Databricksジョブを作成して実行する
この記事では、ジョブUIを使用してDatabricksジョブを作成および実行する方法について詳しく説明します。
ジョブの構成オプションと既存のジョブの編集方法については、「Databricksジョブの設定を構成する」を参照してください。
ジョブの実行を管理および監視する方法については、「ジョブの実行の表示および管理」を参照してください。
Databricksジョブで最初のワークフローを作成するには、クイックスタートを参照してください。
重要
ワークスペースの同時タスク実行数は1000に制限されています。すぐに開始できない実行を要求すると、
429 Too Many Requests応答が返されます。ワークスペースが1時間に作成できるジョブの数は10000に制限されています(「実行の送信」を含む)。この制限は、REST APIおよびノートブック・ワークフローによって作成されたジョブにも影響します。
CLI、API、またはノートブックを使用してジョブを作成および実行する
Databricks CLI を使用してジョブを作成および実行する方法については、「 Databricks CLI とは」を参照してください。
ジョブAPIを使用してジョブを作成および実行する方法については、REST APIリファレンスの「ジョブ」を参照してください。
Databricksノートブックで直接ジョブを実行しスケジュールする方法については、「スケジュールされたノートブックジョブの作成と管理」を参照してください。
ジョブを作成する
次のいずれかを実行します。
クリック
 サイドバーのワークフローをクリックして
サイドバーのワークフローをクリックして 。
。サイドバーで、[
 新規 ] をクリックし 、[ジョブ] を選択します。
新規 ] をクリックし 、[ジョブ] を選択します。
「タスク」タブには、「タスクの作成」ダイアログとともに、ジョブレベルの設定を含む「ジョブの詳細」サイドパネルが表示されます。
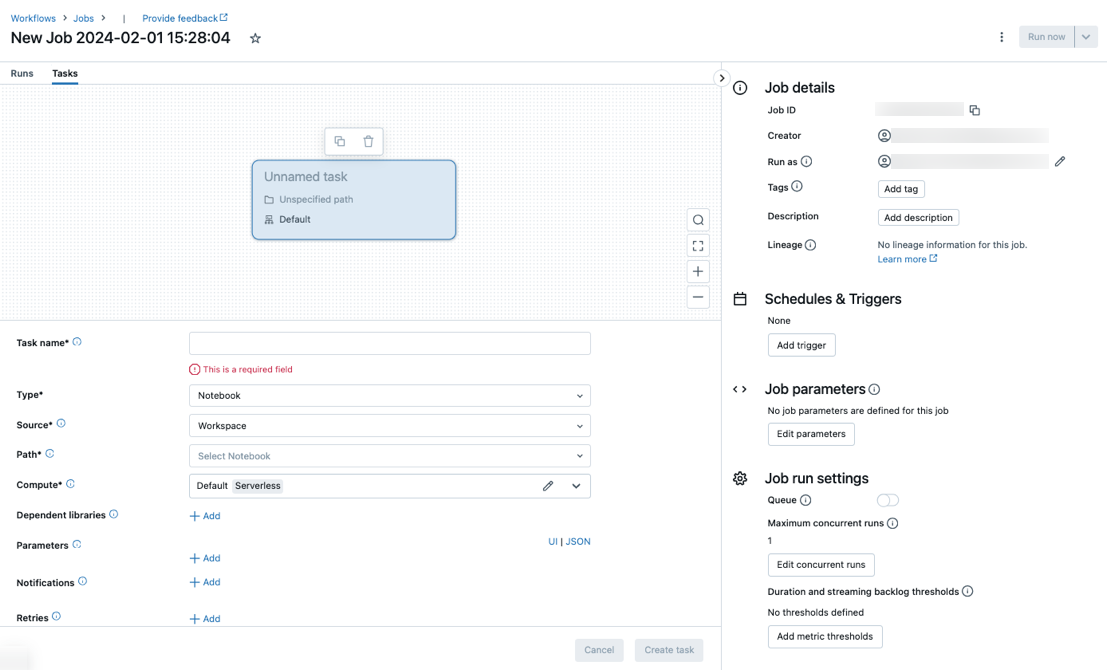
New Job…を実際のジョブ名に置き換えます。
「タスク名」フィールドにタスクの名前を入力します。
[ タイプ ] ドロップダウン メニューで、実行するタスクのタイプを選択します。 「タスク・タイプ・オプション」を参照してください。
タスクが実行されるクラスターを構成します。 [コンピュート]ドロップダウン メニューで、 [新しいジョブ クラスター]または[既存の汎用クラスター]を選択します。
新しいジョブ クラスター : クラスターのドロップダウン メニューで [編集 ] をクリックし、 クラスターの構成 を完了します。
Existing All-Purpose クラスター: [クラスター] ドロップダウン メニューで既存のクラスターを選択します。 クラスターを新しいページで開くには、クラスターの名前と説明の右側にあるアイコンをクリックします
 。
。
タスクを実行するクラスターの選択と設定の詳細については、「ジョブでDatabricksコンピューティングを使用する」を参照してください。
依存ライブラリを追加するには、[依存ライブラリ] の横にある [+ 追加] をクリックします。依存ライブラリの構成を参照してください。
タスクのパラメーターを渡すことができます。 パラメーターの書式設定と受け渡しの要件については、「 Databricks ジョブ タスクにパラメーターを渡す」を参照してください。
必要に応じて、タスクの開始、成功、または失敗に関する通知を受信するには、「電子メール」の横にある「+ 追加」をクリックします。失敗通知は、最初のタスク失敗時およびその後の再試行時に送信されます。通知をフィルタリングして送信される電子メールの数を減らすには、 「スキップされた実行の通知をミュートする」、「キャンセルされた実行の通知をミュートする」、または「最後の再試行まで通知をミュートする」をオンにします。
