Arquiteturas de referência da Lakehouse (download)
Este artigo aborda a orientação arquitetônica para o site lakehouse em termos de fonte de dados, ingestão, transformações, consulta e processamento, fornecimento, análise e armazenamento.
Cada arquitetura de referência tem um PDF para download em formato 11 x 17 (A3).
Enquanto o lakehouse em Databricks é uma plataforma aberta que se integra a um grande ecossistema de ferramentas de parceiros, as arquiteturas de referência se concentram apenas no serviço Google Cloud e no Databricks lakehouse. Os serviços de provedores de nuvem mostrados são selecionados para ilustrar os conceitos e não são exaustivos.
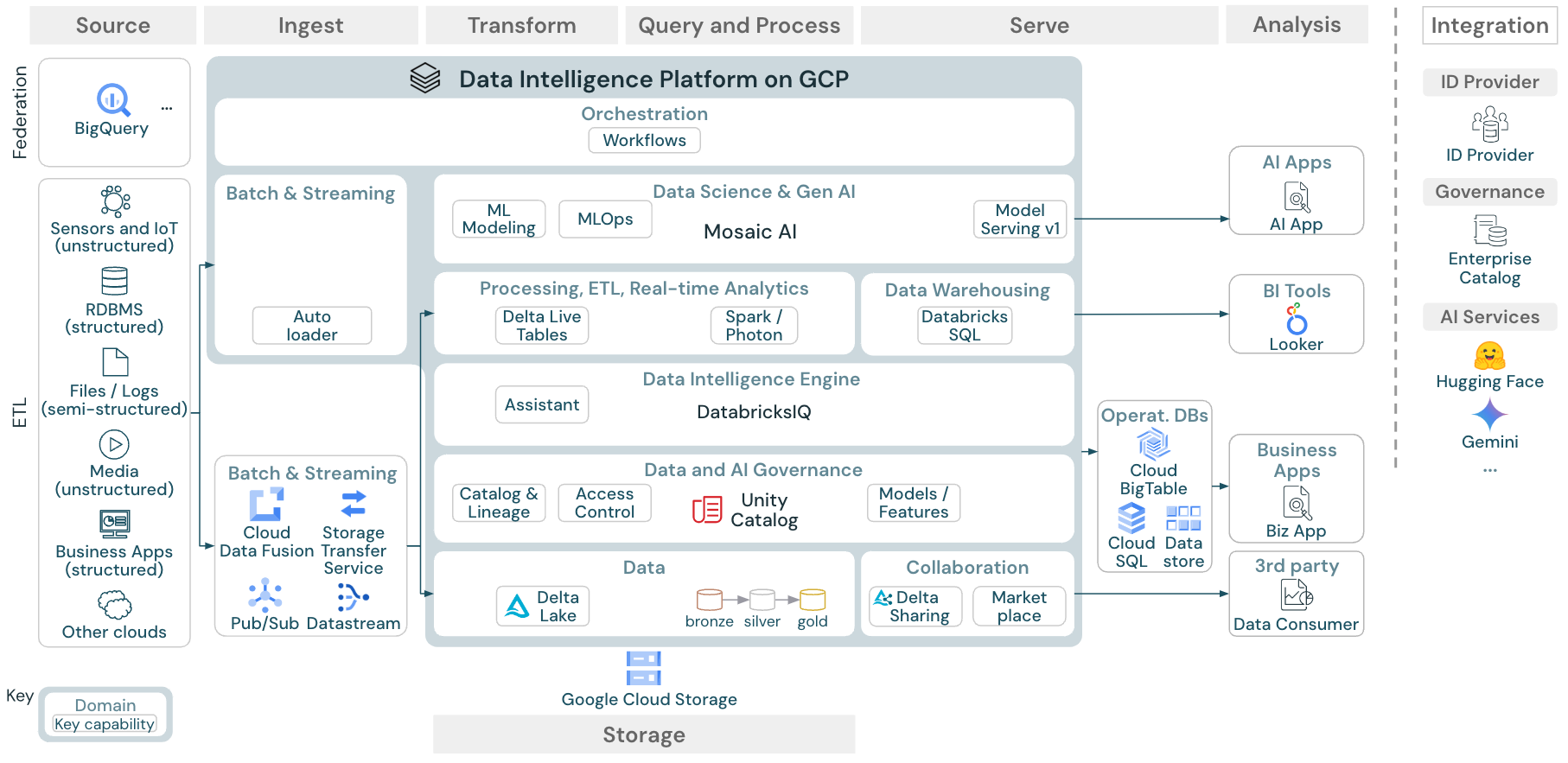
download: Arquitetura de referência para o site Databricks lakehouse no Google Cloud
A arquitetura de referência do GCP mostra os seguintes serviços específicos do GCPpara ingestão, armazenamento, fornecimento e análise:
BigQuery como sistema de origem para Lakehouse Federation
Pub/Sub e Datastream para ingestão de streaming
Cloud Fusion e serviço de transferência de armazenamento para ingestão em lote
Cloud Storage como armazenamento de objetos
Cloud Big Table, Cloud SQL e Data Store como bancos de dados operacionais
O Looker como ferramenta de BI
Organização das arquiteturas de referência
A arquitetura de referência é estruturada de acordo com as raias de natação Source, Ingest, Transform, Query/Process, Serve, análise e Storage:
Origem
A arquitetura faz distinção entre dados semiestruturados e não estruturados (sensores e IoT, mídia, arquivos/logs) e dados estruturados (RDBMS, aplicativos de negócios). As fontes SQL (RDBMS) também podem ser integradas ao lakehouse e ao Unity Catalog sem ETL por meio da federação lakehouse. Além disso, os dados podem ser carregados de outros provedores de nuvem.
Ingerir
Os dados podem ser ingeridos no lakehouse por meio de lote ou transmissão:
Os arquivos entregues ao armazenamento em nuvem podem ser carregados diretamente com o Databricks Auto Loader.
Para a ingestão em lote de dados de aplicativos corporativos em Delta Lake, a Databricks lakehouse conta com ferramentas de ingestão de parceiros com adaptadores específicos para esses sistemas de registro.
