Crie seu primeiro fluxo de trabalho com um job do Databricks
Este artigo demonstra um trabalho do Databricks que orquestra tarefas para ler e processar um conjunto de dados de amostra. Neste aba de início rápido, você:
Cria um novo notebook e adiciona código para recuperar um conjunto de dados de amostra contendo nomes de bebês populares por ano.
Salve a amostra dataset em Unity Catalog.
Crie um novo Notebook e adicione código para ler o dataset de Unity Catalog, filtre-o por ano e exiba os resultados.
Cria um novo job e configura duas tarefas utilizando os notebooks.
Execute o job e veja os resultados.
Requisitos
O senhor deve ter um volume no Unity Catalog. Este artigo usa um volume chamado my-volume em um esquema chamado default em um catálogo chamado main. Além disso, o senhor deve ter as seguintes permissões no Unity Catalog:
READ VOLUMEeWRITE VOLUME, ouALL PRIVILEGES, para o volumemy-volume.USE SCHEMAouALL PRIVILEGESpara o esquemadefault.USE CATALOGouALL PRIVILEGESpara o catálogomain.
Para definir essas permissões, consulte o administrador do Databricks ou os privilégios e objetos protegidos do Unity Catalog.
Crie os notebooks
Recupere e salve dados
Para criar um Notebook para recuperar a amostra dataset e salvá-la em Unity Catalog:
Vá para suas páginas de aterrissagem Databricks e clique
 Novo na barra lateral e selecione Notebook. O Databricks cria e abre um novo Notebook em branco em sua pasta default . O idioma default é o idioma usado mais recentemente e o Notebook é automaticamente anexado ao recurso compute usado mais recentemente.
Novo na barra lateral e selecione Notebook. O Databricks cria e abre um novo Notebook em branco em sua pasta default . O idioma default é o idioma usado mais recentemente e o Notebook é automaticamente anexado ao recurso compute usado mais recentemente.Se necessário, altere o idioma padrão para Python.
Copie o seguinte código Python e cole-o na primeira célula do notebook.
import requests response = requests.get('https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv') csvfile = response.content.decode('utf-8') dbutils.fs.put("/Volumes/main/default/my-volume/babynames.csv", csvfile, True)
Ler e exibir dados filtrados
Para criar um notebook para ler e apresentar os dados para filtragem:
Vá para suas páginas de aterrissagem Databricks e clique
Novo na barra lateral e selecione Notebook. O Databricks cria e abre um novo Notebook em branco em sua pasta default . O idioma default é o idioma usado mais recentemente e o Notebook é automaticamente anexado ao recurso compute usado mais recentemente.Se necessário, altere o idioma padrão para Python.
Copie o seguinte código Python e cole-o na primeira célula do notebook.
babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/Volumes/main/default/my-volume/babynames.csv") babynames.createOrReplaceTempView("babynames_table") years = spark.sql("select distinct(Year) from babynames_table").toPandas()['Year'].tolist() years.sort() dbutils.widgets.dropdown("year", "2014", [str(x) for x in years]) display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
Criar um job
Clique em
 fluxo de trabalho na barra lateral.
fluxo de trabalho na barra lateral.Clique
 .
.A aba Tarefas é exibida com a caixa de diálogo Criar tarefa.
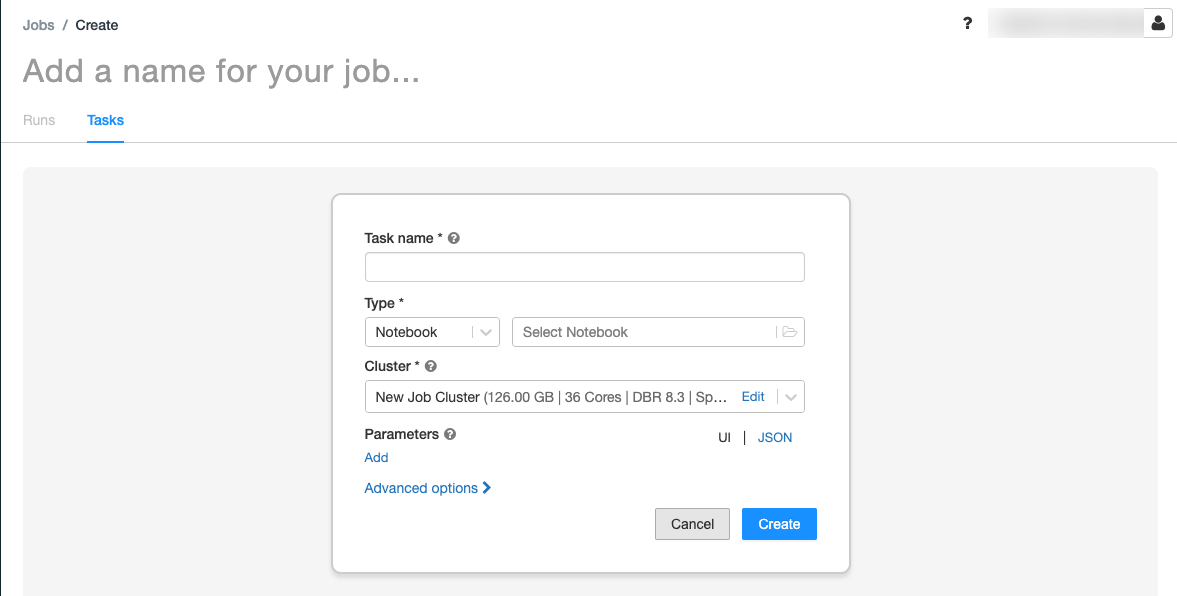
Substitua Adicione um nome para o seu trabalho… pelo nome do seu trabalho.
