ストリーミング テーブルのしくみ
プレビュー
この機能はパブリックプレビュー段階です。
ストリーミング テーブルは、ストリーミングまたは増分データ処理の追加サポートを備えた通常の Delta テーブルです。
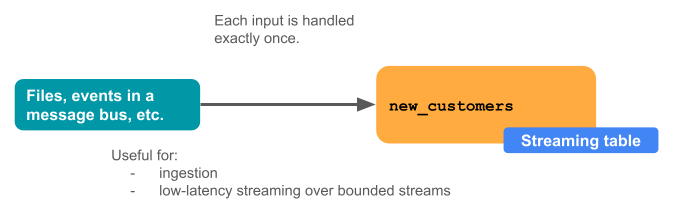
ストリーミング テーブルは、次の理由からデータ取り込みに適しています。
各入力行は 1 回だけ処理され、インジェストワークロードの大部分をモデル化します (つまり、テーブルに行を追加または更新/挿入します)。
大量の追加専用データを処理できます。
ストリーミングテーブルは、次の理由から、低レイテンシーのストリーミング変換にも適しています。
時間の行とウィンドウに対する推論
大量のデータを処理する
低レイテンシ
次の図は、ストリーミング テーブルの仕組みを示しています。
ストリーミング テーブルは、1 つの Delta Live Tables パイプラインによって定義および更新されます。 Delta Live Tables パイプラインを作成するときは、パイプラインのソース コードでストリーミング テーブルを明示的に定義できます。 これらのテーブルは、このパイプラインによって定義され、他のパイプラインで変更または更新することはできません。 Databricks SQL でストリーミング テーブルを作成すると、Databricks は、このテーブルの更新に使用される Delta Live Tables パイプラインを作成します。
データ取り込みのためのストリーミング テーブル
ストリーミング テーブルは、追加専用のデータソース用に設計されており、入力を一度だけ処理します。
フルリフレッシュでは、ストリーミング テーブルは既に処理されたデータを再処理します。 フルリフレッシュアクションにより、ストリーミングテーブルは、以前に処理された入力を含むすべての入力を再処理します。
次の例は、ストリーミングテーブルを使用してクラウドストレージから新しいファイルを取り込む方法を示しています。 データセット定義で 1 つ以上の spark.readStream 呼び出しを使用すると、Delta Live Tables はデータセットをマテリアライズドビューではなくストリーミングテーブルとして扱います。
import dlt
@dlt.table
def raw_customers():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load("/Volumes/path/to/files")
)
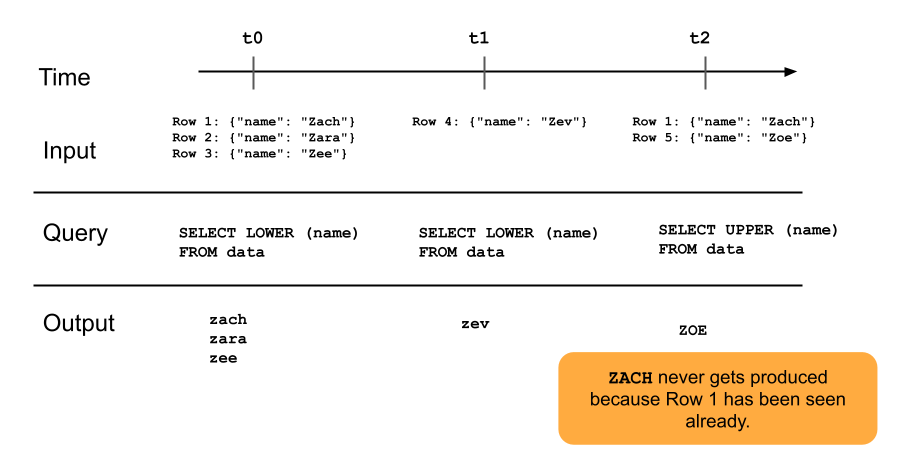
次の図は、追加専用ストリーミング テーブルの仕組みを示しています。
ストリーミングテーブルと低レイテンシーのストリーミング
ストリーミングテーブルは、境界を超えたステートに対する低レイテンシーのストリーミング用に設計されています。 ストリーミングテーブルはチェックポイント管理に RocksDB を使用するため、低レイテンシーのストリーミングに適しています。 ただし、自然な境界のあるストリームまたはウォーターマークで囲まれたストリームが想定されます。
自然な境界のあるストリームは、開始と終了が明確に定義されたストリーミング データソースによって生成されます。 自然な境界のあるストリームの例としては、ファイルの最初のバッチが配置された後に新しいファイルが追加されないファイルのディレクトリからデータを読み取る場合があります。 ファイルの数が有限であるため、ストリームには境界があると見なされ、すべてのファイルが処理された後にストリームが終了します。
ウォーターマークを使用してストリームをバインドすることもできます。 Spark構造化ストリーミングのウォーターマークは、システムが遅延イベントを待機してから時間枠が完了したと見なす時間を指定することで、遅延データの処理を支援するメカニズムです。ウォーターマークのない無制限のストリームは、メモリ不足が原因で Delta Live Tables パイプラインが失敗する可能性があります。
