アダプティブクエリー実行
注:
Spark UI機能は、このリリースの時点で Databricks on Google Cloud では使用できません。
適応クエリー実行 (AQE) は、クエリー実行中に発生するクエリー再最適化です。
ランタイム再最適化の動機は、シャッフルおよびブロードキャスト交換 (AQE ではクエリー ステージと呼ばれます) の最後に、Databricks に最新の正確な統計があることです。 その結果、Databricks は、より優れた物理戦略を選択したり、最適なシャッフル後のパーティション サイズと数を選択したり、スキュー結合処理などのヒントを必要としていた最適化を実行したりできます。
これは、統計収集がオンになっていない場合や、統計が古くなっている場合に非常に役立ちます。 また、複雑なクエリーの最中やデータスキューの発生後など、静的に導出された統計が不正確な場所にも役立ちます。
資格
AQE はデフォルトで有効になっています。 4つの主要な機能があります。
ソートマージ結合をブロードキャストハッシュ結合に動的に変更します。
シャッフル交換後にパーティションを動的に結合します (小さなパーティションを妥当なサイズのパーティションに結合します)。 非常に小さなタスクは I/O スループットが悪く、スケジュールのオーバーヘッドとタスク設定のオーバーヘッドに悩まされる傾向があります。 小さなタスクを組み合わせることで、リソースが節約され、クラスターのスループットが向上します。
