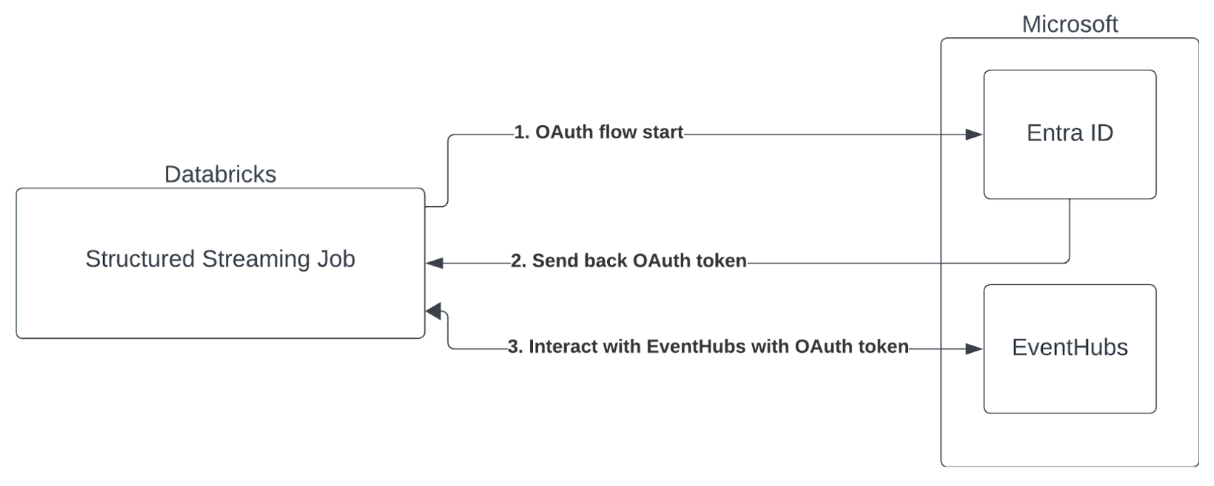
Databricks dá suporte à autenticação Microsoft Entra ID com ID de cliente e segredo nos seguintes ambientes compute :
Databricks Runtime 12.2 LTS e acima em compute configurada com modo de acesso de usuário único.
Databricks Runtime 14.3 LTS e acima em compute configurada com modo de acesso compartilhado.
Pipeline Delta Live Tables configurado sem o Unity Catalog.
O Databricks não suporta a autenticação Microsoft Entra ID com um certificado em qualquer ambiente compute ou no pipeline Delta Live Tables configurado com o Unity Catalog.
Essa autenticação não funciona em clusters compartilhados ou em Unity Catalog Delta Live Tables.
Configurando o Conector Kafka de transmissão estruturada
Para realizar a autenticação com o Microsoft Entra ID, você precisará dos seguintes valores:
Um ID tenant . Você pode encontrar isso na Serviço Microsoft Entra ID tab.
Um clientID (também conhecido como ID do aplicativo).
Um segredo do cliente. Depois de fazer isso, você deve adicioná-lo como um segredo ao seu Databricks Workspace. Para adicionar este segredo, consulte Gerenciamento de segredos.
Um tópico do EventHubs. Você pode encontrar uma lista de tópicos na seção Event Hubs na seção Entidades em uma página específica do Event Hubs Namespace . Para trabalhar com vários tópicos, pode definir a IAM role ao nível dos Event Hubs.
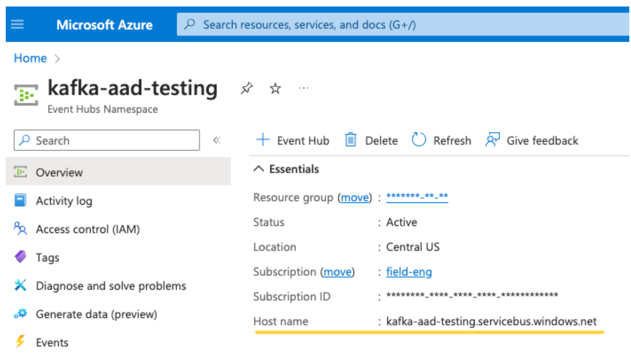
Um servidor EventHubs. Você pode encontrar isso na página de visão geral do seu namespace específico do Event Hubs:
Além disso, para usar o Entra ID, precisamos dizer ao Kafka para usar o mecanismo OAuth SASL (SASL é um protocolo genérico e OAuth é um tipo de “mecanismo” SASL):
kafka.security.protocoldeveria estarSASL_SSLkafka.sasl.mechanismdeveria estarOAUTHBEARERkafka.sasl.login.callback.handler.classdeve ser um nome totalmente qualificado da classe Java com um valorkafkashadedpara o manipulador de retorno de chamada de login de nossa classe Kafka sombreada. Veja o exemplo a seguir para a classe exata.
