Databricks Workflows の概要
Databricks Workflows は、Databricksデータインテリジェンスプラットフォームでデータ処理、機械学習、アナリティクスのパイプラインを調整します。 ワークフローには、Databricks ワークスペースで非対話型コードを実行するための Databricks ジョブや、信頼性と保守性に優れた ETL パイプラインを構築するための Delta Live Tables など、Databricks プラットフォームと統合されたフルマネージド オーケストレーション サービスがあります。
Databricks プラットフォームを使用してワークフローを調整する利点の詳細については、「 Databricks Workflows」を参照してください。
Databricks ワークフローの例
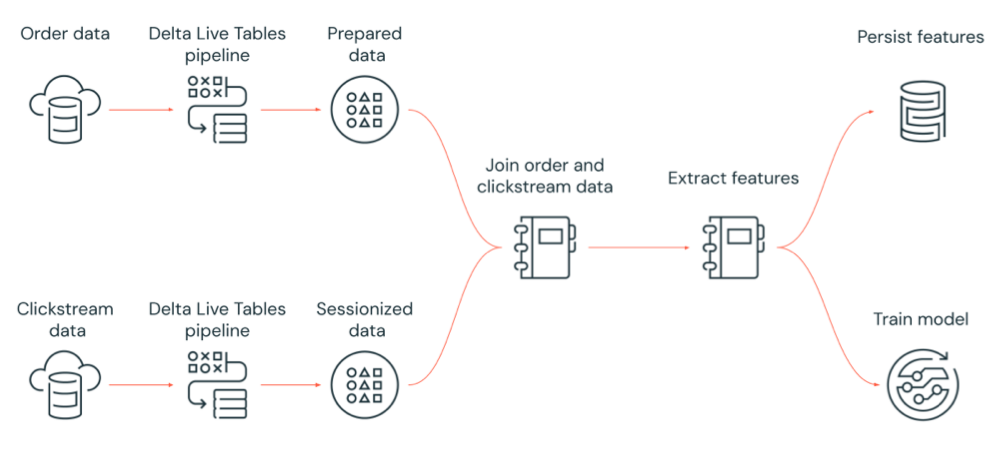
次の図は、Databricks ジョブによってオーケストレーションされるワークフローを示しています:
クラウドストレージから生のクリックストリームデータを取り込み、データをクリーンアップして準備し、データをセッション化し、セッション化された最終的なデータセットを Delta Lake に保存する Delta Live Tables パイプラインを実行します。
クラウドストレージから注文データを取り込み、処理のためにデータをクリーンアップおよび変換し、最終的なデータセットを Delta Lake に保存する Delta Live Tables パイプラインを実行します。
注文データとセッション化されたクリックストリームデータを結合して、分析用の新しいデータセットを作成します。
準備が完了したデータから特徴量を抽出します。
タスクを並行して実行し、特徴量を保持して、機械学習モデルをトレーニングします。
Databricks ジョブとは
注:
CLI 機能は、このリリースの時点で Databricks on Google Cloud では使用できません。
Databricks ジョブは、Databricks ワークスペースでデータ処理および分析アプリケーションを実行する方法です。 ジョブは、1 つのタスクで構成することも、複雑な依存関係を持つ大規模なマルチタスク ワークフローにすることもできます。 Databricks は、すべてのジョブのタスク オーケストレーション、クラスター管理、モニタリング、エラー レポートを管理します。 ジョブは、すぐに実行することも、使いやすいスケジューリングシステムを使用して定期的に実行することも、ジョブのインスタンスが常に実行されていることを確認するために継続的に実行することもできます。 ノートブック UI でジョブを対話的に実行することもできます。
ジョブの作成と実行は、ジョブ UI、Databricks CLI、および Jobs API を使って行うことができます。失敗したジョブまたはキャンセルされたジョブは、UI または API を使用して修復および再実行できます。UI、CLI、API、および通知(電子メール、Webhook 宛先、Slack 通知など)を使用して、ジョブの実行結果を監視できます。
Databricks CLI の使用方法については、 「Databricks CLI とは何ですか?」を参照してください。 。 Jobs API の使用方法については、 「 Jobs API 」を参照してください。
次のセクションでは、Databricks ジョブの重要な機能について説明します。
重要
ワークスペースの同時タスク実行数は 1000 に制限されています。すぐに開始できない実行を要求すると、
429 Too Many Requests応答が返されます。ワークスペースが 1 時間に作成できるジョブの数は 10000 に制限されています(「実行の送信」を含む)。この制限は、REST API およびノートブックワークフローによって作成されたジョブにも影響します。
ジョブタスクによるデータ処理と分析の実装
タスクを使用してデータ処理と分析のワークフローを実装します。ジョブは、1 つ以上のタスクで構成されます。ノートブック、JARS、Delta Live Tables パイプライン、または Python、Scala、Spark submit、Java アプリケーションを実行するジョブタスクを作成できます。ジョブタスクは、Databricks SQL クエリー、アラート、ダッシュボードをオーケストレーションして分析やビジュアライゼーションを作成したり、dbt タスクを使用してワークフロー内で dbt 変換を実行したりすることもできます。レガシーな Spark Submit アプリケーションもサポートされています。
別のジョブを実行するジョブにタスクを追加することもできます。この機能により、大きなプロセスを複数の小さなジョブに分割したり、複数のジョブで再利用できる汎用モジュールを作成したりできます。
タスクの実行順序を制御するには、タスク間の依存関係を指定します。タスクを順番に実行するように設定したり、並列して実行するように設定したりすることができます。
ジョブの対話的な実行、継続的な実行、ジョブトリガーを使用した実行
ジョブ UI、API、または CLI から対話的にジョブを実行したり、 継続的なジョブを実行したりできます。 ジョブを定期的に実行する スケジュールを作成したり 、Amazon S3、Azure storage、 などの外部ロケーションに 新しいファイルが到着したGoogle Cloud Storage ときにジョブを実行したりすることができます。
通知によるジョブの進捗状況の監視
ジョブまたはタスクが開始、完了、失敗したときに通知を受け取ることができます。通知は 1 つ以上の E メールアドレスまたはシステム送信先(Webhook 宛先や Slack など)に送信できます。「ジョブイベントの E メール通知とシステム通知を追加する」を参照してください。