ソートマージ結合とシャッフルハッシュ結合のスキューを動的に処理し、スキューされたタスクをほぼ均等なサイズのタスクに分割し(必要に応じてレプリケートします)。
空のリレーションを動的に検出して伝播します。
アプリケーション
AQE は、次のようなすべてのクエリーに適用されます。
非ストリーミング
少なくとも 1 つの交換 (通常、結合、集計、またはウィンドウがある場合)、1 つのサブクエリ、またはその両方を含む。
すべての AQE 適用クエリーが必ずしも再最適化されるわけではありません。 再最適化では、静的にコンパイルされたものとは異なるクエリープランが出てくる場合と思い付かない場合があります。 クエリーのプランが AQE によって変更されたかどうかを判別するには、次のセクション「 クエリー・プラン」を参照してください。
クエリープラン
このセクションでは、さまざまな方法でクエリー プランを調べる方法について説明します。
このセクションの内容:
Spark UI
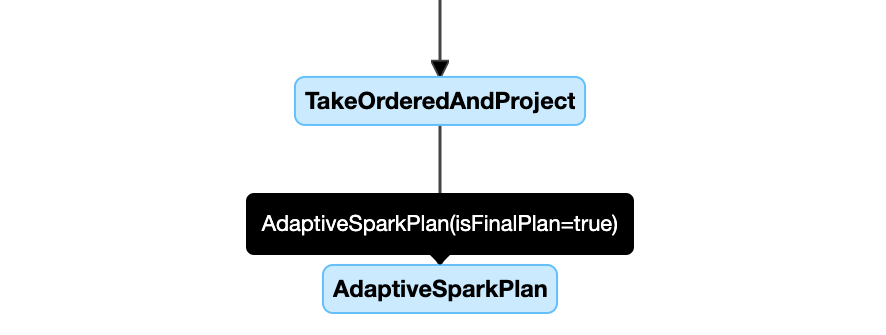
DataFrame.explain()
AdaptiveSparkPlan ノード
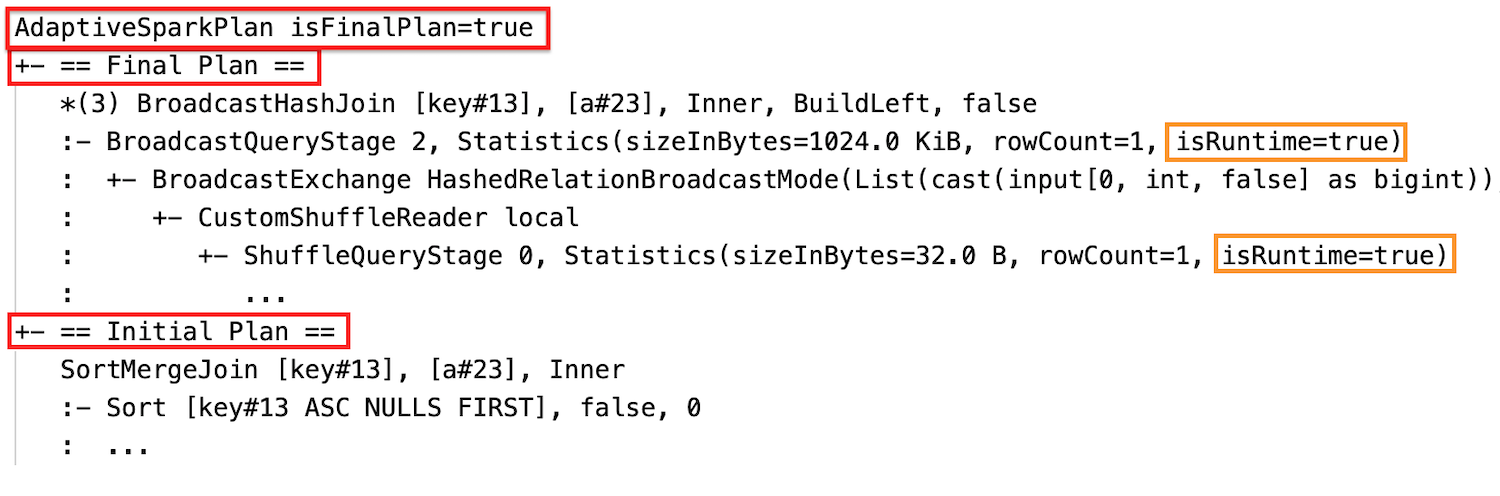
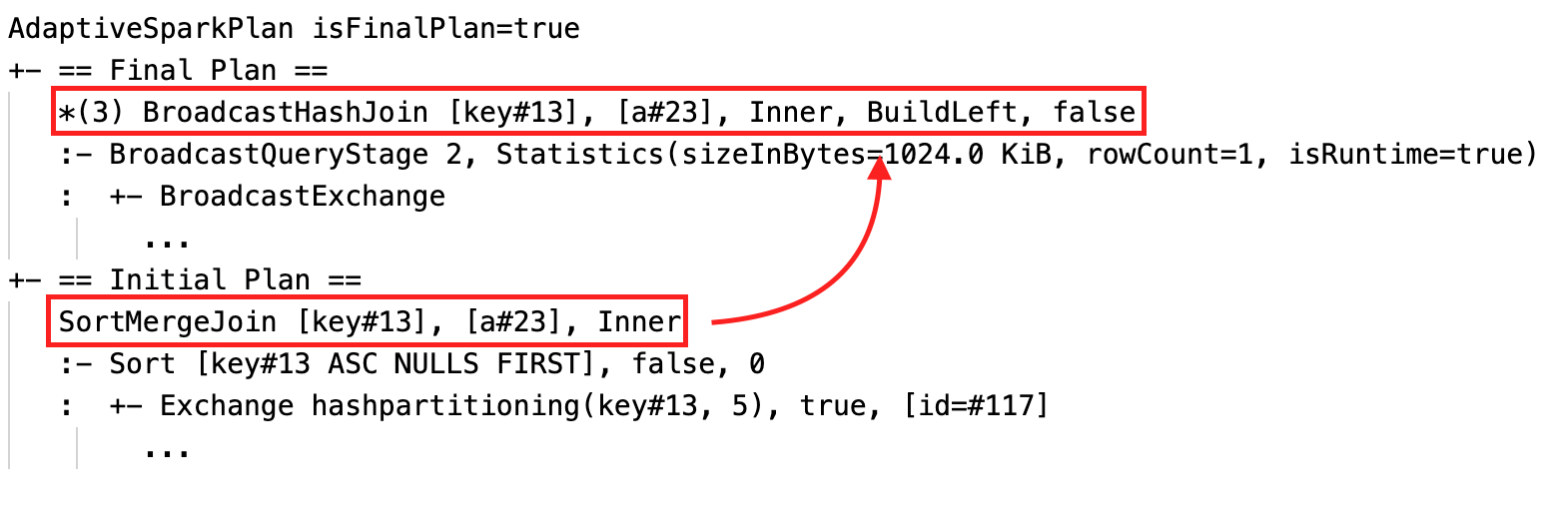
AQE 適用クエリーには、通常、各メインクエリーまたはサブクエリーのルートノードとして、1 つ以上の AdaptiveSparkPlan ノードが含まれます。 クエリーの実行前または実行中は、対応する AdaptiveSparkPlan ノードの isFinalPlan フラグは次のように表示されます false。クエリーの実行が完了すると、 isFinalPlan フラグが trueに変わります。