Os eventos de streaming podem ser ingeridos diretamente de sistemas de streaming de eventos, como o Kafka, com o Databricks Structured Streaming. As fontes de streaming podem ser sensores, IoT ou processos de captura de dados de alterações.
Armazenamento
Normalmente, os dados são armazenados no sistema de armazenamento em nuvem, onde os pipelines de ETL utilizam a arquitetura medallion para armazenar dados de forma selecionada como arquivos/tabelas Delta.
Transformação e consulta//processo
O lakehouse Databricks utiliza seus sistemas Apache Spark e Photon para todas as transformations e queries.
O DLT (Delta Live Tables) é uma estrutura declarativa para simplificar e otimizar o pipeline de processamento de dados confiável, sustentável e testável.
Com a tecnologia Apache Spark e Photon, a plataforma de inteligência de dados Databricks aceita ambos os tipos de cargas de trabalho: consultas SQL por meio de SQL warehouses e cargas de trabalho SQL, Python e Scala por meio de clusters de workspace.
Para a ciência de dados (ML Modeling), a plataforma Databricks IA e Machine Learning fornece tempos de execução especializados ML para AutoML e para codificação ML Job. Toda a ciência de dados e o MLOps fluxo de trabalho têm o melhor suporte do MLflow.
Disponibilizando
Para casos de uso de DWH e BI, o Databricks lakehouse oferece o Databricks SQL, o data warehouse com tecnologia de SQL warehouses, e serverless SQL warehouses.
Para o aprendizado de máquina, o servindo modelo é um recurso de servindo modelo dimensionável, tempo real e de nível empresarial hospedado no plano de controle Databricks. Mosaic AI Gateway é Databricks soluções para governar e monitorar o acesso a modelos AI e seu endpoint de modelo de serviço associado.
Bancos de dados operacionais: sistemas externos, como bancos de dados operacionais, podem ser utilizados para armazenar e entregar produtos de dados finais aos aplicativos do usuário.
Colaboração: os parceiros de negócios recebem acesso seguro aos dados de que precisam por meio do Delta Sharing. Com base no Delta Sharing, o Databricks Marketplace é um fórum aberto para troca de produtos de dados.
Análise
As aplicações de negócios finais estão nesta via. Os exemplos são clientes personalizados que acessam dados enviados do lakehouse para um banco de dados operacional.
