Databricks ジョブの設定を構成する
この記事では、ジョブ UI での Databricks ジョブと個々のジョブ タスクの構成について詳しく説明します。 Databricks CLI を使用してジョブ設定を編集する方法については、CLI コマンドdatabricks jobs update -hを実行してください。 Jobs API の使用方法については、 「 Jobs API 」を参照してください。
ジョブで使用できる構成オプションもあれば、個々のタスクで使用できるオプションもあります。 たとえば、最大並列実行数はジョブでのみ設定できますが、再試行ポリシーはタスクごとに定義されます。
ジョブの編集
ジョブの構成を変更するには:
サイドバーの
 [ワークフロー]をクリックします。
[ワークフロー]をクリックします。[ 名前 ] 列で、ジョブ名をクリックします。
サイドパネルには、 ジョブの詳細が表示されます。 ジョブのトリガー、コンピュートの構成、 通知、並列実行の最大数の変更、期間しきい値の構成、およびタグの追加または変更を行うことができます。 ジョブのアクセス制御が有効になっている場合は、 ジョブの アクセス許可を編集することもできます。
すべてのジョブタスクのパラメーターを追加する
キーワード引数を受け入れるように構成されたPython wheelファイルなど、キーと値を受け入れる任意のジョブのタスクに渡されるジョブに 問題 を構成できます。 ジョブ レベルで設定された課題は、設定されたタスク レベルの課題に追加されます。 タスクに渡されたジョブの課題は、タスクに設定されたすべての課題とともにタスクの設定に表示されます。
また、 JAR タスクや Spark Submit タスクなど、キーと値のパラメーターで構成されていないタスクにジョブパラメーターを渡すこともできます。 これらのタスクにジョブ・パラメーターを渡すには、引数を {{job.parameters.[name]}}としてフォーマットし、 [name] をパラメーターを識別する key に置き換えます。
ジョブ・パラメーターは、タスク・パラメーターよりも優先されます。 ジョブ・パラメーターとタスク・パラメーターのキーが同じ場合、ジョブ・パラメーターはタスク・パラメーターをオーバーライドします。
構成済みのジョブ・パラメーターをオーバーライドしたり、 異なるパラメーターでジョブを実行し たり、ジョブ 実行を修復したりするときに、新しいジョブ・パラメーターを追加できます。
また、 一連の動的な値参照を使用して、ジョブとタスクに関するコンテキストを共有することもできます。
ジョブ・パラメーターを追加するには、「ジョブの詳細」サイド・パネルで「パラメーターの編集」をクリックし、各パラメーターのキーとデフォルト値を指定します。使用可能な動的な値参照のリストを表示するには、「 動的な値を参照」をクリックします。
ジョブにタグを追加する
ジョブにラベルまたは key:value 属性を追加するには、ジョブの編集時に タグ を追加します。 タグを使用して、[ ジョブ] リスト内のジョブをフィルター処理できます。たとえば、 department タグを使用して、特定の部門に属するすべてのジョブをフィルター処理できます。
注
ジョブ タグは、個人を特定できる情報やパスワードなどの機密情報を格納するようには設計されていないため、Databricks では、機密性の低い値にのみタグを使用することをお勧めします。
タグは、ジョブの実行時に作成されるジョブ クラスターにも伝播されるため、既存のクラスター モニタリングでタグを使用できるようになります。