Exemplo
A seguir, vejamos um exemplo em execução:
# This is the only section you need to modify for auth purposes!
# ------------------------------
tenant_id = "..."
client_id = "..."
client_secret = dbutils.secrets.get("your-scope", "your-secret-name")
event_hubs_server = "..."
event_hubs_topic = "..."
# -------------------------------
sasl_config = f'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="{client_id}" clientSecret="{client_secret}" scope="https://{event_hubs_server}/.default" ssl.protocol="SSL";'
kafka_options = {
# Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers": f"{event_hubs_server}:9093",
"kafka.sasl.jaas.config": sasl_config,
"kafka.sasl.oauthbearer.token.endpoint.url": f"https://login.microsoft.com/{tenant_id}/oauth2/v2.0/token",
"subscribe": event_hubs_topic,
# You should not need to modify these
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class": "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
}
df = spark.readStream.format("kafka").options(**kafka_options)
display(df)
// This is the only section you need to modify for auth purposes!
// -------------------------------
val tenantId = "..."
val clientId = "..."
val clientSecret = dbutils.secrets.get("your-scope", "your-secret-name")
val eventHubsServer = "..."
val eventHubsTopic = "..."
// -------------------------------
val saslConfig = s"""kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="$clientId" clientSecret="$clientSecret" scope="https://$eventHubsServer/.default" ssl.protocol="SSL";"""
val kafkaOptions = Map(
// Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers" -> s"$eventHubsServer:9093",
"kafka.sasl.jaas.config" -> saslConfig,
"kafka.sasl.oauthbearer.token.endpoint.url" -> s"https://login.microsoft.com/$tenantId/oauth2/v2.0/token",
"subscribe" -> eventHubsTopic,
// You should not need to modify these
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class" -> "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
)
val scalaDF = spark.readStream
.format("kafka")
.options(kafkaOptions)
.load()
display(scalaDF)
Lidando com possíveis erros
opções de transmissão não são suportadas.
Se você tentar usar esse mecanismo de autenticação em um pipeline Delta Live Tables configurado com o Unity Catalog, poderá receber o seguinte erro:
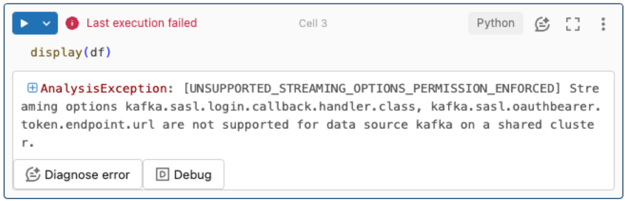
Para resolver esse erro, use uma configuração compatível do site compute. Veja a autenticação de entidade de serviço com Microsoft Entra ID e Azure Event Hubs.
Falha ao criar um novo
KafkaAdminClient.Este é um erro interno que Kafka lança se alguma das seguintes opções de autenticação estiver incorreta:
ID do cliente (também conhecido como ID do aplicativo)
ID tenant
Servidor EventHubs
Para resolver o erro, verifique se os valores estão corretos para essas opções.
Além disso, você poderá ver esse erro se modificar as opções de configuração fornecidas por default no exemplo (que foram solicitadas a não modificar), como
kafka.security.protocol.Não há registros sendo retornados
Se você estiver tentando exibir ou processar seu DataFrame, mas não estiver obtendo resultados, verá o seguinte na IU.
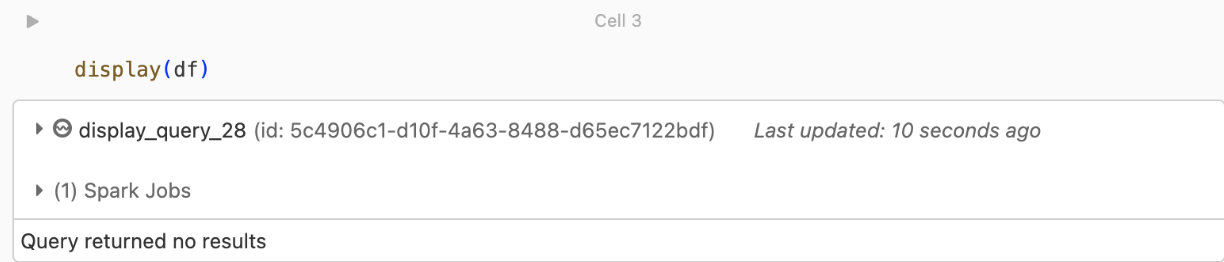
Esta mensagem significa que a autenticação foi bem sucedida, mas os EventHubs não devolveram quaisquer dados. Algumas razões possíveis (embora de forma alguma exaustivas) são:
Você especificou o tópico EventHubs errado.
A opção de configuração default do Kafka para
startingOffsetsélateste você ainda não está recebendo nenhum dado por meio do tópico. Você pode definirstartingOffsetstoearliestpara começar a ler os dados a partir dos primeiros deslocamentos do Kafka.