コストベースのオプティマイザー
Spark SQL では、コストベースのオプティマイザー (CBO) を使用して、クエリー プランを改善できます。 これは、複数の結合を持つクエリーで特に便利です。 これを機能させるには、テーブルと列の統計を収集し、それらを最新の状態に保つことが重要です。
統計の収集
CBO を最大限に活用するには、 列統計 と テーブル統計の両方を収集することが重要です。 ANALYZE TABLE コマンドを使用して、統計を手動で収集できます。
ヒント
統計を最新の状態に保つには、テーブルに書き込んだ後にANALYZE TABLEを実行します。
クエリープランの確認
クエリー プランを確認するには、いくつかの方法があります。
EXPLAIN コマンド
プランで統計が使用されているかどうかを確認するには、SQL コマンド EXPLAIN を使用します。
統計が欠落している場合は、クエリー・プランが最適でない可能性があります。
== Optimized Logical Plan ==
Aggregate [s_store_sk], [s_store_sk, count(1) AS count(1)L], Statistics(sizeInBytes=20.0 B, rowCount=1, hints=none)
+- Project [s_store_sk], Statistics(sizeInBytes=18.5 MB, rowCount=1.62E+6, hints=none)
+- Join Inner, (d_date_sk = ss_sold_date_sk), Statistics(sizeInBytes=30.8 MB, rowCount=1.62E+6, hints=none)
:- Project [ss_sold_date_sk, s_store_sk], Statistics(sizeInBytes=39.1 GB, rowCount=2.63E+9, hints=none)
: +- Join Inner, (s_store_sk = ss_store_sk), Statistics(sizeInBytes=48.9 GB, rowCount=2.63E+9, hints=none)
: :- Project [ss_store_sk, ss_sold_date_sk], Statistics(sizeInBytes=39.1 GB, rowCount=2.63E+9, hints=none)
: : +- Filter (isnotnull(ss_store_sk) && isnotnull(ss_sold_date_sk)), Statistics(sizeInBytes=39.1 GB, rowCount=2.63E+9, hints=none)
: : +- Relation[ss_store_sk,ss_sold_date_sk] parquet, Statistics(sizeInBytes=134.6 GB, rowCount=2.88E+9, hints=none)
: +- Project [s_store_sk], Statistics(sizeInBytes=11.7 KB, rowCount=1.00E+3, hints=none)
: +- Filter isnotnull(s_store_sk), Statistics(sizeInBytes=11.7 KB, rowCount=1.00E+3, hints=none)
: +- Relation[s_store_sk] parquet, Statistics(sizeInBytes=88.0 KB, rowCount=1.00E+3, hints=none)
+- Project [d_date_sk], Statistics(sizeInBytes=12.0 B, rowCount=1, hints=none)
+- Filter ((((isnotnull(d_year) && isnotnull(d_date)) && (d_year = 2000)) && (d_date = 2000-12-31)) && isnotnull(d_date_sk)), Statistics(sizeInBytes=38.0 B, rowCount=1, hints=none)
+- Relation[d_date_sk,d_date,d_year] parquet, Statistics(sizeInBytes=1786.7 KB, rowCount=7.30E+4, hints=none)
重要
rowCount 統計量は、複数の結合を持つクエリーにとって特に重要です。rowCount が欠落している場合は、それを計算するのに十分な情報がないことを意味します(つまり、一部の必須列に統計がありません)。
Spark SQL UI
Spark SQL UI ページを使用して、実行されたプランと統計の正確性を確認します。

見積もりの欠落
rows output: 2,451,005 est: N/A などの行は、この演算子が約 2M 行を生成し、使用可能な統計がなかったことを意味します。
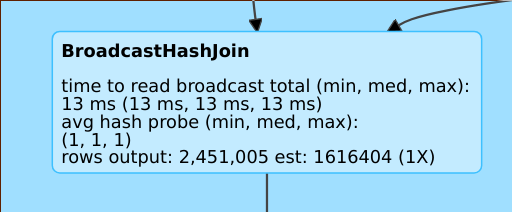
良い見積もり
rows output: 2,451,005 est: 1616404 (1X) などの行は、この演算子が約を生成することを意味します。2M行、推定値は概算でした。 1.6M、推定誤差係数は1であった。

悪い見積もり
rows output: 2,451,005 est: 2626656323 などの行は、推定値が 2B 行であるのに対し、この演算子は約 2M 行を生成するため、推定誤差係数は 1000 であったことを意味します。