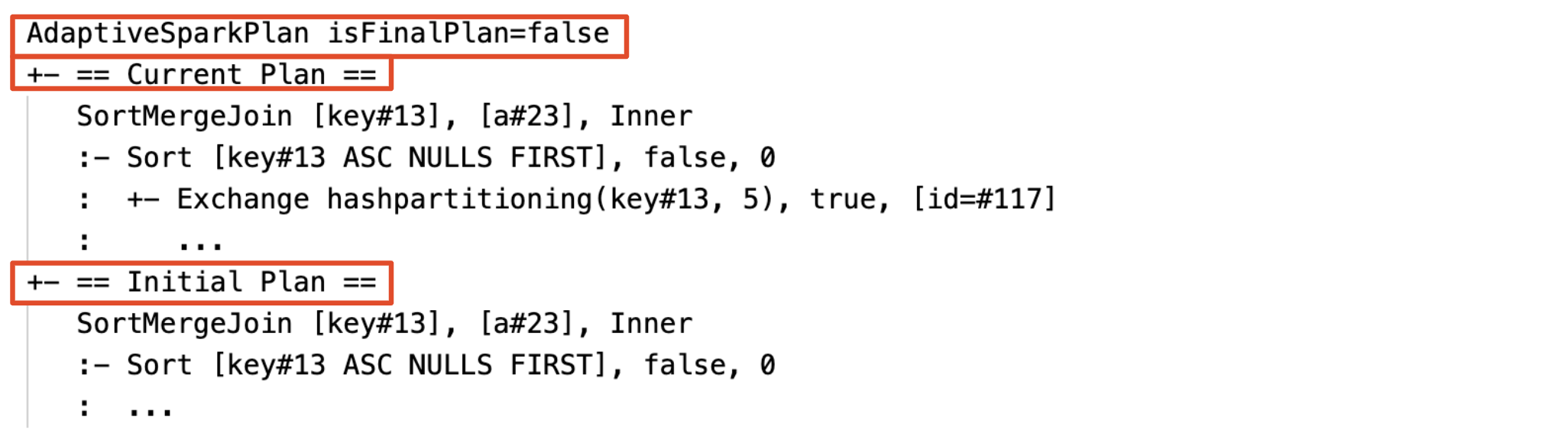
現在および当初の計画
各 AdaptiveSparkPlan ノードの下には、実行が完了したかどうかに応じて、初期計画 (AQE 最適化を適用する前の計画) と現在計画または最終計画の両方があります。 現在の計画は、実行が進むにつれて進化します。
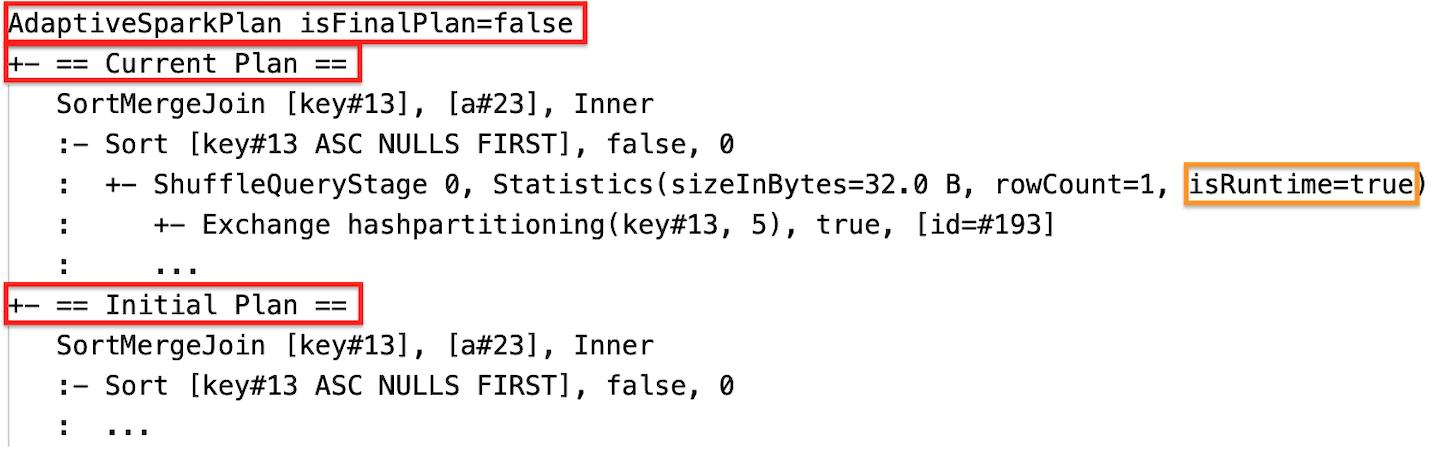
ランタイム統計
各シャッフルおよびブロードキャストステージには、データ統計が含まれています。
ステージの実行前またはステージの実行中に、統計はコンパイル時の推定値であり、フラグ isRuntime は falseです。 Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);
ステージの実行が完了すると、統計は実行時に収集された統計になり、フラグ isRuntime は trueになります。 Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true)
次に、 DataFrame.explain 例を示します。
実行前
実行中
実行後
SQL EXPLAIN

効果