タグを追加または編集するには、[ジョブの詳細] サイド パネルで [+ タグ] をクリックします。タグは、キーと値またはラベルとして追加できます。 ラベルを追加するには、[ キー ] フィールドにラベルを入力し、[ 値 ] フィールドを空のままにします。
ジョブへのアクセスを制御する
ジョブ アクセス制御を使用すると、ジョブの所有者と管理者は、ジョブに対するきめ細かなアクセス許可を付与できます。 ジョブ所有者は、ジョブの結果を表示できる他のユーザーまたはグループを選択できます。 所有者は、ジョブの実行を管理できるユーザーを選択することもできます ([今すぐ実行] と [実行のキャンセル] アクセス許可)。
ジョブ 権限レベルの詳細については、 「ジョブ ACL」を参照してください。
ジョブに対する権限を管理するには、ジョブに対する CAN MANAGE または IS OWNER 権限が必要です。
サイドバーで、 「ジョブの実行」をクリックします。
ジョブの名前をクリックします。
[ジョブの詳細]パネルで、 [権限の編集]をクリックします。
[アクセス許可の設定]で、 [ユーザー、グループ、またはサービスプリンシパルの選択]ドロップダウン メニューをクリックし、ユーザー、グループ、またはサービスプリンシパルを選択します。
![[権限設定] ダイアログ](../../_images/select-permission-job.png)
「追加」をクリックします。
「 保存」をクリックします。
ジョブ所有者を管理する
デフォルトでは、ジョブの作成者は IS OWNER 権限を持ち、ジョブの「実行対象」設定のユーザーです。 「実行として」設定のユーザーの ID としてのジョブの実行。 設定としての実行の詳細については、 「サービスプリンシパルとしてジョブを実行する」を参照してください。
ワークスペース管理者は、ジョブの所有者を自分自身に変更できます。 所有権が譲渡されると、前の所有者に CAN MANAGE 権限が付与されます。
注
ワークスペースのRestrictWorkspaceAdmins設定がALLOW ALLに設定されている場合、ワークスペース管理者はジョブの所有者をワークスペース内の任意のユーザーまたはサービスプリンシパルに変更できます。 ワークスペース管理者がジョブ所有者を自分自身のみに変更できるように制限するには、 「ワークスペース管理者を制限する」を参照してください。
最大並列実行数の構成
このジョブの並列実行の最大数を設定するには、 「詳細設定」の「同時実行の編集」をクリックします。 Databricks 、新しい 実行 を開始しようとしたときに、 ジョブ がアクティブな 実行 の最大数にすでに達している場合、 実行 をスキップします。 同じジョブを複数回同時に実行するには、この値をデフォルトの 1 より大きく設定します。 これは、たとえば、ジョブを頻繁にトリガーし、連続する実行が互いに重複することを許可する場合や、入力の引数が異なる複数の実行をトリガーする場合に便利です。
ジョブ実行のキューイングを有効にする
同時実行制限のためにジョブをすぐに実行できない場合に、ジョブの実行をキューに入れて後で実行できるようにするには、 [詳細設定]の[キュー]トグルをクリックします。 「同時実行制限のためにジョブを実行できない場合はどうすればよいですか?」を参照してください。
注
2024 年 4 月 15 日以降に UI を通じて作成されたジョブでは、キューイングがデフォルトで有効になります。
ジョブの予想完了時間またはタイムアウトを構成する
ジョブの予想完了時間やジョブの最大完了時間など、ジョブのオプションの期間しきい値を構成できます。 期間のしきい値を構成するには、[ 期間のしきい値の設定] をクリックします。