必要に応じて、タスクの再試行ポリシーを構成するには、[再試行] の横にある [+ 追加] をクリックします。「 タスクの再試行ポリシーを構成する」を参照してください。
必要に応じて、タスクの予想される期間またはタイムアウトを構成するには、[期間のしきい値] の横にある [+ 追加] をクリックします。「タスクの予想完了時間またはタイムアウトを構成する」を参照してください。
「作成」をクリックします。
最初のタスクを作成したら、通知、ジョブ トリガー、アクセス許可などのジョブ レベルの設定を構成できます。 ジョブの編集を参照してください。
別のタスクを追加するには、DAG ビュー内をクリックします  。 共有クラスターオプションは、前のタスクに対して 新しいジョブクラスター を構成した場合に提供されます。 タスクを作成または編集するときに、タスクごとにクラスターを構成することもできます。 タスクを実行するクラスターの選択と構成の詳細については、「 ジョブで Databricks コンピュートを使用する」を参照してください。
。 共有クラスターオプションは、前のタスクに対して 新しいジョブクラスター を構成した場合に提供されます。 タスクを作成または編集するときに、タスクごとにクラスターを構成することもできます。 タスクを実行するクラスターの選択と構成の詳細については、「 ジョブで Databricks コンピュートを使用する」を参照してください。
必要に応じて、通知、ジョブ トリガー、アクセス許可などのジョブ レベルの設定を構成できます。 「ジョブの編集」を参照してください。また、ジョブのタスクと共有されるジョブレベルのパラメーターを構成することもできます。 「すべてのジョブ タスクのパラメーターの追加」を参照してください。
タスクタイプのオプション
Databricksジョブに追加できるタスクの種類と、さまざまなタスクの種類で利用可能なオプションを以下に示します。
ノートブック: [ ソース ] ドロップダウン メニューで、 [ワークスペース] を選択して、Databricks ワークスペース フォルダーにあるノートブックを使用するか、リモート Git リポジトリにあるノートブックの Git プロバイダー を使用します。
ワークスペース:ファイルブラウザを使用してノートブックを探し、ノートブック名をクリックして、「確認」をクリックします。
Git プロバイダー: [ 編集 ] をクリックし、Git リポジトリ情報を入力します。 「 Databricks ジョブでバージョン管理されたソース コードを使用する」を参照してください。
注:
ノートブック・セルの合計出力(すべてのノートブック・セルの合計出力)には、20MBのサイズ制限が適用されます。さらに、個々のセル出力には8MBのサイズ制限が適用されます。セル出力の合計サイズが20MBを超える場合、または個々のセルの出力が8MBを超える場合、実行はキャンセルされ、失敗としてマークされます。
JAR:「メインクラス」を指定します。mainメソッドを含むクラスの完全修飾名(
org.apache.spark.examples.SparkPiなど)を使用します。次に、「依存ライブラリ」の下の「追加」をクリックして、タスクの実行に必要なライブラリを追加します。これらのライブラリのいずれかにメインクラスが含まれている必要があります。JARタスクの詳細については、「DatabricksジョブでのJARの使用」を参照してください。
Spark Submit:「パラメーター」テキストボックスで、メインクラス、ライブラリJARへのパス、およびJSON形式の文字列の配列としてフォーマットされたすべての引数を指定します。次の例では、Apache Sparkの例の