クエリー プランは、1 つ以上の AQE 最適化が有効になると変更されます。 これらの AQE 最適化の効果は、現行計画と最終計画、および現行計画と最終計画の初期計画ノードと特定の計画ノードの違いによって示されます。
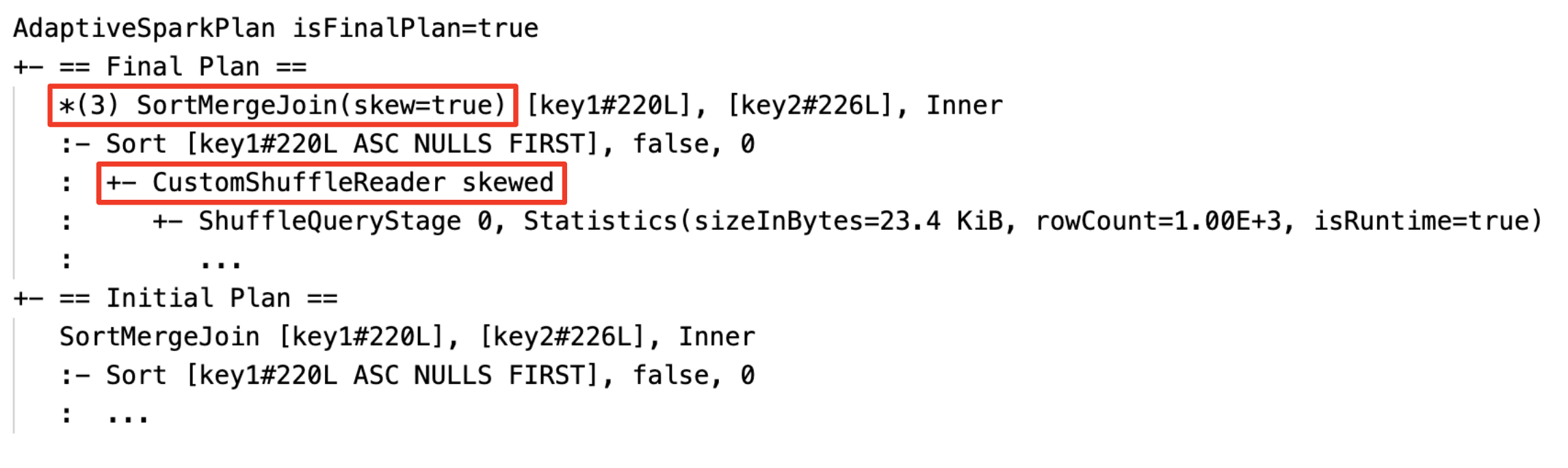
ソートマージ結合をブロードキャストハッシュ結合に動的に変更:現在/最終計画と初期計画の間の異なる物理結合ノード
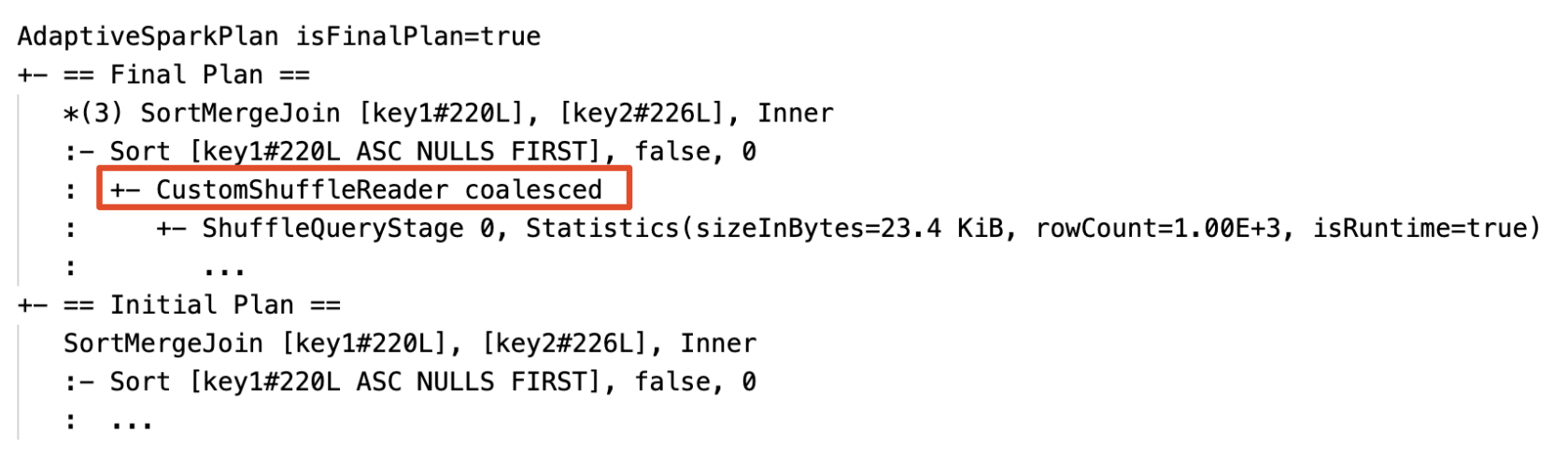
パーティションの動的結合: プロパティを持つノード
CustomShuffleReaderCoalesced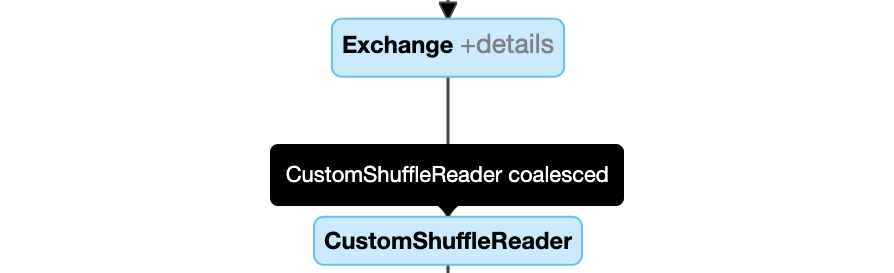
スキュー結合を動的に処理する: フィールド
isSkewが true のノードSortMergeJoin。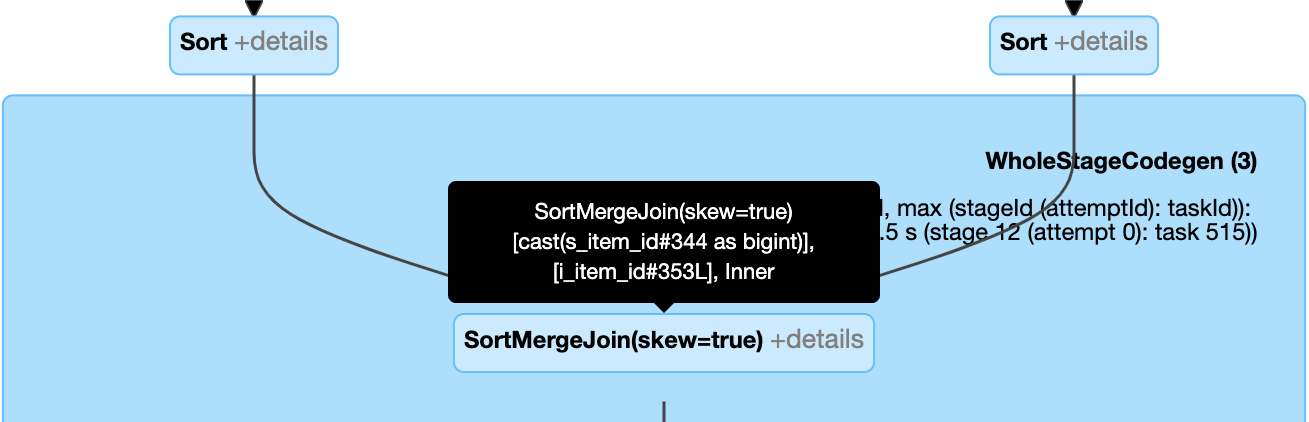
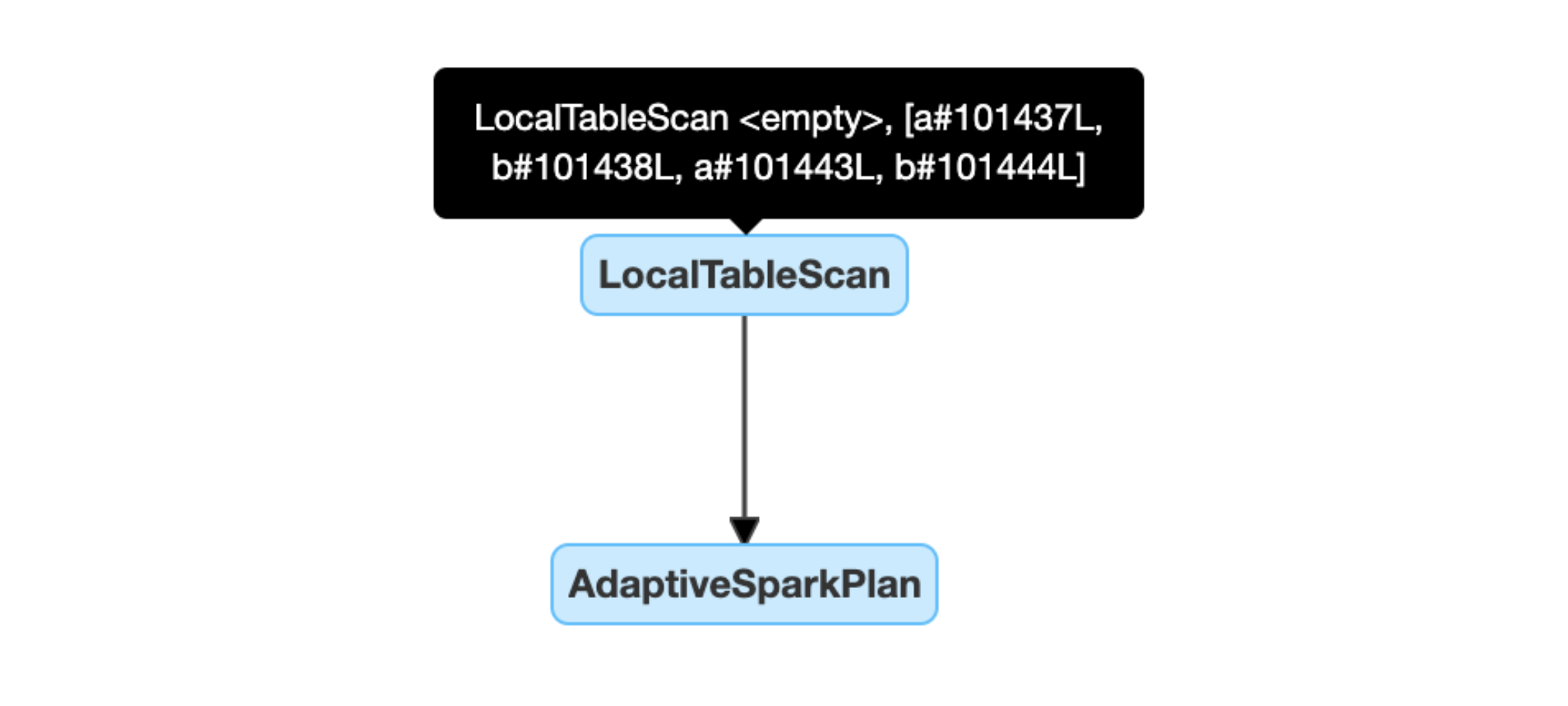
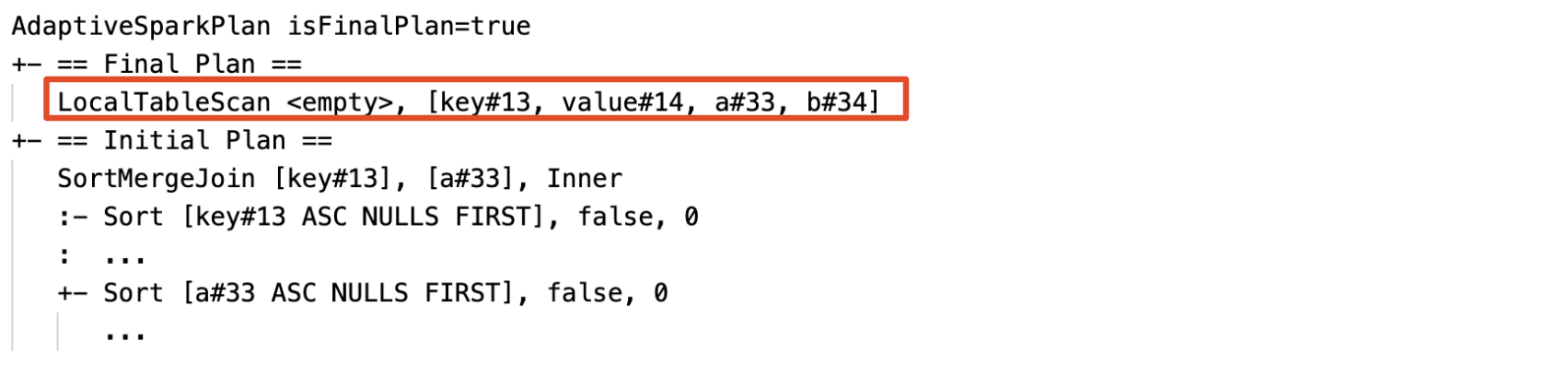
空のリレーションを動的に検出して伝播する: プランの一部 (または全体) は、リレーション フィールドが空であるノード LocalTableScan に置き換えられます。
構成
このセクションの内容:
アダプティブクエリー実行の有効化と無効化
財産 |
|---|
spark.databricks.optimizer.adaptive.enabled 種類: アダプティブクエリー実行を有効にするか無効にするか。 デフォルト値: |
