Databricks ジョブでの dbt 変換の使用
dbt Core プロジェクトを Databricks ジョブのタスクとして実行できます。 dbt Core プロジェクトをジョブ タスクとして実行すると、次の Databricks Jobs 機能のメリットを享受できます。
dbt タスクを自動化し、dbt タスクを含むワークフローをスケジュールします。
dbt 変換を監視し、変換のステータスに関する通知を送信します。
dbt プロジェクトを他のタスクとともにワークフローに含めます。 たとえば、ワークフローでは、Auto Loader を使用してデータを取り込み、dbt を使用してデータを変換し、ノートブック タスクを使用してデータを分析できます。
ログ、結果、マニフェスト、構成など、ジョブ実行からの成果物を自動的にアーカイブします。
dbt Core の詳細については、 dbt ドキュメントを参照してください。
開発・本番運用ワークフロー
Databricks では、Databricks SQL ウェアハウスに対して dbt プロジェクトを開発することをお勧めします。 Databricks SQLウェアハウスを使用すると、SQL によって生成されたdbt をテストし、SQL ウェアハウスの クエリ履歴 を使用してdbt によって生成されたクエリをデバッグできます。
本番運用で 変換を実行するには、dbtDatabricks でdbt タスクを使用することをお勧めします。Databricks無事に、dbt タスクは、dbtPython Databricksコンピュートを使用して プロセスと、選択したdbt SQLSQLウェアハウスに対して で生成された を実行します。
dbt変換は、プロSQLウェアハウス、 Databricksコンピュート、またはその他のdbt対応ウェアハウスで実行できます。 この記事では、最初の 2 つのオプションについて例を挙げて説明します。
注:
ウェアハウスに対して dbtモデルを開発し、SQLDatabricks コンピュート上の本番運用で実行すると、パフォーマンスとSQL 言語サポートに微妙な違いが生じる可能性があります。DatabricksDatabricks Runtime、コンピュートとSQL ウェアハウスに同じ バージョンを使用することをお勧めします。
要件
dbt Core と
dbt-databricksパッケージを使用して開発環境で dbt プロジェクトを作成し、実行する方法の詳細については、 「dbt Core への接続」を参照してください。Databricks では、dbt-spark パッケージではなく、 dbt-databricksパッケージを推奨しています。 dbt-databricks パッケージは、Databricks 用に最適化された dbt-spark のフォークです。
Databricks ジョブで dbt プロジェクトを使用するには、 Databricks Git フォルダーの Git 統合を設定する必要があります。 DBFS から dbt プロジェクトを実行することはできません。
SQLウェアハウスを有効にする必要があります。
Databricks SQL権限が必要です。
最初の dbt ジョブを作成して実行する
次の例では、コア dbt 概念を示すサンプル プロジェクトであるjaffle_shopプロジェクトを使用します。 jaffle shop プロジェクトを実行するジョブを作成するには、次のステップを実行します。
Databricksページに移動し、次のいずれかを実行します。
クリック
 サイドバーのワークフローをクリックして
サイドバーのワークフローをクリックして 。
。サイドバーの
 [新規]をクリックし、[ジョブ]を選択します。
[新規]をクリックし、[ジョブ]を選択します。
[タスク] タブの [タスク] テキスト ボックスで、 [ジョブの名前を追加]をジョブ名に置き換えます。
[タスク名]にタスクの名前を入力します。
「タイプ」で、 dbtタスク タイプを選択します。
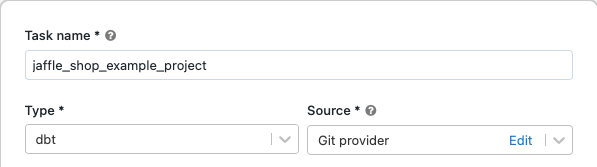