Para casos de uso de BI, os analistas geralmente utilizam ferramentas de BI para acessar o data warehouse. Os desenvolvedores de SQL também podem utilizar o Databricks SQL Editor (não mostrado no diagrama) para consultas e painéis.
A plataforma de inteligência de dados também oferece painéis para criar visualizações de dados e compartilhar entendimentos.
Integrar
A plataforma Databricks integra-se aos provedores de identidade padrão para gerenciamento de usuários e logon único (SSO).
Serviços externos AI como o OpenAI, LangChain ou HuggingFace podem ser usados diretamente na Databricks Intelligence Platform.
Os orquestradores externos podem usar a API REST abrangente ou conectores dedicados a ferramentas de orquestração externas, como o Apache Airflow.
Unity Catalog é usado para toda a governança de dados e AI na Databricks Intelligence Platform e pode integrar outros bancos de dados à sua governança por meio da Lakehouse Federation.
Além disso, o Unity Catalog pode ser integrado a outros catálogos empresariais. Entre em contato com o fornecedor do catálogo corporativo para obter detalhes.
Recursos comuns para todas as cargas de trabalho
Além disso, o Databricks lakehouse vem com recursos de gerenciamento compatíveis com todas as cargas de trabalho:
Governança de dados e IA
O sistema central de governança de dados e IA na Plataforma de Inteligência de Dados Databricks é o Unity Catalog. O Unity Catalog apresenta um local único para gerenciar políticas de acesso a dados que se aplicam a todos os espaços de trabalho e suporta todos os ativos criados ou utilizados na lakehouse, como tabelas, volumes, recursos (armazenamento de recursos ) e modelos (registro de modelos). O Unity Catalog também pode ser usado para capturar a linhagem de dados em tempo de execução em consultas executadas no Databricks.
Para fins de observabilidade, as tabelas do sistema são um armazenamento analítico hospedado pelo Databricks dos dados operacionais da sua conta. As tabelas do sistema podem ser usadas para observabilidade histórica em sua conta.
Mecanismo de inteligência de dados
A Databricks Data Intelligence Platform possibilita que toda a sua organização utilize dados e IA. É alimentada pelo DatabricksIQ e combina IA generativa com os benefícios de unificação de um lakehouse para entender a semântica exclusiva dos seus dados.
O Databricks Assistant está disponível nos Notebooks, no editor SQL e no editor de arquivos do Databricks como um assistente de IA sensível ao contexto para desenvolvedores.
Automação & orquestração
Databricks Os trabalhos orquestram o processamento de dados, o aprendizado de máquina e o pipeline analítico na Databricks Data Intelligence Platform. Delta Live Tables permitem que o senhor crie um pipeline ETL confiável e de fácil manutenção com sintaxe declarativa. A plataforma também oferece suporte a CI/CD e MLOps
Casos de uso de alto nível da plataforma de inteligência de dados no Google Cloud
Databricks LakeFlow Connect oferece conectores integrados para ingestão de aplicativos e bancos de dados corporativos. A ingestão resultante pipeline é governada por Unity Catalog e é alimentada por serverless compute e Delta Live Tables. O LakeFlow Connect utiliza leituras e gravações incrementais eficientes para tornar a ingestão de dados mais rápida, dimensionável e econômica, enquanto seus dados permanecem atualizados para consumo downstream.
