レイクハウスのリファレンスアーキテクチャ (ダウンロード)
この記事では、データソース、インジェスト、変換、クエリと処理、サービング、分析、ストレージに関するレイクハウスのアーキテクチャ ガイダンスについて説明します。
各リファレンスアーキテクチャは、11 x 17(A3)フォーマットのPDFをダウンロードできます。
Databricks のレイクハウスは、 パートナー ツールの大規模なエコシステムと統合されるオープン プラットフォームですが、リファレンス アーキテクチャは Google Cloud サービスと Databricks レイクハウスのみに焦点を当てています。 示されているクラウド プロバイダー サービスは、概念を説明するために選択されており、すべてを網羅しているわけではありません。
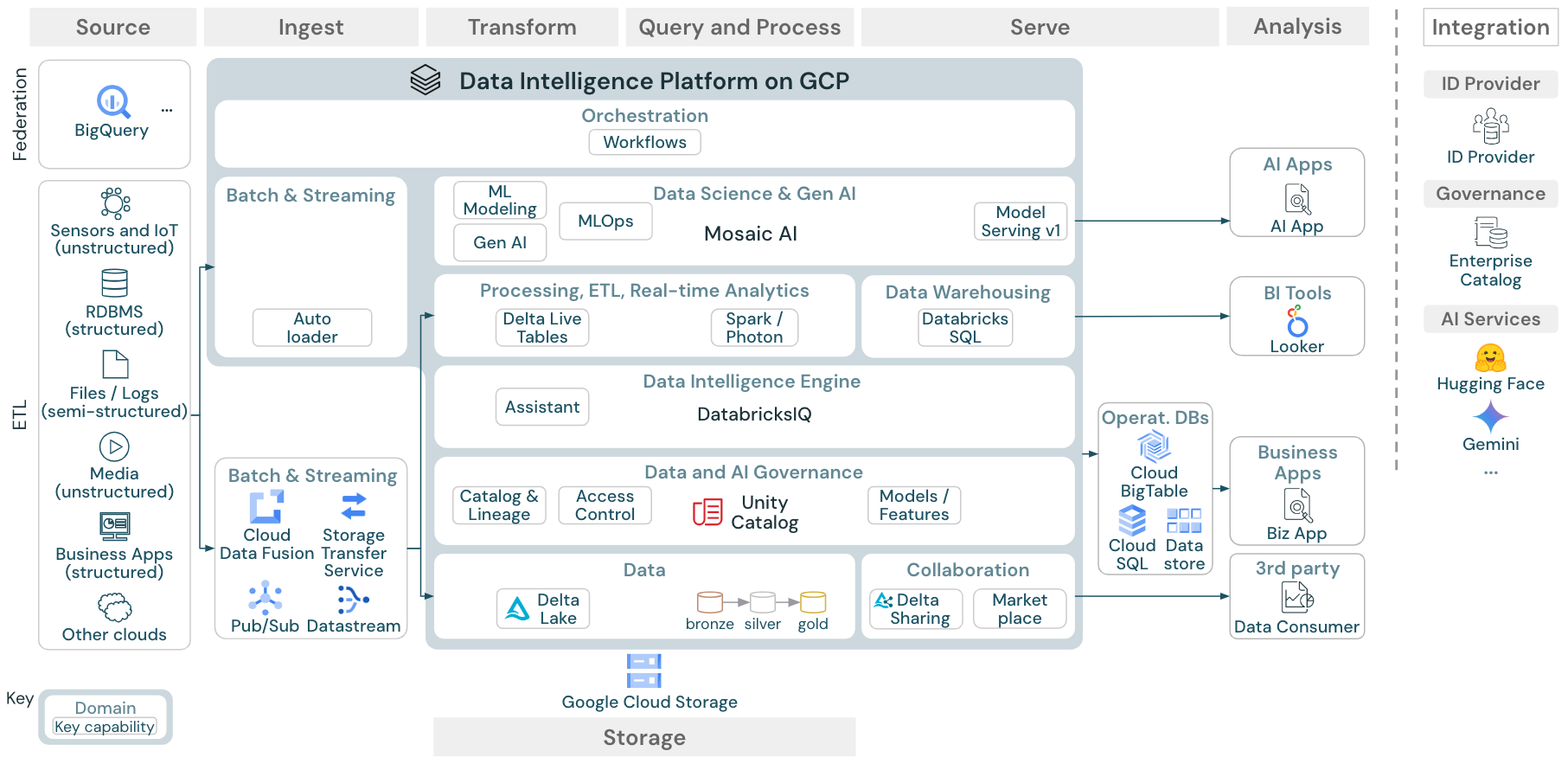
ダウンロード: Google Cloud 上の Databricks レイクハウスのリファレンス アーキテクチャ
GCP リファレンス アーキテクチャには、取り込み、保存、配信、分析のための次の GCP 固有のサービスが示されています。
レイクハウスフェデレーションのソースシステムとしてのBigQuery
ストリーミング取り込み用のPub/Subとデータストリーム
バッチ取り込み用のCクラウドフュージョンとストレージ転送サービス
オブジェクトストレージとしてのクラウドストレージ
運用データベースとしてのCloud Big Table、Cloud SQL、Data Store
BIツールとしてのLooker
リファレンスアーキテクチャの構成
参照アーキテクチャは、 ソース、 インジェスト、 変換、 クエリ/プロセス、 サーブ、 分析、 ストレージのスイムレーンに沿って構成されています。
ソース