ジョブの予想完了時間を構成するには、[ 警告 ] フィールドに予想される期間を入力します。 ジョブがこのしきい値を超えた場合は、実行速度の遅いジョブの通知を構成できます。 「 実行速度の遅いジョブや遅延ジョブの通知を構成する」を参照してください。
ジョブの最大完了時間を設定するには、[ タイムアウト(Timeout )] フィールドに最大期間を入力します。 この時間内にジョブが完了しない場合、Databricks はその状態を "タイムアウト" に設定し、ジョブは停止します。
タスクを編集する
タスク設定オプションを設定するには:
サイドバーの
[ワークフロー]をクリックします。[ 名前 ] 列で、ジョブ名をクリックします。
[タスク] タブをクリックし、編集するタスクを選択します。
タスクの依存関係を定義する
ジョブ内のタスクの実行順序は、[ 依存先 ] ドロップダウン メニューを使用して定義できます。 このフィールドは、ジョブ内の 1 つ以上のタスクに設定できます。
注
[依存先] は、ジョブが 1 つのタスクのみで構成されている場合は表示されません。
タスクの依存関係を構成すると、ジョブ スケジューラで実行順序を表す一般的な方法であるタスク実行の有向非巡回グラフ (DAG) が作成されます。 たとえば、次のジョブが 4 つのタスクで構成されるとします。
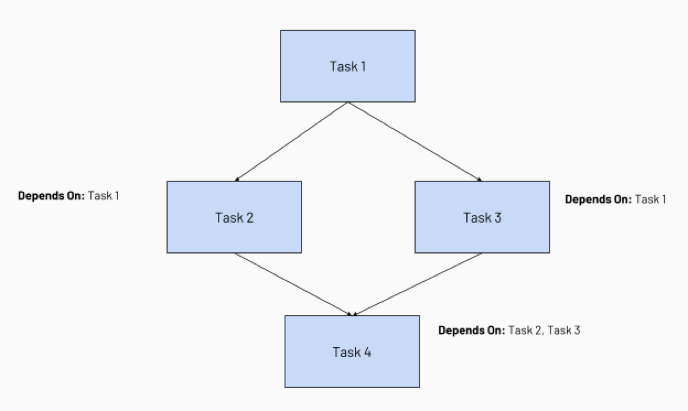
タスク 1 はルート タスクであり、他のタスクには依存しません。
タスク 2 とタスク 3 は、タスク 1 が最初に完了することに依存します。
最後に、タスク 4 は、タスク 2 とタスク 3 が正常に完了することに依存します。
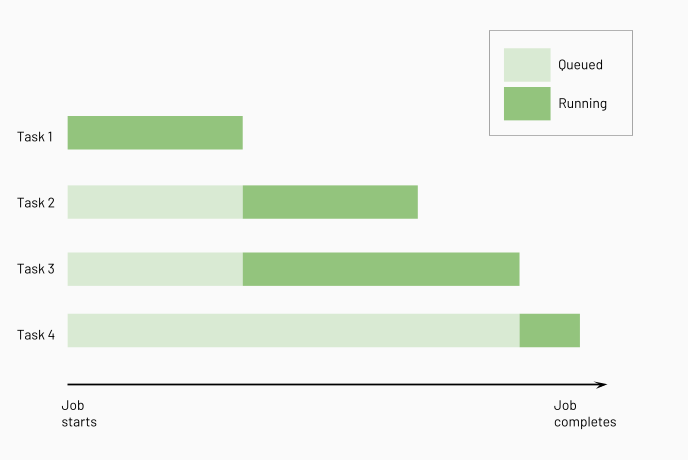
Databricks は、ダウンストリーム タスクを実行する前にアップストリーム タスクを実行し、できるだけ多くのタスクを並列に実行します。 次の図は、これらのタスクの処理順序を示しています。
タスクのクラスターを構成する
タスクを実行するクラスターを構成するには、[ クラスター ] ドロップダウン メニューをクリックします。 共有ジョブクラスターは編集できますが、他のタスクでまだ使用されている共有クラスターは削除できません。
タスクを実行するクラスターの選択と構成の詳細については、「 ジョブで Databricks コンピュートを使用する」を参照してください。
依存ライブラリの構成
依存ライブラリは、タスクの実行前にクラスターにインストールされます。 すべてのタスクの依存関係を設定して、実行を開始する前に確実にインストールされるようにする必要があります。 「ライブラリの依存関係の管理 」の推奨事項に従って、依存関係を指定します。
タスクの予想完了時間またはタイムアウトを構成する
タスクの予想完了時間やタスクの最大完了時間など、タスクの期間のしきい値を任意に設定できます。 期間のしきい値を構成するには、[ 期間のしきい値] をクリックします。
タスクの予想完了時間を設定するには、[ 警告 ] フィールドに期間を入力します。 タスクがこのしきい値を超えると、イベントがトリガーされます。 このイベントを使用して、タスクの実行速度が遅いときに通知できます。 「 実行速度の遅いジョブや遅延ジョブの通知を構成する」を参照してください。
タスクの最大完了時間を設定するには、[ タイムアウト ] フィールドに最大期間を入力します。 この時間内にタスクが完了しない場合、Databricks はその状態を "タイムアウト" に設定します。