Caso de uso: ETL em lotes
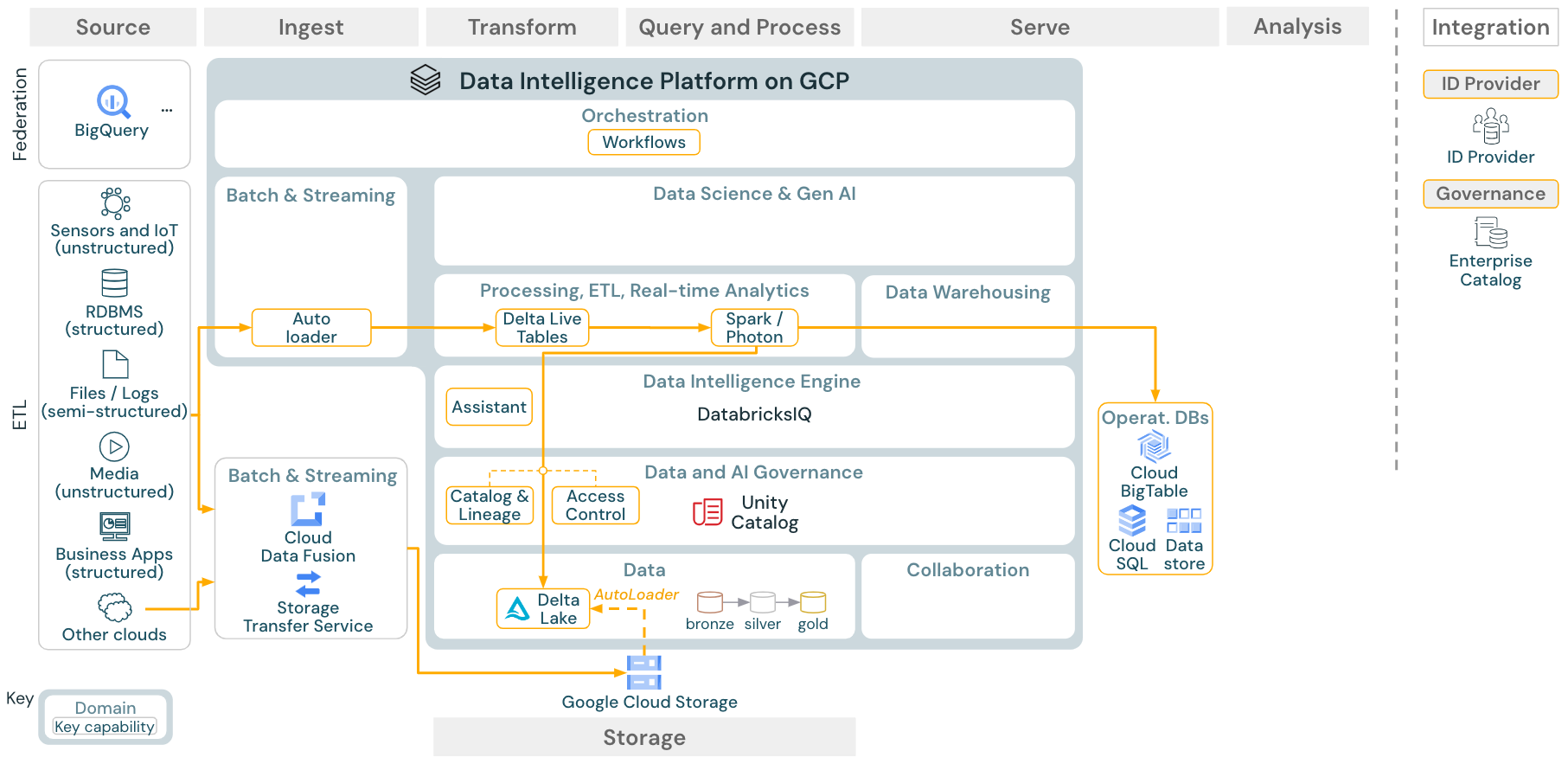
Download: arquitetura de referência de ETL em lotes para o Databricks on Google Cloud
As ferramentas de ingestão usam adaptadores específicos da fonte para ler os dados da fonte e, em seguida, armazená-los no armazenamento cloud, de onde o Auto Loader pode lê-los, ou chamar o Databricks diretamente (por exemplo, com ferramentas de ingestão de parceiros integradas ao Databricks lakehouse). Para carregar os dados, o Databricks ETL e o mecanismo de processamento - via DLT - executam as consultas. O fluxo de trabalho único ou multitarefa pode ser orquestrado por Databricks Jobs e governado por Unity Catalog (controle de acesso, auditoria, linhagem e assim por diante). Se os sistemas operacionais de baixa latência exigirem acesso a tabelas golden específicas, elas poderão ser exportadas para um banco de dados operacional, como um RDBMS ou key-value store no final do ETL pipeline.