このアーキテクチャでは、半構造化データ、非構造化データ(センサーとIoT、メディア、ファイル/ログ)と構造化データ(RDBMS、ビジネスアプリケーション)を区別します。SQLソース(RDBMS)は、レイクハウスフェデレーションによってETLなしでレイクハウスとUnity Catalogに統合することもできます。さらに、他のクラウドプロバイダーからデータがロードされる場合もあります。
インジェスト
データはバッチまたはストリーミング経由でレイクハウスに取り込むことができます。
クラウドストレージに配信されたファイルは、Databricks Auto Loaderを使用して直接読み込むことができます。
エンタープライズアプリケーションから Delta Lakeへのデータのバッチインジェストの場合、 Databricksレイクハウスは、これらの記録システムに特化したアダプターを備えた パートナーインジェストツールに依存しています。
ストリーミングイベントは、Databricks構造化ストリーミングを使用して、Kafkaなどのイベントストリーミングシステムから直接取り込むことができます。ストリーミングソースは、センサー、IoT、またはチェンジデータキャプチャプロセスです。
ストレージ
データは通常クラウドストレージシステムに保存され、ETLパイプラインはメダリオンアーキテクチャを使用して、データをデルタファイル/テーブルとしてキュレーションされた方法で保存します。
変換 と クエリ/プロセス
Databricksレイクハウスは、すべての変換とクエリに Apache SparkとPhotonのエンジンを使用します。
DLT(Delta Live Tables)は、信頼性、保守性、テスト性に優れたデータ処理パイプラインを簡素化および最適化するための宣言型フレームワークです。