No campo Nome da tarefa, insira um nome para a tarefa; por exemplo, recuperar nomes de bebês.
No menu suspenso Tipo , selecione Notebook.
Utilize o navegador de arquivos para localizar o primeiro notebook que você criou, clique no nome do notebook e clique em Confirmar.
Clique em Criar tarefa.
Clique
 abaixo da tarefa que você acabou de criar para adicionar outra tarefa.
abaixo da tarefa que você acabou de criar para adicionar outra tarefa.No campo Nome da tarefa, insira um nome para a tarefa; por exemplo, filtrar-nomes-bebe.
No menu suspenso Tipo , selecione Notebook.
Use o explorador de arquivos para localizar o segundo notebook que você criou, clique no nome do notebook e clique em Confirmar.
Clique em Adicionar em Parâmetros. No campo Chave, digite
year. No campo Valor, digite2014.Clique em Criar tarefa.
Execute o job
Para executar o Job imediatamente, clique  no canto superior direito. Você também pode executar o Job clicando na guia Execução e clicando em Execução Agora na tabela Execução Ativa .
no canto superior direito. Você também pode executar o Job clicando na guia Execução e clicando em Execução Agora na tabela Execução Ativa .
Ver detalhes da execução
Clique na aba Execuções e clique no link da execução na tabela Execuções ativas ou na tabela Execuções concluídas (últimos 60 dias).
Clique em qualquer tarefa para ver o resultado e os detalhes. Por exemplo, clique na tarefa filtrar-nomes-bebe para ver a saída e executar os detalhes da tarefa de filtro:
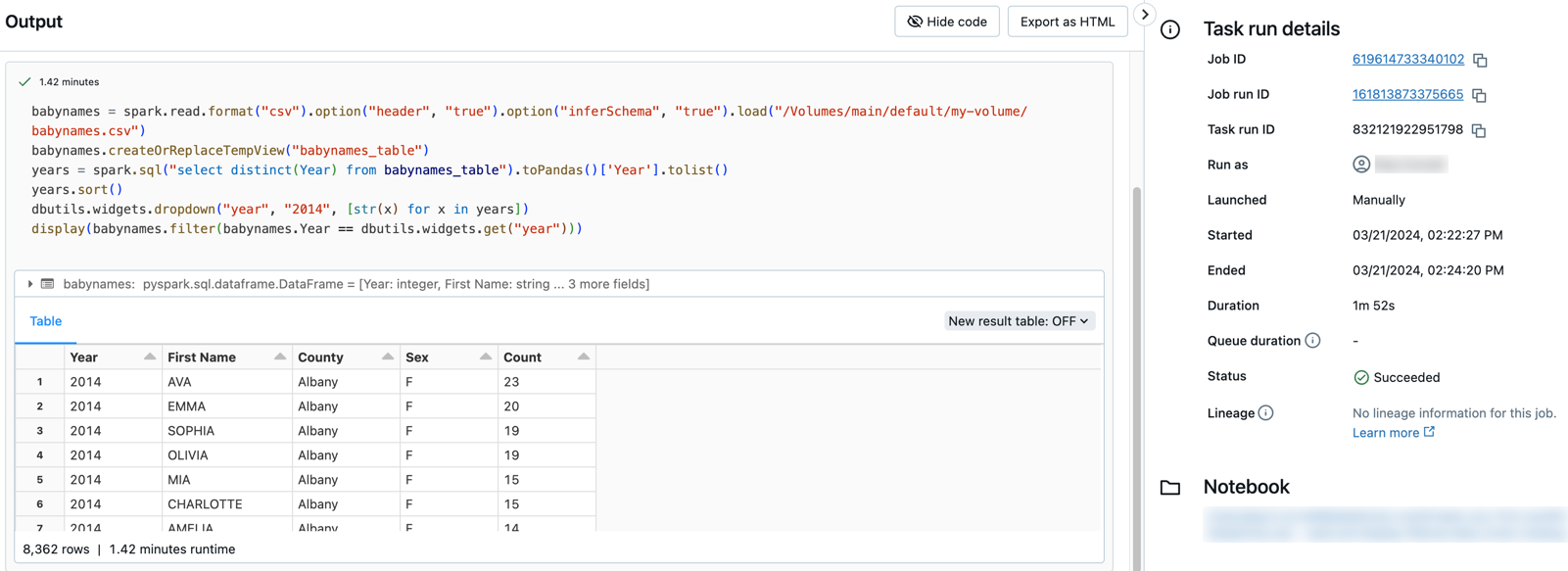
Executar com outros parâmetros
Para executar novamente o job e filtrar nomes de bebês de outro ano:
Clique
 próximo a execução Agora e selecione execução Agora com Parâmetros Diferentes ou clique em execução Agora com Parâmetros Diferentes na tabela de execução Ativa .
próximo a execução Agora e selecione execução Agora com Parâmetros Diferentes ou clique em execução Agora com Parâmetros Diferentes na tabela de execução Ativa .No campo Valor, digite
2015.Clique em Executar.