DFSReadWriteTestを実行するように、spark-submitタスクを設定します。["--class","org.apache.spark.examples.DFSReadWriteTest","dbfs:/FileStore/libraries/spark_examples_2_12_3_1_1.jar","/discover/databricks-datasets/README.md","/FileStore/examples/output/"]
重要
Spark-Submitタスクにはいくつかの制限があります。
Spark-Submitタスクは、新しいクラスターでのみ実行できます。
Spark-submit は、クラスターのオートスケールをサポートしていません。 オートスケールの詳細については、「 オートスケールのクラスター化」を参照してください。
Spark-submit では、 Databricks ユーティリティ (dbutils) 参照はサポートされていません。 Databricks ユーティリティを使用するには、代わりに JAR タスクを使用します。
Sparkストリーミング ジョブでは、最大並列実行数を 1 より大きく設定しないでください。 ストリーミング ジョブは、cron 式
"* * * * * ?"(毎分) を使用して実行するように設定する必要があります。 ストリーミング タスクは継続的に実行されるため、常にジョブの最後のタスクにする必要があります。
Python スクリプト: [ソース] ドロップダウン メニューで、Python スクリプトの場所 (ローカル ワークスペース内のスクリプトの場合は [ワークスペース]、DBFS またはクラウド ストレージにあるスクリプトの場合は [DBFS]) を選択します。[ パス ] テキストボックスに、Python スクリプトへのパスを入力します。
ワークスペース:「Pythonファイルの選択」ダイアログで、Pythonスクリプトを参照し、「確認」をクリックします。
DBFS:DBFSまたはクラウドストレージ上のPython スクリプトのURIを入力します。
dbfs:/FileStore/myscript.py。Delta Live Tables パイプライン: [パイプライン] ドロップダウン メニューで、既存の Delta Live Tables パイプラインを選択します。
重要
パイプライン タスクでは、トリガーされたパイプラインのみを使用できます。連続パイプラインは、ジョブ タスクとしてサポートされていません。 トリガーされたパイプラインと継続的なパイプラインの詳細については、「 継続的なパイプライン実行とトリガーされたパイプラインの実行」を参照してください。
Python wheel : [パッケージ名]テキスト ボックスに、インポートするパッケージを入力します (例:
myWheel-1.0-py2.py3-none-any.whl)。 [エントリ ポイント]テキスト ボックスに、 Python wheelファイルの開始時に呼び出す関数を入力します。 [依存ライブラリ]の下にある[追加]をクリックして、タスクの実行に必要なライブラリを追加します。dbt: dbt タスクの構成の詳細な例については、「 Databricks ジョブで dbt 変換を使用する 」を参照してください。
ジョブの実行: [ジョブ] ドロップダウン メニューで、タスクによって実行する ジョブ を選択します。 実行するジョブを検索するには、[ ジョブ ] メニューにジョブ名の入力を開始します。
重要
Run Jobタスク、または3つ以上のRun Jobタスクをネストするジョブを使用する場合は、循環依存関係のあるジョブを作成しないでください。循環依存関係は、直接的または間接的に相互にトリガーするRun Jobタスクです。たとえば、ジョブAはジョブBをトリガーし、ジョブBはジョブAをトリガーします。Databricksでは、循環依存関係のあるジョブや、3つを超えるRun Jobタスクをネストするジョブはサポートされていないため、将来のリリースではこれらのジョブの実行が許可されなくなる可能性があります。If/else: タスクの使用方法については、「