Apache SparkとPhotonを搭載したDatabricksデータインテリジェンスプラットフォームは、SQLウェアハウス経由のSQLクエリと、ワークスペースクラスタリング経由のSQL、Python、Scalaワークロードという両方のタイプのワークロードをサポートします。
データサイエンス (ML モデリング) の場合、DatabricksAI および機械学習プラットフォームは、 MLAutoMLとML ジョブのコーディングに特化した ランタイムを提供します。すべてのデータサイエンスとMLOpsワークフローは、 MLflowによって最適にサポートされます。
サービング
DWH と BI のユースケースでは、Databricks レイクハウスは、Databricks SQL と、SQL ウェアハウスを利用したデータウェアハウス、そしてサーバーレス SQL ウェアハウスを提供します。
機械学習の場合、 モデルサービング は、Databricks コントロールプレーンでホストされるスケーラブルでリアルタイムのエンタープライズグレードのモデルサービング機能です。 Mosaic AI Gateway はDatabricksモデルとそれに関連するモデルサービング エンドポイントAIアクセスを管理および監視するためのソリューションです。
運用データベース:運用データベースなどの外部システムを使用して、最終データ製品を保存してユーザーアプリケーションに提供できます。
コラボレーション:ビジネスパートナーは、Delta Sharingを通じて必要なデータに安全にアクセスできます。Delta Sharingを基盤とするDatabricks Marketplaceは、データ製品を交換するためのオープンフォーラムです。
分析
最終的なビジネスアプリケーションはこのスイムレーンにあります。例えば、レイクハウスから運用データベースにプッシュされたデータにアクセスするカスタムクライアントなどがあります。
