レイクハウスの指針
基本原則は、アーキテクチャを定義し、影響を与えるレベル0のルールです。現在および将来のビジネスの成功に役立つデータレイクハウスを構築するには、組織内の利害関係者間の合意が不可欠です。
データをキュレートし、信頼できるデータを製品として提供
BIやML/AIにとって価値の高いデータレイクを構築するには、データのキュレーションが不可欠です。データを明確な定義、スキーマ、ライフサイクルを備えた製品のように扱ってください。セマンティックな一貫性を確保し、レイヤーごとにデータ品質を向上させることで、ビジネスユーザーがデータを完全に信頼できるようにします。
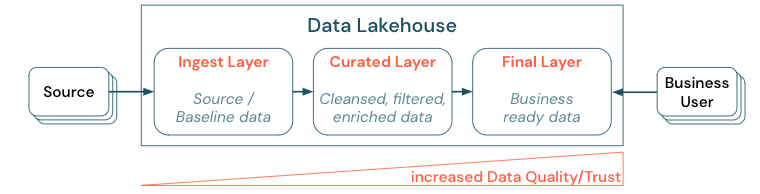
階層化(またはマルチホップ)アーキテクチャを確立してデータをキュレーションすることは、レイクハウスにとって重要なベストプラクティスです。これにより、データチームは品質レベルに従ってデータを構造化し、レイヤーごとの役割と責任を定義できるようになります。一般的なレイヤー化アプローチは次のとおりです。
取り込みレイヤー: ソース データはレイクハウスの最初のレイヤーに取り込まれ、そこで永続化される必要があります。 すべてのダウンストリームデータが取り込みレイヤーから作成されたら、必要に応じて、このレイヤーから後続のレイヤーを再構築できます。
キュレートされたレイヤー:2番目のレイヤーの目的は、クレンジング、精製、フィルタリング、集計されたデータを保持することです。このレイヤーの目標は、すべての役割と機能にわたって、分析とレポートのための健全で信頼できる基盤を提供することです。
最終レイヤー: 3番目の層は、ビジネスまたはプロジェクトのニーズに基づいて作成されます。他のビジネスユニットやプロジェクトにデータ製品として異なるビューを提供し、セキュリティニーズに応じたデータ (匿名化されたデータなど) を準備したり、パフォーマンスを最適化したり (事前に集計されたビューを使用) します。この層のデータ製品は、ビジネスにとっての真実とみなされます。
すべてのレイヤーにわたるパイプラインでは、データ品質の制約が確実に満たされるようにする必要があります。つまり、同時読み取りおよび書き込み中でも、データは常に正確で、完全で、アクセス可能で、一貫している必要があります。新しいデータの検証は、キュレーションされたレイヤーへのデータ入力時に行われ、次のETLステップによってデータの品質が向上します。データがレイヤーを通過するにつれてデータの品質は向上するはずであり、その結果、ビジネスの観点でのデータに対する信頼性が高まります。
データのサイロ化を解消し、データ移動を最小化
これらの異なるコピーに依存するビジネスプロセスを含むデータセットのコピーを作成しないでください。コピーがデータサイロになり、同期が取れなくなり、データレイクの品質が低下し、最終的には古くなったり不正確な知見になったりする可能性があります。また、外部のパートナーとデータを共有する場合は、安全な方法でデータに直接アクセスできるエンタープライズ共有メカニズムを使用します。
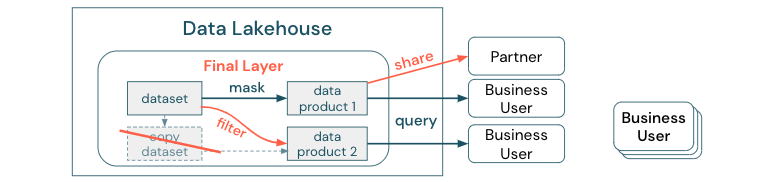
データコピーとデータサイロの区別を明確にしておけば、データのスタンドアロンコピーや使い捨てコピーは、それ自体害はありません。俊敏性、実験性、革新性を高めるために必要なこともあります。しかし、これらのコピーが下流のビジネスデータ製品に依存して動作するようになると、データサイロになります。
データサイロ化を防ぐために、データチームは通常、すべてのコピーを元のコピーと同期させるメカニズムまたはデータパイプラインの構築を試みます。 これが一貫して発生する可能性は低いため、データ品質は最終的に低下します。 これは、コストの増加やユーザーの信頼の大幅な喪失にもつながる可能性があります。 一方、いくつかのビジネスユースケースでは、パートナーやサプライヤーとのデータ共有が必要です。
