機能エンジニアリングと提供
このページでは、Unity Catalog が有効になっているワークスペースの機能エンジニアリングと提供機能について説明します。 ワークスペースがUnity Catalogに対して有効になっていない場合は、ワークスペースFeature Store (レガシー)を参照してください。
Databricks Feature Storeとして使用する理由は何ですか?
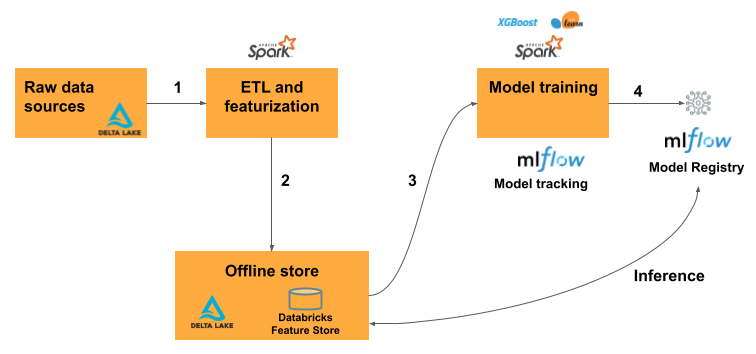
Databricks データ インテリジェンス プラットフォームを使用すると、モデル トレーニング ワークフロー全体が単一のプラットフォーム上で実行されます。
生データを取り込み、特徴量テーブルを作成し、モデルをトレーニングし、バッチ推論を実行するデータ パイプライン。 Unity Catalogの機能エンジニアリングを使用してモデルをトレーニングしてログに記録すると、モデルは機能メタデータとともにパッケージ化されます。 モデルをバッチ スコアリングまたはオンライン推論に使用すると、特徴値が自動的に取得されます。 呼び出し元は、それらについて知る必要はなく、新しいデータをスコアリングするためにフィーチャを検索または結合するロジックを含める必要もありません。
ワンクリックで利用でき、数ミリ秒のレイテンシを実現するモデルおよびFeature Servingポイント。
データとモデル モニタリング
さらに、このプラットフォームには次の機能があります。
機能の検出。 Databricks UI で機能を参照および検索できます。
統治。 特徴テーブル、関数、モデルはすべてUnity Catalogによって管理されます。 モデルをトレーニングすると、トレーニングに使用されたデータから権限が継承されます。
リネージ. Databricks で特徴量テーブルを作成すると、特徴量テーブルの作成に使用されたデータソースが保存され、アクセスできるようになります。 特徴量テーブルの各機能について、その機能を使用するモデル、ノートブック、ジョブ、エンドポイントにアクセスすることもできます。
ワークスペース間のアクセス。 特徴テーブル、関数、およびモデルは、カタログにアクセスできるすべてのワークスペースで自動的に使用できるようになります。
要件
ワークスペースで Unity Catalog が有効になっている必要があります。
Unity Catalog での機能エンジニアリングには、Databricks Runtime 13.3 LTS 以上が必要です。
ワークスペースがこれらの要件を満たしていない場合は、ワークスペースFeature Store (レガシー)を参照して、ワークスペースFeature Storeの使用方法を確認してください。
Databricks での特徴エンジニアリングはどのように機能しますか?
Databricks で特徴エンジニアリングを使用する一般的な機械学習ワークフローは、次のようになります。
生データを特徴量に変換し、目的の特徴を含む Spark DataFrame を作成するコードを記述します。
Unity Catalog に Delta テーブルを作成します。 主キーを持つDeltaテーブルは自動的に特徴量テーブルになります。
トレーニングを行い、特徴量テーブルを使用してモデルをログに記録します。 これを行うと、モデルはトレーニングに使用される機能の仕様を保存します。 モデルを推論に使用すると、適切な特徴量テーブルからの特徴が自動的に結合されます。
Model Registryにモデルを登録します。
これで、モデルを使用して新しいデータで予測を行うことができます。 モデルは、必要な特徴を Feature Store から自動的に取得します。
特徴エンジニアリングの使用を開始する - サンプルノートブック
まず、これらのサンプルノートブックを試してください。 この基本的なコンピューター ステップでは、特徴量テーブルを作成し、それを使用してモデルをトレーニングし、自動特徴検索を使用してバッチ スコアリングを実行する方法について説明します。 また、機能エンジニアリング UI を紹介し、それを使用して機能を検索する方法と、機能がどのように作成され使用されるかを理解する方法を示します。
タクシーのサンプルノートブックは、特徴を作成し、それを更新し、モデルのトレーニングとバッチ推論に使用するプロセスを示しています。
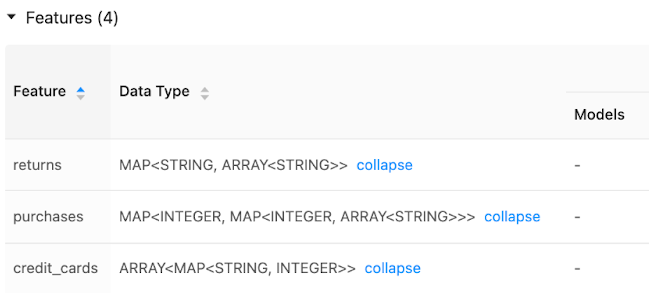
サポートされているデータ型
Unity Catalogでの特徴量エンジニアリングとワークスペースのFeature Storeでは、次の PySpark データ型がサポートされています。
IntegerTypeFloatTypeBooleanTypeStringTypeDoubleTypeLongTypeTimestampTypeDateTypeShortTypeArrayTypeBinaryType[1]DecimalType[1]MapType[1]StructType[2]
[1] BinaryType、DecimalType、および MapType は、 Unity Catalogでの特徴量エンジニアリングのすべてのバージョンとワークスペースFeature Store v0.3.5 以降でサポートされています。 [2] StructTypeはフィーチャー エンジニアリング v0.6.0 以降でサポートされています。
上記のデータ型は、機械学習アプリケーションで一般的な特徴量の種類をサポートしています。 例えば:
密なベクトル、テンソル、埋め込みを
ArrayTypeとして格納できます。スパースベクトル、テンソル、埋め込みを
MapTypeとして格納できます。テキストは
StringTypeとして保存できます。
オンライン ストアに公開されると、 ArrayType と MapType の機能は JSON 形式で格納されます。
Feature Store UI には、機能データ型のメタデータが表示されます。