自動最適化シャッフルを有効にする
財産 |
|---|
spark.sql.shuffle.partitions 種類: 結合または集計のデータをシャッフルするときに使用するパーティションの既定の数。 値を 注: 構造化ストリーミングの場合、同じチェックポイント・ロケーションからのクエリー再始動の間にこの構成を変更することはできません。 デフォルト値: 200 |
ソートマージ結合をブロードキャストハッシュ結合に動的に変更
財産 |
|---|
spark.databricks.adaptive.autoBroadcastJoinThreshold 種類: ランタイム時にブロードキャスト参加への切り替えをトリガーするしきい値。 デフォルト値: |
パーティションを動的に結合する
財産 |
|---|
spark.sql.adaptive.coalescePartitions.enabled 種類: パーティションの結合を有効にするか無効にするか。 デフォルト値: |
spark.sql.adaptive.advisoryPartitionSizeInBytes 種類: 合体後の目標サイズ。 結合されたパーティションサイズは、このターゲットサイズに近くなりますが、それより大きくはありません。 デフォルト値: |
spark.sql.adaptive.coalescePartitions.minPartitionSize 種類: 結合後のパーティションの最小サイズ。 結合されたパーティションサイズは、このサイズより小さくなりません。 デフォルト値: |
spark.sql.adaptive.coalescePartitions.minPartitionNum 種類: 結合後のパーティションの最小数。 この設定は明示的に デフォルト値: 2x いいえ。 クラスター コア数 |
スキュー結合を動的に処理する
財産 |
|---|
spark.sql.adaptive.skewJoin.enabled 種類: スキュー結合処理を有効にするか無効にするか。 デフォルト値: |
spark.sql.adaptive.skewJoin.skewedPartitionFactor 種類: パーティション サイズの中央値を掛けたときに、パーティションが歪んでいるかどうかの判断に寄与する要因。 デフォルト値: |
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 種類: パーティションが歪んでいるかどうかの判断に寄与するしきい値。 デフォルト値: |
パーティションは、 (partition size > skewedPartitionFactor * median partition size) と (partition size > skewedPartitionThresholdInBytes) の両方が trueされている場合、歪んでいると見なされます。
空のリレーションを動的に検出して伝播する
財産 |
|---|