If/else conditionIf/else 条件タスクを使用してジョブに分岐ロジックを追加する 」を参照してください。
Databricksジョブタスクにパラメーターを渡す
ジョブタスクの種類の多くにパラメータを渡すことができます。タスクの種類ごとに、パラメーターのフォーマットと受け渡しに関する要件が異なります。
現在のタスクに関する情報 (タスク名など) にアクセスしたり、ジョブの開始時刻や現在のジョブ実行の識別子など、ジョブ タスク間で現在の実行に関するコンテキストを渡したりするには、 動的な値参照を使用します。 使用可能な動的な値参照のリストを表示するには、「 動的な値を参照」をクリックします。
タスクが属するジョブにジョブ・パラメーターが構成されている場合、タスク・パラメーターを追加すると、それらの パラメーター が表示されます。 ジョブ・パラメーターとタスク・パラメーターがキーを共有している場合は、ジョブ・パラメーターが優先されます。 ジョブ・パラメーターと同じキーを持つタスク・パラメーターを追加しようとすると、UI に警告が表示されます。 JAR タスクや Spark Submit タスクなど、キーと値のパラメーターが構成されていないタスクにジョブパラメーターを渡すには、引数を {{job.parameters.[name]}}として書式設定し、[name] をパラメーターを識別するkeyに置き換えます。
ノートブック: [ 追加 ] をクリックし、タスクに渡す各パラメーターのキーと値を指定します。 [ Run a job with different parameters] (異なるパラメーターでジョブを実行する ) オプションを使用してタスクを手動で実行するときに、パラメーターを上書きまたは追加できます。 パラメーターは、パラメーターのキーによって指定された ノートブック ウィジェット の値を設定します。
JAR: JSON 形式の文字列配列を使用してパラメーターを指定します。 これらの文字列は、メインクラスのメインメソッドに引数として渡されます。 JAR ジョブ・パラメーターの構成を参照してください。
Spark Submit: パラメーターは、JSON形式の文字列配列で指定します。Apache Sparkのspark-submit規約に従い、JARパス以降のパラメータはmainクラスのmainメソッドに渡されます。
Python wheel : [問題]ドロップダウン メニューで、 [位置引数] を選択して文字列のJSON形式の配列として問題を入力するか、 [キーワード引数] > [追加]を選択して各問題のキーと値を入力します。 位置引数とキーワード引数はどちらもコマンドライン引数としてPython wheelタスクに渡されます。 ファイルにパッケージ化された スクリプトの引数を読み取る例については、PythonPython wheel 「 ジョブで ファイルを使用する」 を参照してください。Python wheelDatabricks
ジョブの実行: ジョブに渡す各ジョブ・パラメーターのキーと値を入力します。
Pythonスクリプト: JSON 形式の文字列配列を使用してパラメーターを指定します。これらの文字列は引数として渡され、位置引数として読み取ったり、Pythonのargparseモジュールを使用して解析したりできます。
タスクパスをコピーする
ノートブックタスクなどの特定のタスクタイプでは、タスクソースコードへのパスをコピーできます。
「タスク」タブをクリックします。
コピーするパスを含むタスクを選択します。
タスクパスの横をクリックして
 、パスをクリップボードにコピーします。
、パスをクリップボードにコピーします。
既存のジョブからジョブを作成する
既存のジョブを複製することで、新しいジョブをすばやく作成できます。 ジョブを複製すると、ジョブ ID を除き、ジョブの同一のコピーが作成されます。 ジョブのページで、ジョブ名の横にある [ その他 ] をクリックし、ドロップダウン メニューから [ クローン ] を選択します。