システムテーブルを使用してジョブのコストとアクティビティを監視する
システムテーブルには、アカウント内のジョブアクティビティに関連するレコードを表示できるworkflowスキーマが含まれています。 ジョブのシステムテーブルリファレンスを参照してください。
ジョブ システムテーブルを課金テーブルと結合して、アカウント全体のジョブのコストを監視することもできます。 「システムテーブルを使用してジョブ コストを監視する」を参照してください。
Databricks コンピュートリソースを使用したジョブの実行
Databricks クラスターと SQL ウェアハウスは、ジョブ用のコンピュートリソースを提供しています。ジョブクラスター、All-Purpose クラスター、または SQL ウェアハウスを使用してジョブを実行できます。
ジョブクラスターは、ジョブまたは個々のジョブタスクのための専用クラスターです。ジョブは、すべてのタスクで共有されるジョブクラスターを使用することができます。また、タスクの作成または編集時に個々のタスク用のクラスターを設定することもできます。ジョブクラスターは、ジョブまたはタスクの開始時に作成され、ジョブまたはタスクの終了時に終了します。
All-Purpose クラスターは、手動で開始および終了する共有クラスターであり、複数のユーザーおよびジョブが共有できます。
リソースの使用を最適化するために、Databricks ではジョブにジョブクラスターを使用することをお勧めします。クラスターの起動の待機時間を短縮するには、All-Purpose クラスターの使用を検討してください。「ジョブで Databricks コンピュートを使用する」を参照してください。
SQLウェアハウスを使用して、dbt タスクで dbt 変換を実行します。
次のステップ
Databricks ジョブの使用を開始するには:
クイックスタートを使用して最初の Databricks ジョブを作成します。
Databricks ジョブユーザーインターフェイスを使用してワークフローを作成および実行する方法をご覧ください。
Databricks ジョブを使用したワークフローの構築、管理、トラブルシューティングの詳細については、以下をご覧ください。
タスク値を使用して、Databricks ジョブのタスク間で情報を伝達する方法をご覧ください。
タスク パラメーター変数を使用して、ジョブ実行に関するコンテキストをジョブ タスクに渡す方法について説明します。
タスクの依存関係のステータスに基づいて条件付きでジョブタスクを実行するよう設定する方法を学びます。
失敗したジョブをトラブルシューティングおよび修正する方法をご覧ください。
ジョブ実行通知を使用して、ジョブの実行が開始、完了、失敗したときに通知を受け取ることができます。
カスタムスケジュールでジョブをトリガーしたり、継続的にジョブを実行することができます。
ファイル到着トリガーを使用して、新しいデータが到着したときに Databricks ジョブを実行する方法をご覧ください。
Databricks のコンピュートリソースを使用してジョブを実行する方法をご覧ください。
Databricks ジョブを使用したワークフローの作成と管理をサポートするための Jobs API 2.0 から 2.1 への更新 について学習します。
Databricks ジョブを使用したデータワークフローの実装の詳細については、ハウツーガイドとチュートリアルを使用してください。
Delta Live Tables とは
Delta Live Tablesは、ETLとストリーミングデータ処理を簡素化するフレームワークです。Delta Live Tablesは、Auto Loader、データ変換の宣言的実装をサポートするSQLと Pythonインターフェイス、変換されたデータをDelta Lakeに書き込むサポートを内蔵しており、効率的なデータ取り込みを提供します。データに対して実行する変換を定義し、Delta Live Tablesがタスクのオーケストレーション、クラスタ管理、監視、データ品質、エラー処理を管理します。
まずは、「Delta Live Tablesとは何ですか?」を参照してください。
DatabricksジョブとDelta Live Tables
Databricks JobsとDelta Live Tablesは、エンドツーエンドのデータ処理および分析ワークフローを構築および展開するための包括的なフレームワークを提供します。
Delta Live Tables は、データのすべての取り込みと変換に使用します。 Databricks ジョブを使用して、Delta Live Tables のインジェストや変換など、Databricks プラットフォーム上の 1 つのタスクまたは複数のデータ処理および分析タスクで構成されるワークロードを調整します。
ワークフローのオーケストレーションシステムとして、Databricksジョブは以下もサポートします。
トリガーに基づいてジョブを実行する(スケジュールに従ってワークフローを実行するなど)。
SQLクエリによるデータ分析、ノートブック、スクリプト、外部ライブラリなどを使用した機械学習とデータ分析。
例えば、JARにパッケージされたApache Sparkのジョブを実行する。
Apache AirFlowを使用したワークフローオーケストレーション
Databricksでは、Databricksジョブを使用してデータワークフローをオーケストレーションすることをお勧めしますが、Apache Airflowを使用してデータワークフローを管理およびスケジュールすることもできます。Airflowを使用すると、Pythonファイルでワークフローを定義し、Airflowがワークフローのスケジュールと実行を管理します。「Apache AirflowによるDatabricksジョブのオーケストレーション」を参照してください。