BIのユースケースでは、アナリストは通常、BIツールを使用してデータウェアハウスにアクセスします。SQL開発者は、クエリやダッシュボード作成にDatabricks SQLエディタ(図には示されていません)を使用することもできます。
また、データインテリジェンスプラットフォームは、データを視覚化して知見を共有するためのダッシュボードも提供します。
統合
Databricks プラットフォームは、 ユーザー管理 と シングルサインオン (SSO) のための標準 ID プロバイダーと統合されています。
OpenAI、LangChain、HuggingFace などの外部 AI サービスは、Databricks Intelligence Platform 内から直接使用できます。
外部オーケストレーターは、包括的な REST API を使用するか、 Apache Airflow などの外部オーケストレーション ツールへの専用コネクタを使用できます。
Unity CatalogAIは、Databricks Intelligence Platformのすべてのデータおよび ガバナンスに使用され、 レイクハウスフェデレーション を通じて他のデータベースをガバナンスに統合できます。
さらに、Unity Catalog は他のエンタープライズ カタログに統合できます。 詳細については、エンタープライズ カタログ ベンダーにお問い合わせください。
すべてのワークロードに共通の機能
さらに、Databricksレイクハウスには、すべてのワークロードをサポートする管理機能が付属しています。
データとAIのガバナンス
Databricks Data Intelligence Platformの中心となるデータおよびAIガバナンスシステムがUnity Catalogです。Unity Catalogは、すべてのワークスペースに適用されるデータアクセスポリシーを管理する単一の場所を提供し、テーブル、ボリューム、フィーチャー(Feature Store)、モデル(モデルレジストリ)など、レイクハウスで作成または使用されるすべてのアセットをサポートします。