Databricksジョブで最初のワークフローを作成する
この記事では、サンプルデータセットを読み込んで処理するタスクをオーケストレーションするDatabrickジョブを説明します。このクイックスタートで、以下ができるようになります:
新しいノートブックを作成し、年ごとの人気の赤ちゃんの名前を含むサンプルデータセットを取得するコードを追加する。
サンプル データセットをUnity Catalogに保存します。
新しいノートブックを作成し、 Unity Catalogからデータセットを読み取り、年でフィルターし、結果を表示するコードを追加します。
新しいジョブを作成し、ノートブックを使って2つのタスクを設定する。
ジョブを実行し、結果を表示する。
要件
に Unity Catalogボリューム が必要です。この記事では、mainという名前のカタログ内の default という名前のスキーマ内の my-volume という名前のボリュームを使用します。また、Unity Catalog で次の権限を持っている必要があります。
READ VOLUMEWRITE VOLUME、またはALL PRIVILEGESは、my-volumeボリュームです。USE SCHEMAまたはdefaultスキーマのALL PRIVILEGES。USE CATALOGまたはmainカタログの場合はALL PRIVILEGES。
これらの権限を設定するには、 Databricks管理者またはUnity Catalog権限とセキュリティ保護可能なオブジェクトを参照してください。
ノートブックの作成
データの取得と保存
ノートブックを作成してサンプル データセットを取得し、 Unity Catalogに保存するには:
Databricks ランディング ページに移動し、サイドバーの [
 新規] をクリックして [ノートブック] を選択します。Databricks によって、既定のフォルダーに新しい空白のノートブックが作成されて開きます。 デフォルト言語は最近使用した言語であり、ノートブックは最近使用したコンピュートリソースに自動的にアタッチされます。
新規] をクリックして [ノートブック] を選択します。Databricks によって、既定のフォルダーに新しい空白のノートブックが作成されて開きます。 デフォルト言語は最近使用した言語であり、ノートブックは最近使用したコンピュートリソースに自動的にアタッチされます。必要に応じて、 デフォルト言語を Python に変更します。
次のPythonコードをコピーして、ノートブックの最初のセルに貼り付けます。
import requests response = requests.get('https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv') csvfile = response.content.decode('utf-8') dbutils.fs.put("/Volumes/main/default/my-volume/babynames.csv", csvfile, True)
フィルタリングされたデータの読み取りと表示
フィルタリング用のデータを読み取って表示するノートブックを作成するには、次の手順を実行します。
Databricks ランディング ページに移動し、サイドバーの [
新規] をクリックして [ノートブック] を選択します。Databricks によって、既定のフォルダーに新しい空白のノートブックが作成されて開きます。 デフォルト言語は最近使用した言語であり、ノートブックは最近使用したコンピュートリソースに自動的にアタッチされます。必要に応じて、 デフォルト言語を Python に変更します。
