Otimizador baseado em custo
O Spark SQL pode usar um otimizador baseado em custo (CBO) para melhorar os planos query . Isso é especialmente útil para query com join múltipla. Para que isso funcione, é fundamental coletar estatísticas de tabelas e colunas e mantê-las atualizadas.
Coletar estatísticas
Para obter todos os benefícios do CBO, é importante coletar estatísticas de colunas e estatísticas de tabela. O senhor pode usar o comando ANALYZE TABLE para coletar estatísticas manualmente.
Dica
Para manter as estatísticas atualizadas, execute ANALYZE TABLE depois de gravar na tabela.
Verificar planos de consulta
Existem várias maneiras de verificar o plano query .
EXPLAIN comando
Para verificar se o plano utiliza estatísticas, utilize o comando SQL EXPLAIN.
Se as estatísticas estiverem ausentes, o plano query pode não ser o ideal.
== Optimized Logical Plan ==
Aggregate [s_store_sk], [s_store_sk, count(1) AS count(1)L], Statistics(sizeInBytes=20.0 B, rowCount=1, hints=none)
+- Project [s_store_sk], Statistics(sizeInBytes=18.5 MB, rowCount=1.62E+6, hints=none)
+- Join Inner, (d_date_sk = ss_sold_date_sk), Statistics(sizeInBytes=30.8 MB, rowCount=1.62E+6, hints=none)
:- Project [ss_sold_date_sk, s_store_sk], Statistics(sizeInBytes=39.1 GB, rowCount=2.63E+9, hints=none)
: +- Join Inner, (s_store_sk = ss_store_sk), Statistics(sizeInBytes=48.9 GB, rowCount=2.63E+9, hints=none)
: :- Project [ss_store_sk, ss_sold_date_sk], Statistics(sizeInBytes=39.1 GB, rowCount=2.63E+9, hints=none)
: : +- Filter (isnotnull(ss_store_sk) && isnotnull(ss_sold_date_sk)), Statistics(sizeInBytes=39.1 GB, rowCount=2.63E+9, hints=none)
: : +- Relation[ss_store_sk,ss_sold_date_sk] parquet, Statistics(sizeInBytes=134.6 GB, rowCount=2.88E+9, hints=none)
: +- Project [s_store_sk], Statistics(sizeInBytes=11.7 KB, rowCount=1.00E+3, hints=none)
: +- Filter isnotnull(s_store_sk), Statistics(sizeInBytes=11.7 KB, rowCount=1.00E+3, hints=none)
: +- Relation[s_store_sk] parquet, Statistics(sizeInBytes=88.0 KB, rowCount=1.00E+3, hints=none)
+- Project [d_date_sk], Statistics(sizeInBytes=12.0 B, rowCount=1, hints=none)
+- Filter ((((isnotnull(d_year) && isnotnull(d_date)) && (d_year = 2000)) && (d_date = 2000-12-31)) && isnotnull(d_date_sk)), Statistics(sizeInBytes=38.0 B, rowCount=1, hints=none)
+- Relation[d_date_sk,d_date,d_year] parquet, Statistics(sizeInBytes=1786.7 KB, rowCount=7.30E+4, hints=none)
Importante
A estatística rowCount é especialmente importante para query com join múltipla. Se rowCount estiver faltando, significa que não há informação suficiente para calculá-lo (ou seja, algumas colunas obrigatórias não possuem estatísticas).
IU do Spark SQL
Use a página Spark SQL UI para ver o plano executado e a precisão das estatísticas.

Estimativa ausente
Uma linha como rows output: 2,451,005 est: N/A significa que esse operador produz aproximadamente 2 milhões de linhas e não há estatísticas disponíveis.
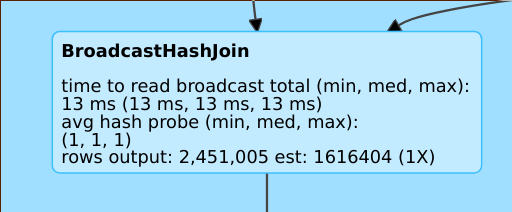
boa estimativa
Uma linha como rows output: 2,451,005 est: 1616404 (1X) significa que este operador produz aprox. 2 milhões de linhas, enquanto a estimativa era de aprox. 1,6M e o fator de erro de estimativa foi 1.

Estimativa ruim
Uma linha como rows output: 2,451,005 est: 2626656323 significa que esse operador produz aproximadamente 2 milhões de linhas enquanto a estimativa era de 2 bilhões de linhas, portanto, o fator de erro de estimativa era 1.000.