[ソース] ドロップダウン メニューで、 ワークスペース dbtを選択して、Databricks ワークスペース フォルダーにあるGit プロジェクトを使用するか、リモートGit リポジトリにあるプロジェクトの プロバイダーを 使用できます。この例では、Git リポジトリにある jaffle shop プロジェクトを使用するため、 Git プロバイダーを選択し、編集をクリックして、jaffle shop GitHub リポジトリの詳細を入力します。
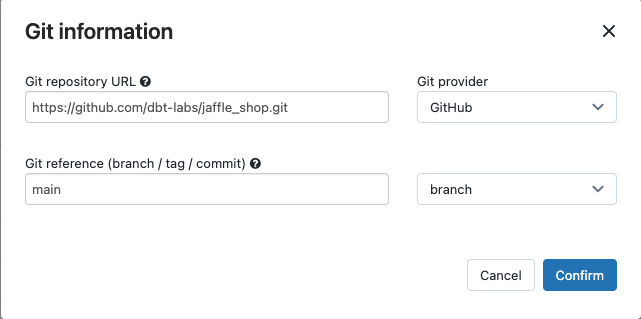
Git リポジトリ URLに、jaffle ショップ プロジェクトの URL を入力します。
Git 参照 (ブランチ / タグ / コミット)に
mainと入力します。 タグまたは SHA を使用することもできます。
[確認]をクリックします。
dbtコマンドテキストボックスで、実行するdbtコマンド( deps 、 seed 、および実行)を指定します。 すべてのコマンドの前に
dbtを付ける必要があります。 コマンドは指定された順序で実行されます。
SQLウェアハウス で、 によって生成されたSQL を実行する ウェアハウスを選択します。SQLdbtSQLウェアハウスのドロップダウン メニューには、サーバレスとプロSQLウェアハウスのみが表示されます。
(オプション) タスク出力のスキーマを指定できます。 デフォルトでは、スキーマ
defaultが使用されます。(オプション) dbt Coreを実行するコンピュート構成を変更する場合は、 dbt CLIコンピュート」をクリックします。
(オプション) タスクの dbt-databricks バージョンを指定できます。 たとえば、開発および本番運用のためにdbtタスクを特定のバージョンにピン留めするには、次のようにします。
依存ライブラリの下で、
 現在の dbt-databricks バージョンの横にあります。
現在の dbt-databricks バージョンの横にあります。[追加] をクリックします。
[依存ライブラリの追加]ダイアログで、 PyPIを選択し、 [パッケージ]テキスト ボックスに dbt パッケージのバージョンを入力します (例:
dbt-databricks==1.6.0)。[追加] をクリックします。

注:
Databricks 、開発と本番運用実行に同じバージョンが使用されるように、 dbtタスクをdbt -databricks パッケージの特定のバージョンに固定することをお勧めします。 Databricks では、dbt-databricks パッケージのバージョン 1.6.0 以上を推奨しています。
[作成]をクリックします。
今すぐジョブを実行するには、
 。
。
dbt ジョブタスクの結果を表示する
ジョブが完了したら、 ノートブックから SQL クエリを実行するか、Databricks ウェアハウスでクエリを実行して結果をテストできます。 たとえば、次のサンプル クエリを参照してください。
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
<schema>タスク構成で構成されたスキーマ名に置き換えます。
APIの例
また、ジョブ API を使用して、dbt タスクを含むジョブを作成および管理することもできます。 次の例では、単一の dbt タスクを含むジョブを作成します。
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main"
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "c2-standard-16",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": [
"dbt deps",
"dbt seed",
"dbt run"
],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
(上級)カスタムプロファイルを使用したdbtの実行
dbtSQLウェアハウス (推奨) または汎用コンピュートを使用してprofiles.yml タスクを実行するには、接続先のウェアハウスまたはDatabricks コンピュートを定義するカスタム を使用します。ウェアハウスまたは汎用コンピュートを使用して jaffle shop プロジェクトを実行するジョブを作成するには、次のステップを実行します。
注:
タスクのターゲットとして使用できるのは、 SQLウェアハウスまたは汎用コンピュートのみです。dbtジョブ コンピュートをdbtのターゲットとして使用することはできません。
jaffle_shopリポジトリのフォークを作成します。
フォークしたリポジトリをデスクトップにクローンします。 たとえば、次のようなコマンドを実行できます。
git clone https://github.com/<username>/jaffle_shop.git
<username>を GitHub ハンドルに置き換えます。次の内容で、
jaffle_shopディレクトリにprofiles.ymlという新しいファイルを作成します。jaffle_shop: target: databricks_job outputs: databricks_job: type: databricks method: http schema: "<schema>" host: "<http-host>" http_path: "<http-path>" token: "{{ env_var('DBT_ACCESS_TOKEN') }}"
<schema>をプロジェクト テーブルのスキーマ名に置き換えます。ウェアハウスを使用して dbtタスクを実行するには、SQL
<http-host>をSQL ウェアハウスの [接続の詳細] タブの サーバー ホスト名の 値に置き換えます。dbt汎用コンピュートを使用して タスクを実行するには、<http-host>を、JDBC のODBC Databricks[詳細オプション] の / タブにある サーバー ホスト名の 値に置き換えます。ウェアハウスを使用して dbtタスクを実行するには、SQL
<http-path>をSQL ウェアハウスの [接続の詳細] タブの HTTP パス の値に置き換えます。dbt汎用コンピュートを使用して タスクを実行するには、<http-path>を、JDBC のODBC Databricks[詳細オプション] の / タブの HTTP パス の値に置き換えます。
このファイルはソース管理にチェックインするため、ファイル内にアクセストークンなどのシークレットを指定しません。 代わりに、このファイルは dbt テンプレート機能を使用して、ランタイム時に資格情報を動的に挿入します。
注:
生成された資格情報は実行期間中、最大 30 日間有効で、完了後に自動的に取り消されます。
このファイルを Git にチェックインし、フォークしたリポジトリにプッシュします。 たとえば、次のようなコマンドを実行できます。
git add profiles.yml git commit -m "adding profiles.yml for my Databricks job" git push
クリック
Databricks UI のサイドバーにあるワークフロー。dbt ジョブを選択し、 [タスク]タブをクリックします。
「ソース」で、 「編集」をクリックし、フォークした jaffle shop GitHub リポジトリの詳細を入力します。
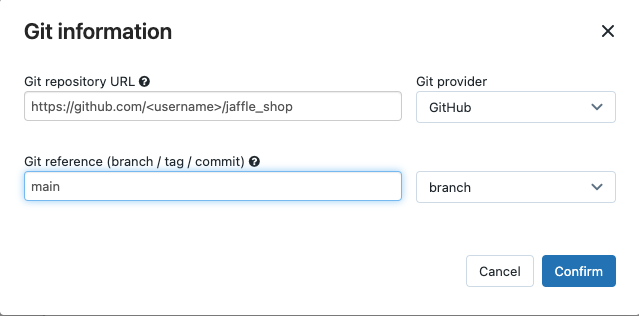
SQLウェアハウスで、 [なし (手動)]を選択します。
「プロファイル・ディレクトリ」に、
profiles.ymlファイルを含むディレクトリへの相対パスを入力します。リポジトリ ルートのデフォルトを使用するには、パス値を空白のままにします。
(上級)ワークフローで dbt Python モデルを使用する
注:
Python モデルの dbt サポートはベータ版であり、dbt 1.3 以上が必要です。
、dbt を含む特定のデータウェアハウスでPython モデル をサポートするようになりました。Databricksdbt Python モデルを使用すると、Python エコシステムのツールを使用して、SQL では実装が難しい変換を実装できます。 Databricksジョブを作成してdbt Pythonモデルで単一のタスクを実行することも、複数のタスクを含むワークフローの一部としてdbtタスクを含めることもできます。
ウェアハウスを使用して タスクで モデルを実行することはできません。PythondbtSQLdbtPythonでの モデルの使用の詳細については、Databricks ドキュメントの 「特定のデータウェアハウス」 dbtを参照してください。