次のPythonコードをコピーして、ノートブックの最初のセルに貼り付けます。
babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/Volumes/main/default/my-volume/babynames.csv") babynames.createOrReplaceTempView("babynames_table") years = spark.sql("select distinct(Year) from babynames_table").toPandas()['Year'].tolist() years.sort() dbutils.widgets.dropdown("year", "2014", [str(x) for x in years]) display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
ジョブの作成
サイドバーの
 [ワークフロー]をクリックします。
[ワークフロー]をクリックします。をクリックします
 。
。タスクタブに、タスクの作成ダイアログが表示されます。
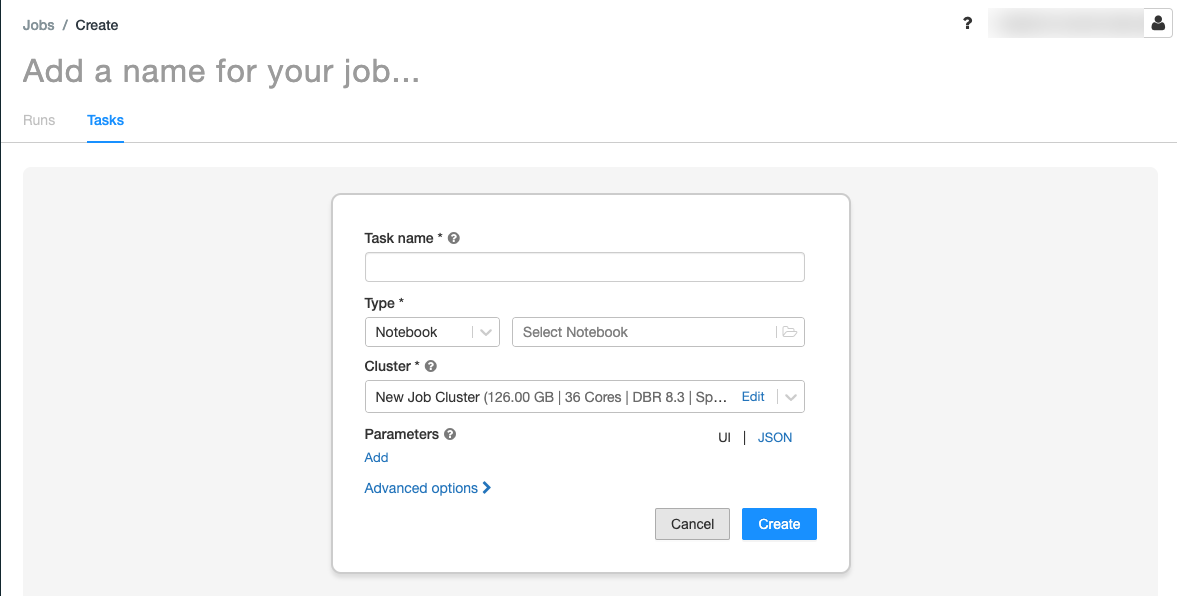
Add a name for your job...(ジョブの名前の追加)をジョブ名に置き換えてください。
タスク名フィールドにタスクの名前を入力します。(例: retrieve-baby-names(赤ちゃんの名前を取得))
[ 種類 ] ドロップダウン メニューで、[ ノートブック] を選択します。
ファイルブラウザを使用して最初に作成したノートブックを探し、ノートブック名をクリックして、確認をクリックします。
タスクの作成をクリックします。
作成したタスクの下をクリックして
 、別のタスクを追加します。
、別のタスクを追加します。タスク名フィールドにタスクの名前を入力します。(例: filter-baby-names(赤ちゃんの名前をフィルタリング))
[ 種類 ] ドロップダウン メニューで、[ ノートブック] を選択します。
ファイルブラウザを使用して2番目に作成したノートブックを探し、ノートブック名をクリックして、確認をクリックします。
パラメーターの下の追加をクリックします。キーフィールドに
yearを入力します。値フィールドに2014を入力します。タスクの作成をクリックします。
 。 「実行」タブをクリックし、「 アクティブな実行」 表の「 今すぐ実行 」をクリックして、ジョブを実行することもできます。
。 「実行」タブをクリックし、「 アクティブな実行」 表の「 今すぐ実行 」をクリックして、ジョブを実行することもできます。 実行の詳細の表示
実行タブをクリックし、アクティブな実行テーブルまたは完了した実行(過去60日間)テーブルで実行のリンクをクリックします。
いずれかのタスクをクリックすると、出力と詳細が表示されます。たとえば、 filter-baby-namesタスクをクリックすると、フィルタータスクの出力と実行の詳細が表示されます:

別のパラメータで実行
ジョブを再実行し、別の年の赤ちゃんの名前をフィルタリングするには、次の手順を実行します:
 「今すぐ実行」の横をクリッ ク し 、「別のパラメーターで今すぐ実行」を選択するか 、「 アクティ ブな 実行」テーブル で「 別のパラメーターで 今すぐ実行 」をクリックしま す。
「今すぐ実行」の横をクリッ ク し 、「別のパラメーターで今すぐ実行」を選択するか 、「 アクティ ブな 実行」テーブル で「 別のパラメーターで 今すぐ実行 」をクリックしま す。値フィールドに
2015を入力します。実行をクリックします。