ストリーム・スナップショット・ジョイン
ストリーム-スナップショット結合は、ストリームと、ストリームの開始時にスナップショットが作成されるディメンションとの間の結合です。 これらの結合は、ストリームの開始後にディメンションが変更された場合、ディメンション テーブルは時間的にスナップショットとして扱われ、ストリームの開始後にディメンション テーブルへの変更はディメンション テーブルを再読み込みまたは更新しない限り反映されないため、再計算されません。 これは、結合の小さな不一致を受け入れることができる場合、妥当な動作です。 たとえば、トランザクションの数が顧客の数よりも何桁も大きい場合、近似結合は許容されます。
次のコード例では、ディメンション テーブル Customer を 2 つの行で結合し、増え続けるデータセット transactions を結合します。 これら 2 つのデータセット間の結合を sales_reportというテーブルに具体化します。 外部プロセスが新しい行 (customer_id=3, name=Zoya) を追加して顧客テーブルを更新する場合、ストリームの開始時に静的ディメンション テーブルがスナップショットされたため、この新しい行は結合に存在しないことに注意してください。
import dlt
@dlt.view
# assume this table contains an append-only stream of rows about transactions
# (customer_id=1, value=100)
# (customer_id=2, value=150)
# (customer_id=3, value=299)
# ... <and so on> ...
def v_transactions():
return spark.readStream.table("transactions")
# assume this table contains only these two rows about customers
# (customer_id=1, name=Bilal)
# (customer_id=2, name=Olga)
@dlt.view
def v_customers():
return spark.read.table("customers")
@dlt.table
def sales_report():
facts = spark.readStream.table("v_transactions")
dims = spark.read.table("v_customers")
return (
facts.join(dims, on="customer_id", how="inner"
)
ストリーミング テーブルの制限
ストリーミングテーブルには、次の制限があります。
限定的な進化: データセット全体を再計算せずにクエリを変更できます。 ストリーミングテーブルは行を一度しか見ないため、異なる行に対して異なるクエリを操作できます。 つまり、データセットで実行されているクエリの以前のバージョンをすべて把握しておく必要があります。 ストリーミングテーブルが再び表示されたデータを表示するようにするには、完全な更新が必要です。
ステート管理: ストリーミングテーブルは低レイテンシーであるため、操作するストリームに自然な境界があるか、ウォーターマークで囲まれていることを確認する必要があります。
結合は再計算されません。 自動的に再計算されるため、結果が常に正しいマテリアライズドビューとは異なり、ストリーミングテーブルのジョインはディメンションが変更されても再計算されません。 この特性は、「速いが間違っている」シナリオに適しています。