Unity Catalogは、Databricks上で実行されたクエリ間のランタイムデータリネージをキャプチャするためにも使用できます。
オブザーバビリティを確保するためのシステムテーブルは、Databricks がホストするアカウントの運用データの分析ストアです。システムテーブルは、アカウント全体の履歴の確認に使用できます。
データインテリジェンスエンジン
Databricks Data Intelligence Platformは、組織全体でデータとAIを活用することを可能にします。DatabricksIQを搭載し、生成AIとレイクハウスの統合の利点を組み合わせて、データのユニークなセマンティクスを理解します。
Databricks Assistantは、開発者向けのコンテキスト認識AIアシスタントとして、Databricksノートブック、SQLエディター、およびファイルエディターで利用できます。
オートメーション&オーケストレーション
Databricks ジョブは、Databricks Data Intelligence Platform でデータ処理、機械学習、アナリティクス パイプラインを調整します。Delta Live Tables を使用すると、宣言型構文を使用して、信頼性と保守性に優れた ETL パイプラインを構築できます。 このプラットフォームは、CI/CD と MLOps もサポートしています
Google Cloud 上の Data Intelligence Platform のユースケースの概要
Databricks LakeFlow Connect には、エンタープライズ アプリケーションやデータベースから取り込むための組み込みコネクタが用意されています。 結果として得られるインジェスト パイプラインは Unity Catalog によって制御され、サーバレス コンピュートと Delta Live Tablesによって駆動されます。 LakeFlow Connect は、効率的な増分読み取りと書き込みを活用して、データ取り込みをより速く、スケーラブルで、コスト効率を高めながら、データを最新のままダウンストリームで消費できるようにします。
ユースケース:バッチETL
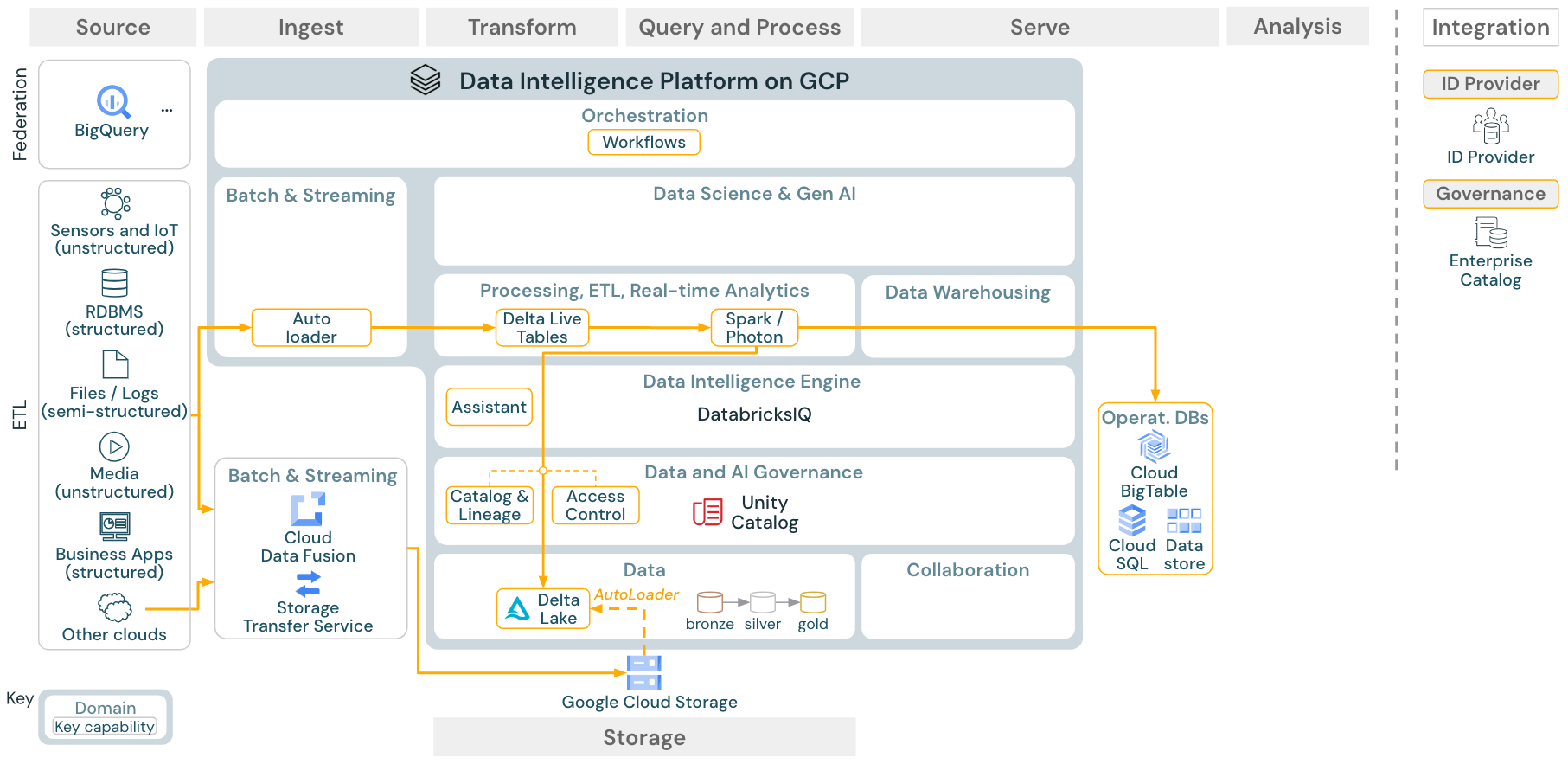
ダウンロード:Databricks on Google CloudのバッチETLリファレンスアーキテクチャ
インジェスト ツールは、ソース固有のアダプターを使用してソースからデータを読み取り、 Auto Loaderが読み取ることができるクラウド上のストレージに保存するか、 Databricksを直接呼び出します (たとえば、 Databricksレイクハウスに統合されたパートナー インジェスト ツールを使用します)。 データをロードするために、Databricks ETL および処理エンジンは DLT を介してクエリを実行します。 シングルタスクまたはマルチタスクのワークフローは、 Databricksジョブによって調整され、 Unity Catalog (アクセス制御、監査、リネージなど) によって管理できます。 低レイテンシの運用システムが特定のゴールデン テーブルにアクセスする必要がある場合は、ETL パイプラインの最後にある RDBMS やキー値ストアなどの運用データベースにエクスポートできます。
ユースケース:ストリーミングと変更データキャプチャ(CDC)
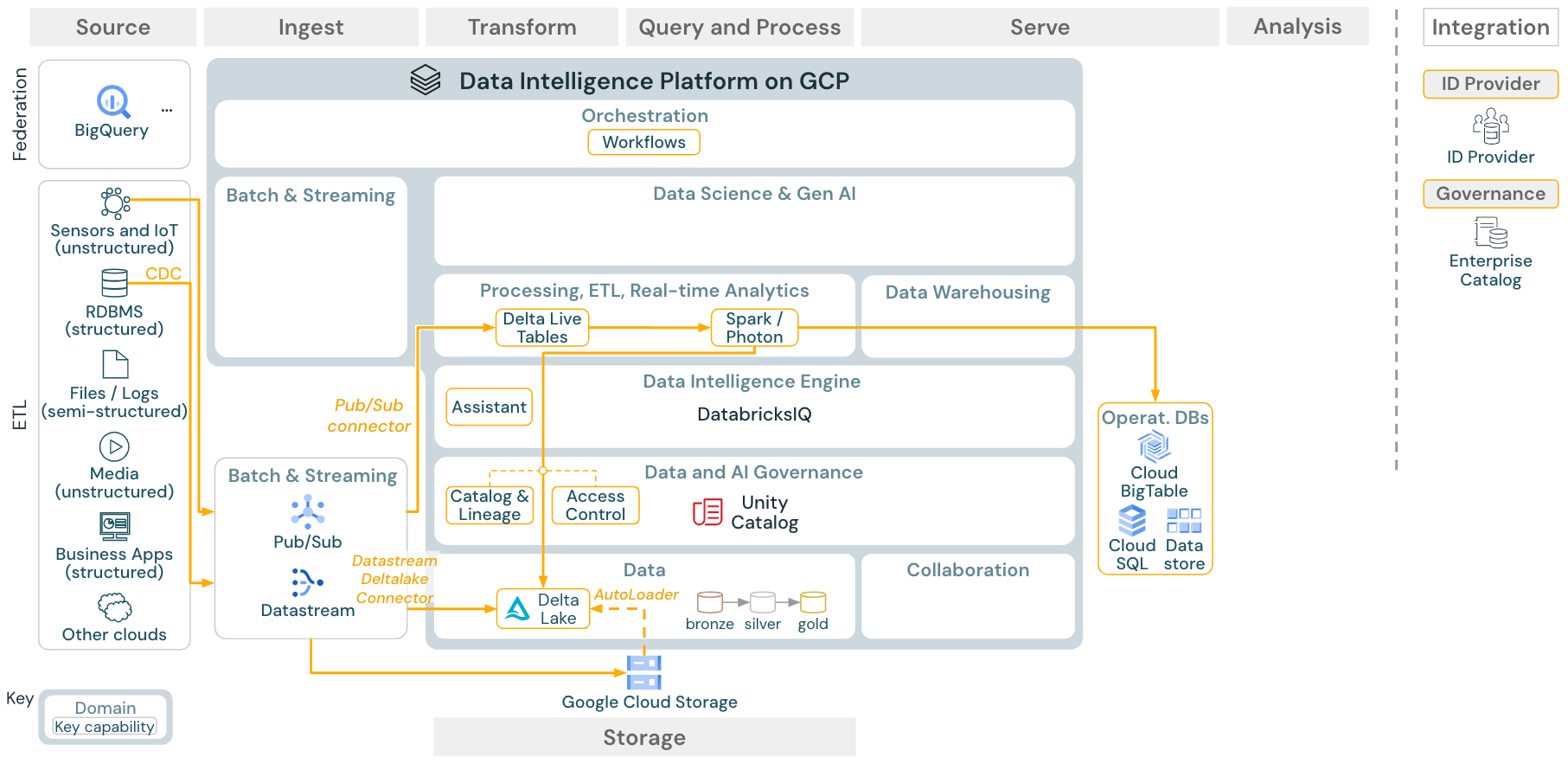
ダウンロード:Databricks on Google CloudのSpark構造化ストリーミングアーキテクチャ