spark.databricks.adaptive.emptyRelationPropagation.enabled 種類: 動的な空リレーション伝播を有効にするか無効にするか。 デフォルト値: |
よくある質問(FAQ)
このセクションの内容:
AQE が小さな結合テーブルをブロードキャストしなかったのはなぜですか?
ブロードキャストされる予定のリレーションのサイズがこのしきい値を下回っているが、まだブロードキャストされない場合:
結合タイプを確認します。 ブロードキャストは、特定の結合タイプではサポートされません (たとえば、
LEFT OUTER JOINの左リレーションはブロードキャストできません)。また、リレーションに空のパーティションが多数含まれている場合もあり、その場合、タスクの大部分はソートマージ結合ですばやく終了するか、スキュー結合処理で最適化できる可能性があります。 AQE は、空でないパーティションの割合が
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoinより低い場合、このようなソート・マージ結合をブロードキャスト・ハッシュ結合に変更することを回避します。
AQE を有効にしたブロードキャスト参加戦略のヒントを使用する必要がありますか?
はい。 静的に計画されたブロードキャスト結合は、結合の両側でシャッフルを実行するまでブロードキャスト結合に切り替えない可能性があるため、通常、AQE によって動的に計画されたブロードキャスト結合よりもパフォーマンスが高くなります (その時点で実際の関係サイズが取得されます)。 