重要な点は、データセットの最新バージョンを安全かつ確実に共有することです。データセットのコピーはすぐに同期が取れなくなる可能性があるため、十分ではないことがよくあります。むしろ、データはエンタープライズデータ共有ツールを介して共有する必要があります。
セルフサービスによる価値創造の民主化
ユーザーがBIや機械学習/AIタスクのためにプラットフォームやデータに簡単にアクセスできない場合、最高のデータレイクでは十分な価値を提供できません。すべての事業部門がデータやプラットフォームにアクセスする際の障壁を低減します。無駄のないデータマネジメントプロセスを検討し、プラットフォームと基礎となるデータへのセルフサービスアクセスを提供してください。
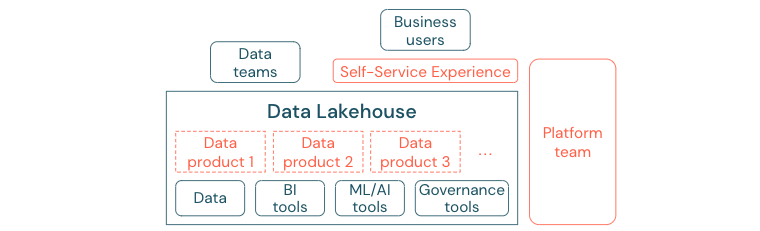
データ主導の文化への移行に成功した企業は、成功を収めるでしょう。つまり、すべての事業部門は、分析モデルから、あるいは自社または中央から提供されたデータの分析から、意思決定を行っているのです。消費者にとって、データは簡単に発見でき、安全にアクセスできなければなりません。
データ作成者にとって優れたコンセプトは、「製品としてのデータ」です。つまり、データは1つのビジネスユニットまたはビジネスパートナーによって製品のように提供および管理され、適切な権限管理のもとで他の関係者によって消費されます。中央のチームや時間がかかる可能性のあるリクエストプロセスに依存する代わりに、これらのデータ製品はセルフサービス体験の中で作成、提供、発見、消費される必要があります。
しかし、重要なのはデータだけではありません。データの民主化には、誰もがデータを作成、使用、理解できるようにする適切なツールが必要です。そのためには、データレイクハウスは、別のツールスタックを設定する手間をかけずに、データ製品を構築するためのインフラストラクチャとツールを提供する最新のデータおよびAIプラットフォームである必要があります。
組織全体のデータと AI のガバナンス戦略を採用
データはどんな組織にとっても重要な資産ですが、すべての人にすべてのデータへのアクセスを許可することはできません。データアクセスは積極的に管理する必要があります。アクセス制御、監査、リネージは、データを正しく安全に使用する上で重要です。
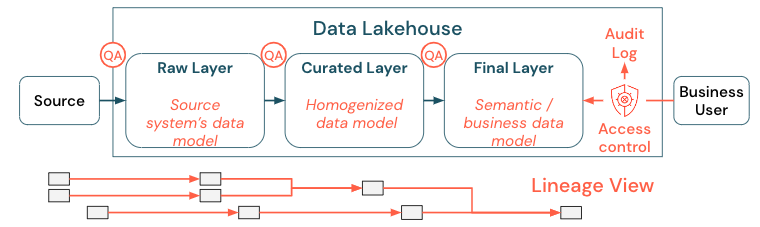
データガバナンスは幅広いテーマです。レイクハウスは、次の側面をカバーしています。
データ品質
高品質のデータは、正確で有意義なレポートや、分析結果、モデルを得るための最も重要な前提条件です。すべてのパイプラインステップで品質保証(QA)が必要です。これを実装する方法の例としては、データ契約の締結や、SLAの遵守、スキーマの安定性の維持、制御された方法でのスキーマの進化などがあります。
データカタログ
もう1つの重要な側面はデータ発掘です。すべてのビジネス領域のユーザー、特にセルフサービスモデルのユーザーは、関連するデータを簡単に探索できなければなりません。したがって、レイクハウスには、すべてのビジネス関連データをカバーするデータカタログが必要です。データカタログの主な目的は次のとおりです。
同じビジネスコンセプトがビジネス全体で統一的に呼び出され、宣言されるようにする。これは、キュレーションされた最終レイヤーのセマンティックモデルと考えることができます。
データリネージを正確に追跡して、これらのデータがどのようにして現在の形や形になったのかをユーザーが説明できるようにする。
データを適切に使用するためにはデータそのものと同じくらい重要な高品質のメタデータを維持する。
アクセス制御