Databricks ETLエンジンは、Spark構造化ストリーミングを使用して、Apache KafkaやPub/Subなどのイベントキューから読み取ります。下流のステップは、上記のバッチのユースケースのアプローチに従います。
リアルタイム変更データキャプチャ(CDC)は通常、イベントキューを使用して抽出されたイベントを保存します。そこから、ユースケースはストリーミングのユースケースに従います。
CDCがバッチで実行され、ずクラウドストレージに保存される場合、Databricks Autoloaderはそれらを読み込むことができ、ユースケースはバッチETLに従います。
ユースケース:機械学習とAI
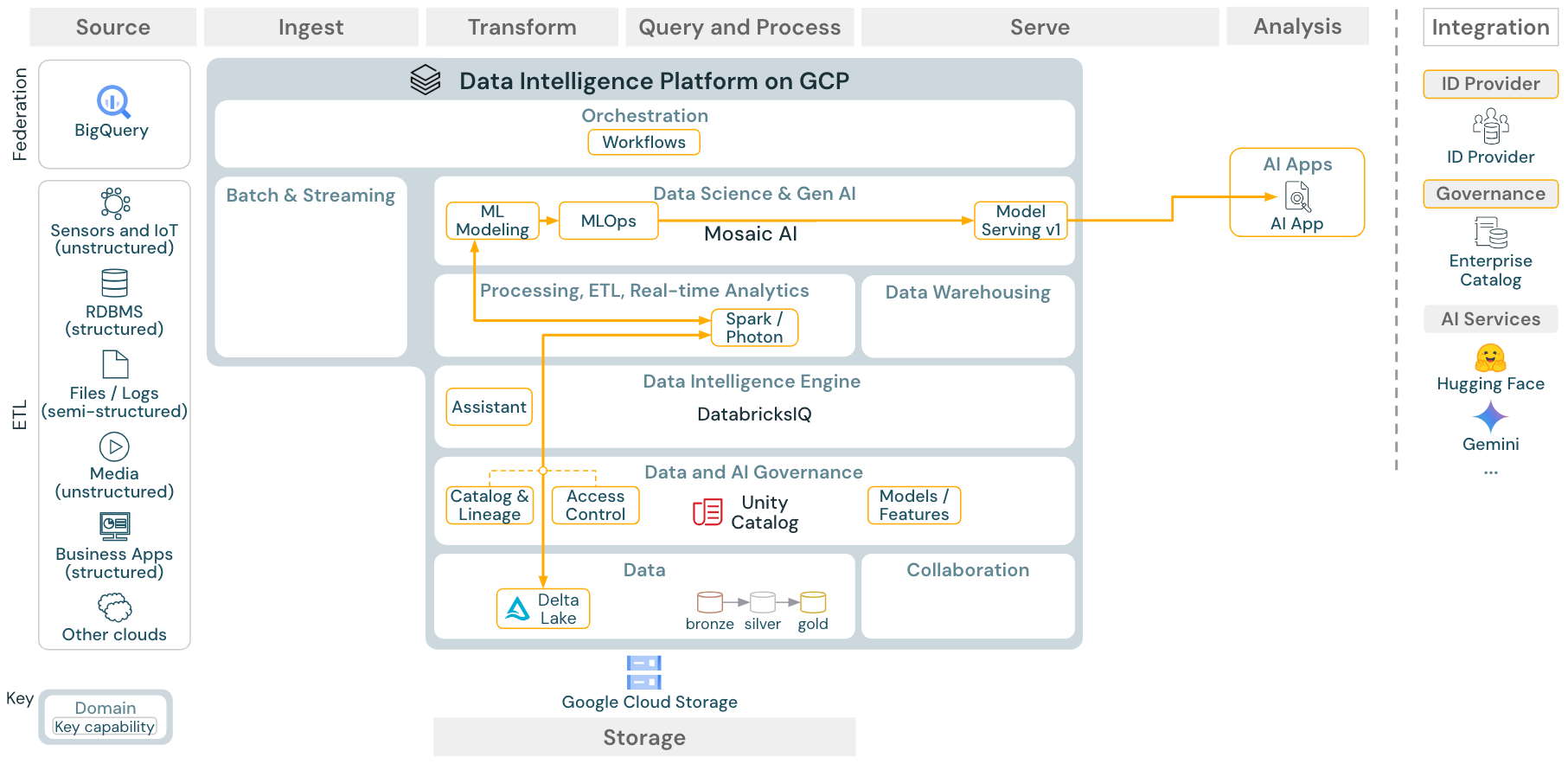
ダウンロード:Databricks on Google Cloudの機械学習およびAIリファレンスアーキテクチャ
機械学習のために、Databricks Data Intelligence Platformは、最先端の機械学習とディープラーニングのライブラリを備えたMosaic AIを提供します。これは、Feature Storeやモデルレジストリ(いずれもUnity Catalogに統合)、AutoMLによるローコード機能、データサイエンスライフサイクルへのMLflow統合などの機能を提供します。
すべてのデータサイエンス関連の資産 (テーブル、機能、モデル) はUnity Catalogによって管理され、 data scientists Databricksジョブを使用してジョブを調整できます。
スケーラブルでエンタープライズグレードの方法でモデルをデプロイするには、MLOps機能を使用してモデルサービングでモデルを公開します。
ユースケース:BIとSQL分析
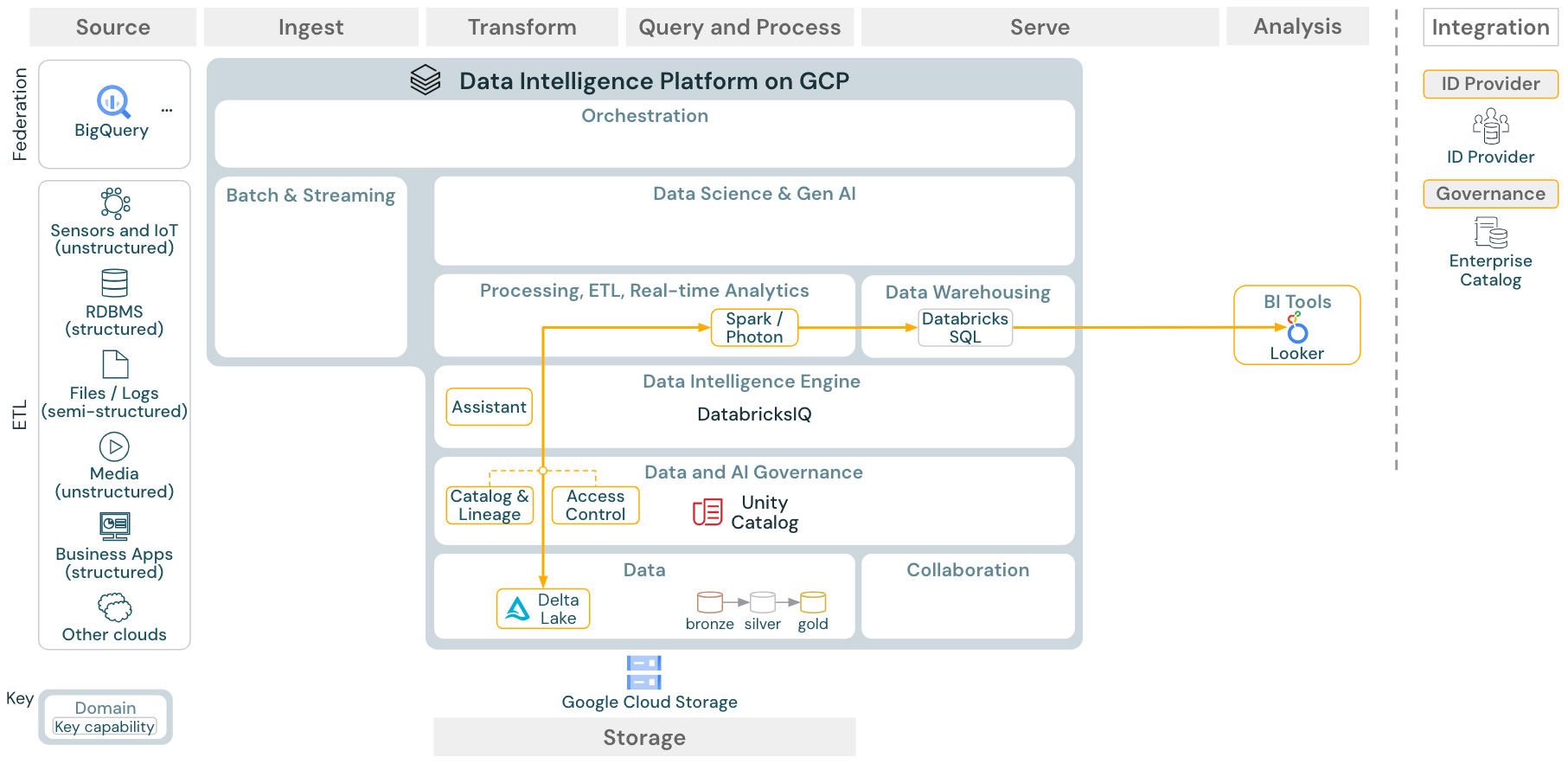