したがって、ブロードキャストのヒントを使用することは、クエリをよく知っている場合は、依然として良い選択です。 AQE は、静的最適化と同じようにクエリー ヒントを尊重しますが、ヒントの影響を受けない動的最適化を適用できます。
スキュー結合ヒントと AQE スキュー結合の最適化の違いは何ですか?どちらを使うべきですか?
AQE スキュー結合は完全に自動であり、一般に対応するヒントよりもパフォーマンスが向上するため、スキュー結合ヒントを使用するのではなく、AQE スキュー結合処理に依存することをお勧めします。
AQE で結合順序が自動的に調整されないのはなぜですか?
動的結合の並べ替えは AQE の一部ではありません。
AQE でデータ スキューが検出されなかったのはなぜですか?
AQE がパーティションを歪んだパーティションとして検出するには、次の 2 つのサイズ条件を満たす必要があります。
パーティションサイズが
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytesよりも大きい(デフォルトは256MB)パーティション サイズが、すべてのパーティションの中央値サイズに歪んだパーティション係数
spark.sql.adaptive.skewJoin.skewedPartitionFactorを掛けた値よりも大きくなっています (デフォルト 5)
さらに、スキュー処理のサポートは、特定の結合タイプでは制限されています (たとえば、 LEFT OUTER JOINでは、左側のスキューのみを最適化できます)。