レイクハウス内のデータからの価値創造はすべての事業分野で行われるため、レイクハウスはセキュリティを最優先事項として構築されなければなりません。企業はよりオープンなデータアクセスポリシーを採用しているかもしれませんし、最低権限の原則に厳密に従うかもしれません。それとは別に、すべてのレイヤーでデータアクセス制御を実施する必要があります。最初から、きめ細かな権限スキーム(列レベルと行レベルのアクセス制御、役割ベースまたは属性ベースのアクセス制御)を実装することが重要です。企業は比較的緩やかなルールから始めることができます。しかし、レイクハウスプラットフォームが成長するにつれて、より高度なセキュリティ体制のためのすべてのメカニズムとプロセスが整っていきます。さらに、レイクハウス内のデータへのすべてのアクセスは、最初から監査ログで管理する必要があります。
オープンなインターフェースとオープンフォーマットの奨励
オープンインターフェースとデータ形式は、レイクハウスと他のツールとの間の相互運用性にとって非常に重要です。既存のシステムとの統合が簡素化され、ツールをプラットフォームに統合したパートナーのエコシステムも開かれます。
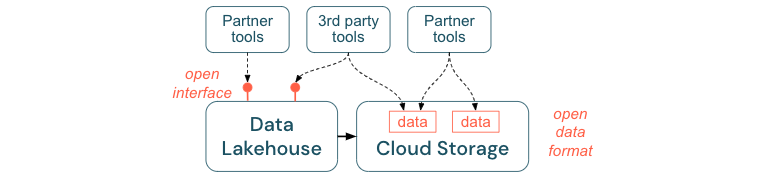
オープンインターフェースは、相互運用性を実現し、単一ベンダーへの依存を防ぐために不可欠です。従来、ベンダーは独自のテクノロジーとクローズドインターフェースを構築しており、企業がデータを保存、処理、共有する方法が制限されていました。
オープンインターフェースを基盤として構築することで、将来に向けた構築が可能になります。
データの寿命と移植性が向上するため、より多くのアプリケーションやユースケースでデータを使用できるようになります。
これにより、オープンインターフェースを迅速に活用してツールをレイクハウスプラットフォームに統合できるパートナーのエコシステムが開かれます。
最後に、データのオープンフォーマットを標準化することで、総コストは大幅に削減されます。独自のプラットフォームを経由して高いエグレスコストや計算コストをかける必要がなく、クラウドストレージ上で直接データにアクセスできるようになります。
パフォーマンスとコストに合わせて拡張および最適化する構築
データは必然的に増加し続け、より複雑になります。組織が将来のニーズに対応できるよう、レイクハウスは拡張可能である必要があります。例えば、新しいリソースをオンデマンドで簡単に追加できるようにする必要があります。コストは実際の消費量に制限する必要があります。
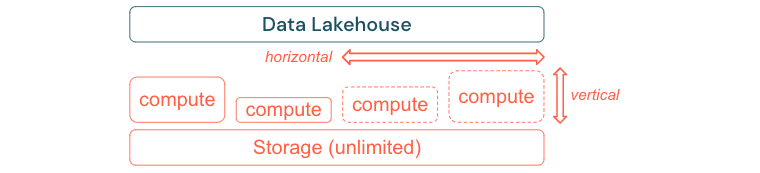
標準的なETLプロセス、ビジネスレポート、およびダッシュボードは、メモリと計算の観点から予測可能なリソース需要を持つことが多いです。しかし、新しいプロジェクトや季節的なタスク、あるいはモデルのトレーニング(解約、予測、メンテナンス)のような最新のアプローチでは、リソース需要がピークに達します。企業がこれらすべてのワークロードを実行できるようにするには、メモリとコンピュートのためのスケーラブルなプラットフォームが必要です。新しいリソースは必要に応じて容易に追加できなければならず、発生することストは実際の消費に対してのみ出なければなりません。ピークが過ぎれば、リソースは再び解放され、それに応じてコストも削減できます。しばしば、これは水平スケーリング(ノードの増減)と垂直スケーリング(ノードの大小)と呼ばれます。
スケーリングにより、企業はより多くのリソースを持つノードや、より多くのノードを持つクラスターを選択することで、クエリのパフォーマンスを向上させることもできます。しかし、大規模なマシンやクラスターを恒久的に提供するのではなく、必要な時間だけオンデマンドでプロビジョニングすることで、全体のパフォーマンスとコストの比率を最適化することができます。最適化のもう一つの側面は、ストレージとコンピュートリソースの比較です。データ量とそのデータを使用するワークロード(例えば、データの一部だけを使用したり、小さなデータで集中的な計算を行ったりする場合)の間には明確な関係がないため、ストレージとコンピュートリソースを切り離したインフラストラクチャプラットフォームを選択することをお勧めします。