ダウンロード:Databricks on Google CloudのBIおよびSQLアナリティクスのリファレンスアーキテクチャ
BIのユースケースでは、ビジネスアナリストはDatabricks SQLエディターか、TableauやLookerなどの特定のBIツールを使用できます。どちらの場合も、エンジンはDatabricks SQL(サーバレスまたは非サーバレス)であり、データディスカバリー、探索、アクセス制御はUnity Catalogによって提供されます。
ユースケース:レイクハウスフェデレーション
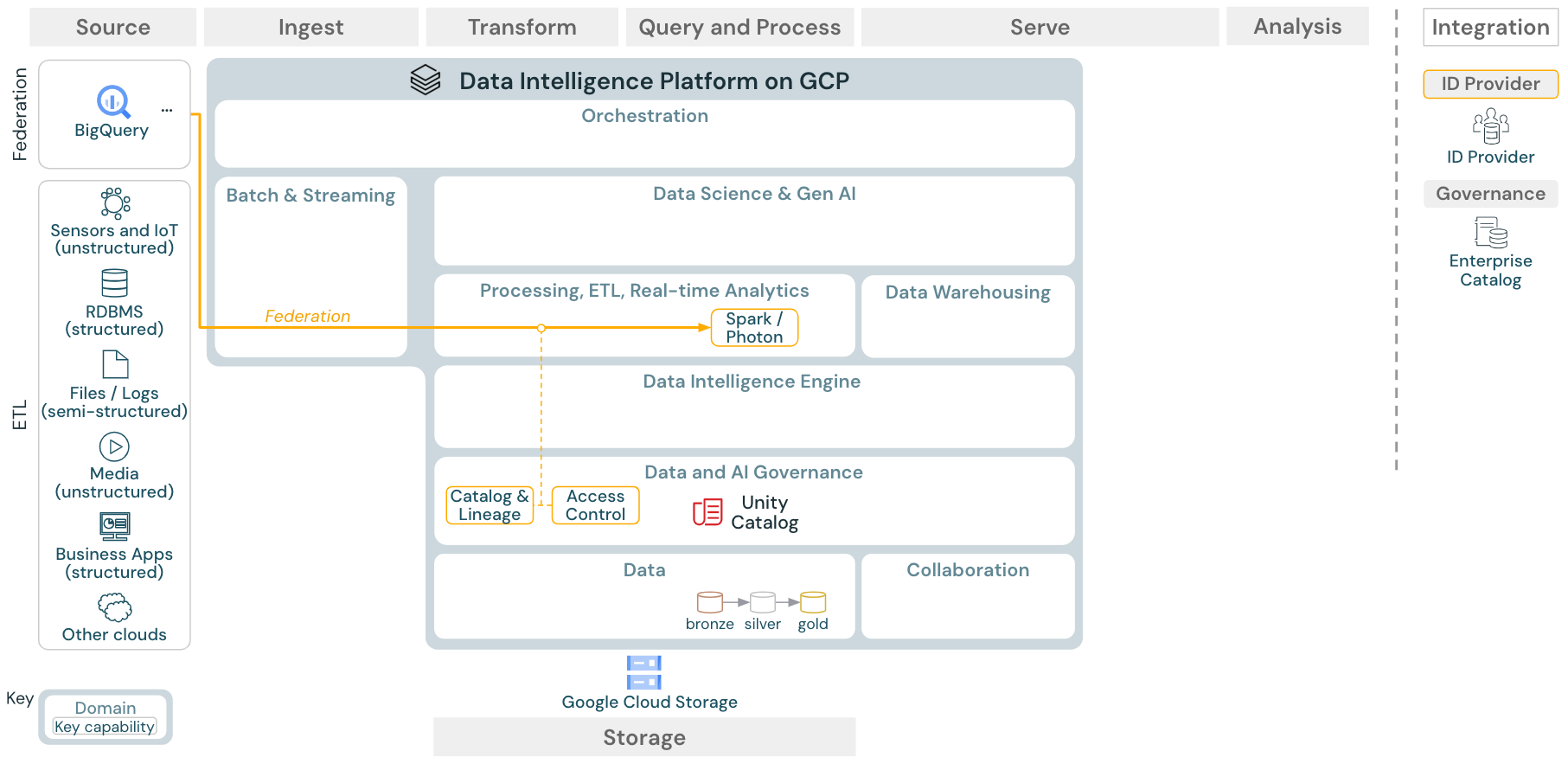
ダウンロード: Databricks on Google Cloudのレイクハウスフェデレーションリファレンスアーキテクチャ
レイクハウスフェデレーションでは、外部のデータSQLデータベース(MySQLやPostgresなど)をDatabricksと統合できます。
最初にデータをオブジェクトストレージにETLする必要がなく、すべてのワークロード (AI、DWH、BI) がこのメリットを享受できます。外部ソースカタログはUnity Catalogにマッピングされ、Databricksプラットフォーム経由のアクセスにきめ細かいアクセス制御を適用できます。
ユースケース:エンタープライズデータ共有
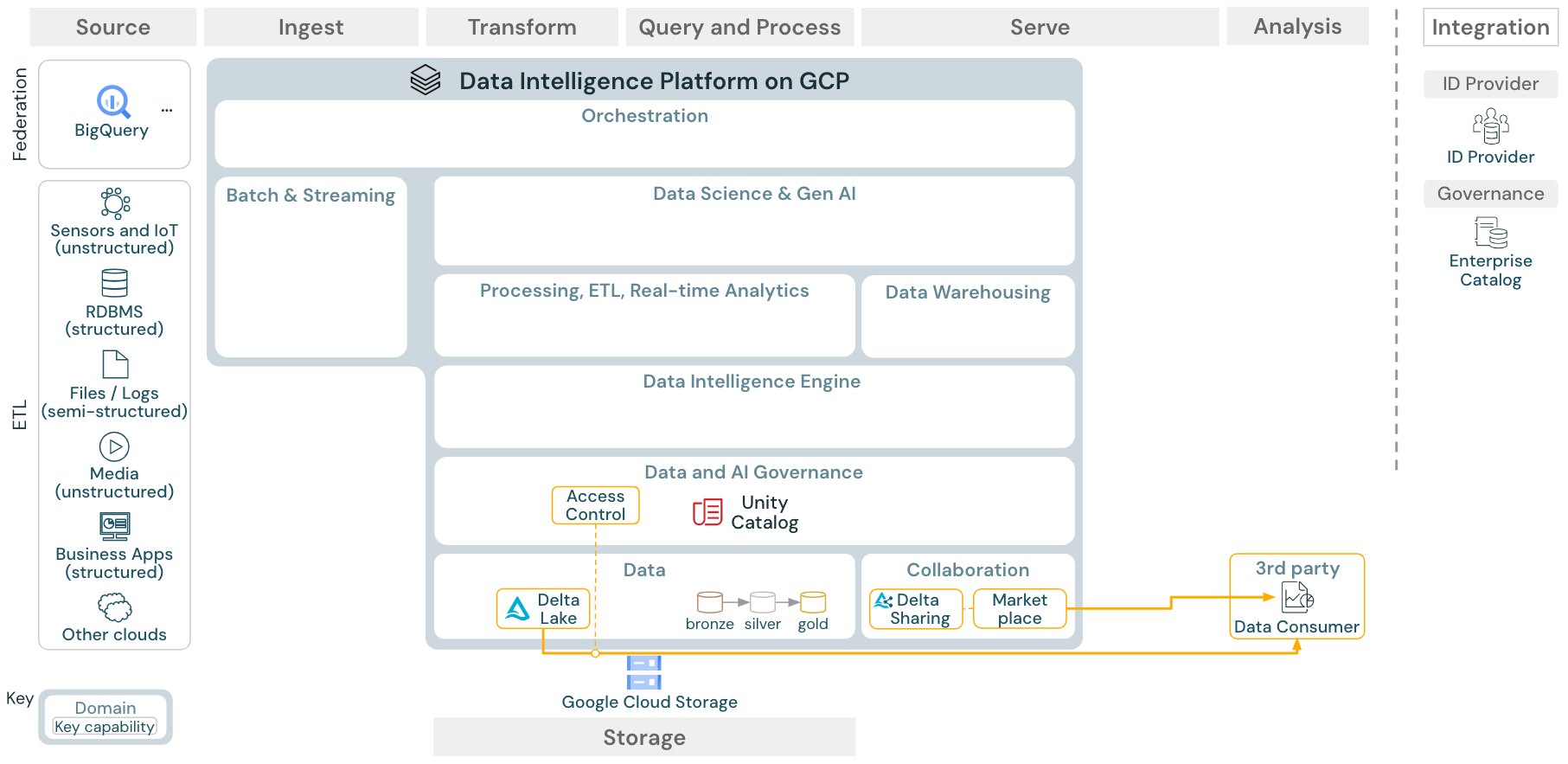
ダウンロード:Databricks on Google Cloudのエンタープライズデータ共有リファレンスアーキテクチャ
エンタープライズグレードのデータ共有は、Delta Sharingによって提供されます。Unity Catalogで保護されたオブジェクトストア内のデータに直接アクセスでき、Databricks Marketplaceはデータ製品を交換するためのオープンフォーラムです。