既存のタスクからタスクを作成する
既存のタスクのクローンを作成することで、新しいタスクをすばやく作成できます。
ジョブのページで、「タスク」タブをクリックします。
クローンするタスクを選択してください。
クリック
 タスクのクローン作成を選択します。
タスクのクローン作成を選択します。
ジョブを実行する
サイドバーの
[ワークフロー]をクリックします。ジョブを選択し、「実行」タブをクリックします。ジョブをすぐに実行することも、ジョブを後で実行するようにスケジュールすることもできます。
複数のタスクを含むジョブ内の 1 つ以上のタスクが失敗した場合は、失敗したタスクのサブセットを再実行できます。 「失敗したタスクとスキップされたタスクを再実行する」を参照してください。
ジョブをすぐに実行する
ジョブをすぐに実行するには、  をクリックします。
をクリックします。
ヒント
「今すぐ実行」 をクリックすると、ノートブックタスクを使用してジョブのテストを実行できます。ノートブックに変更を加える必要がある場合は、ノートブックの編集後にもう一度「今すぐ実行」をクリックすると、新しいバージョンのノートブックが自動的に実行されます。
別のパラメータで今すぐジョブを実行
「別のパラメータで今すぐ実行」 を使用すると、別のパラメータまたは既存のパラメータの別の値を使用してジョブを再実行できます。
注:
ジョブ・パラメーターが導入される前に実行されたジョブが、同じキーを持つタスク・パラメーターをオーバーライドした場合、ジョブ・パラメーターをオーバーライドすることはできません。
「今すぐ実行」の横にある をクリックして
 「別のパラメーターで今すぐ実行」を選択するか、「アクティブな実行」表で「別のパラメーターで今すぐ実行」をクリックします。タスクのタイプに応じて新しいパラメーターを入力します。 「 Databricks ジョブ タスクにパラメーターを渡す」を参照してください。
「別のパラメーターで今すぐ実行」を選択するか、「アクティブな実行」表で「別のパラメーターで今すぐ実行」をクリックします。タスクのタイプに応じて新しいパラメーターを入力します。 「 Databricks ジョブ タスクにパラメーターを渡す」を参照してください。「実行」をクリックします。
サービスプリンシパルとしてジョブを実行
注:
ジョブ実行SQLクエリがSQLタスクを使用している場合、ジョブ実行がサービスプリンシパルである場合でも、クエリの実行に使用されるIDは各クエリの共有設定によって決まります。 クエリがRun as ownerに構成されている場合、クエリは常にサービスプリンシパルの ID ではなく、所有者の ID を使用して実行されます。 クエリがRun as viewerに構成されている場合、クエリはサービスプリンシパルの ID を使用して実行されます。 クエリ共有設定の詳細については、「 クエリのアクセス許可を構成する」を参照してください。
デフォルトにより、ジョブ所有者の ID としてジョブが実行されます。 これは、ジョブがジョブ所有者の権限を引き継ぐことを意味します。 ジョブは、ジョブ所有者がアクセス権限を持つデータと Databricks オブジェクトにのみアクセスできます。 ジョブが実行しているアイデンティティをサービスプリンシパルに変更できます。 次に、ジョブは所有者の代わりにそのサービスプリンシパルの権限を引き継ぎます。
「実行ユーザー」設定を変更するには、ジョブに対する CAN MANAGE または IS OWNER 権限のいずれかが必要です。 実行設定を自分自身、またはサービスプリンシパル ユーザーロールを持つワークスペース内の任意のサービスプリンシパルに設定できます。 詳細については、 「サービスプリンシパルを管理するためのロール」を参照してください。
注:
ワークスペースのRestrictWorkspaceAdmins設定がALLOW ALLに設定されている場合、ワークスペース管理者は、ワークスペース内の任意のユーザーに [実行ユーザーとして] 設定を変更することもできます。 ワークスペース管理者が、自分自身またはサービスプリンシパルユーザーロールを持つサービスプリンシパルに対してのみ実行設定を変更できるように制限するには、 「ワークスペース管理者を制限する」を参照してください。
「別のユーザーとして実行」フィールドを変更するには、次の手順を実行します。
サイドバーで、
[ワークフロー]をクリックします。「名前」列で、ジョブ名をクリックします。
「ジョブの詳細」サイドパネルで、「実行」フィールドの横にある鉛筆アイコンをクリックします。
サービスプリンシパルを検索して選択します。
「保存」をクリックします。
ワークスペース サービスプリンシパル を使用して、 ユーザー ロールを持つ サービスプリンシパルを一覧表示することもできます。API詳細については、 「使用できるサービスプリンシパルの一覧」を参照してください。
スケジュールに従ってジョブを実行する
スケジュールを使用して、指定した日時に Databricks ジョブを自動的に実行できます。 ジョブ・スケジュールの追加を参照してください。
継続的なジョブを実行する
ジョブが常にアクティブに実行されていることを確認できます。 「継続的なジョブの実行」を参照してください。
新しいファイルが到着したらジョブを実行する
新しいファイルがUnity Catalog外部ロケーションまたはボリュームに到着したときにジョブの実行をトリガーするには、ファイル到着トリガーを使用します。
Databricks アセットバンドルで作成されたジョブを表示および実行する
Databricks ジョブ UI を使用して、Databricks アセット バンドルによってデプロイされたジョブを表示および実行できます。 デフォルトでは、これらのジョブはジョブ UI で読み取り専用になります。 バンドルによってデプロイされたジョブを編集するには、バンドル構成ファイルを変更し、ジョブを再デプロイします。 バンドル構成にのみ変更を適用すると、バンドル ソース ファイルは常に現在のジョブ構成をキャプチャするようになります。
ただし、ジョブをすぐに変更する必要がある場合は、ジョブをバンドル構成から切断して、UI でジョブ設定を編集できるようにすることができます。 ジョブを切断するには、 「ソースから切断」をクリックします。 [ソースから切断] ダイアログで、 [切断] をクリックして確認します。
UI でジョブに加えた変更はバンドル設定には適用されません。 UI で行った変更をバンドルに適用するには、バンドル設定を手動で更新する必要があります。 ジョブをバンドル構成に再接続するには、バンドルを使用してジョブを再デプロイします。
同時実行の制限のためにジョブを実行できない場合はどうすればよいですか?
注:
UI でジョブが作成されると、キューイングはデフォルトで有効になります。
コンカレンシーの制限のためにジョブの実行がスキップされないようにするには、ジョブのキューイングを有効にします。 キューイングが有効な場合、ジョブ実行でリソースが使用できない場合、実行は最大 48 時間キューに入れられます。 容量が使用可能になると、ジョブ実行はキューから取り出され、実行されます。 キューに入れられた実行は、ジョブ の実行 リストと 最近のジョブ実行リストに表示されます。
実行は、次のいずれかの制限に達するとキューに入れられます。
ワークスペースで実行される最大並列アクティブ。
最大並列
Run Jobタスクはワークスペースで実行されます。ジョブの最大並列実行数。
キューイングは、そのジョブに対してのみキューが実行されるジョブレベルのプロパティです。
キューイングを有効または無効にするには、 [詳細設定]をクリックし、 [ジョブの詳細]サイド パネルの[キュー]切り替えボタンをクリックします。