Caso de uso: transmissão e captura de dados de alterações (CDC)
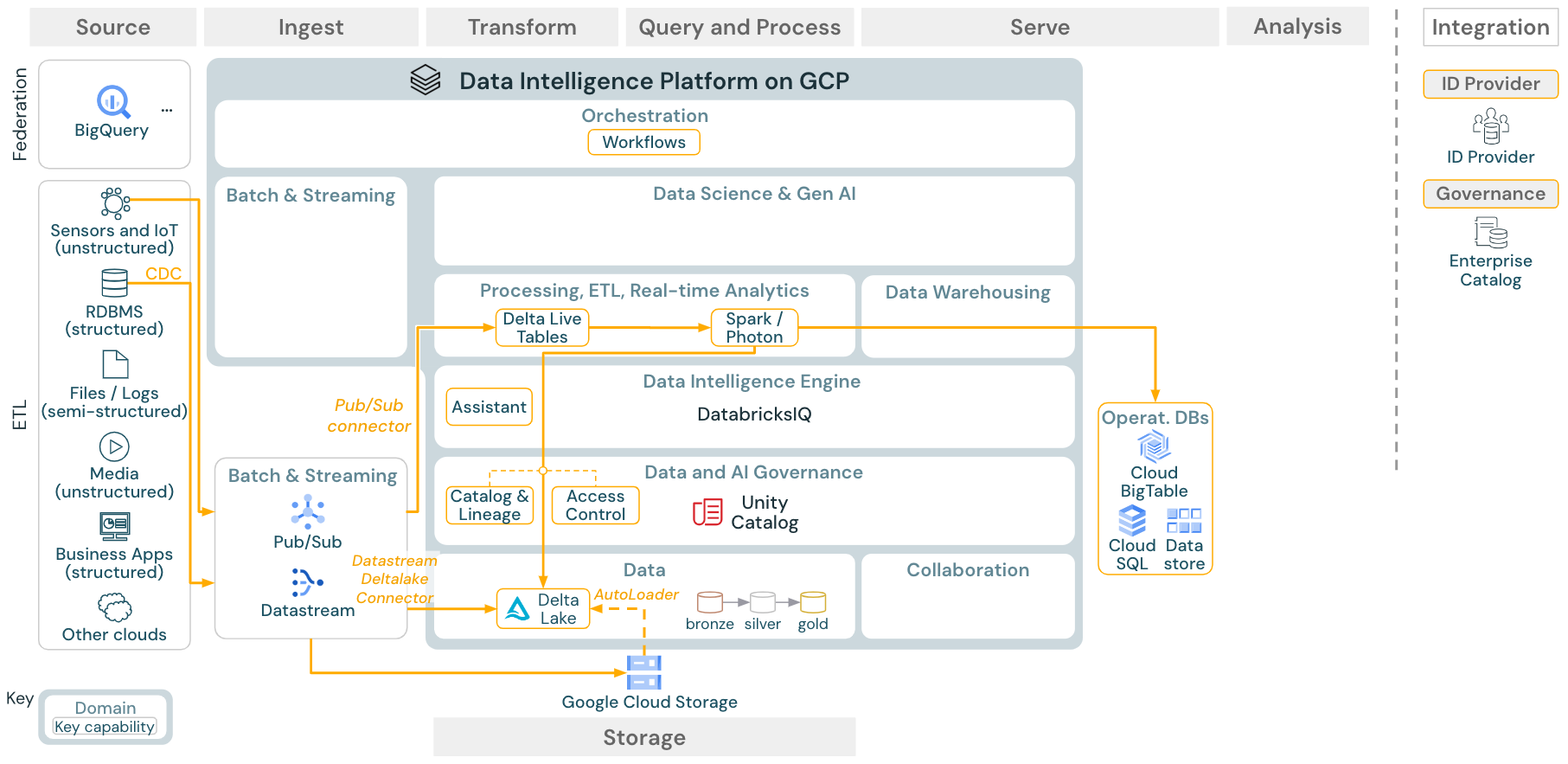
Download: arquitetura de streaming estruturado do Spark para Databricks on Google Cloud
O mecanismo ETL do Databricks utiliza a transmissão estructurada do Spark para ler a partir de filas de eventos, como o Apache Kafka ou o Pub/Sub. Os passos posteriores seguem a abordagem do caso de uso do Lote acima.
A CDC captura de dados de alterações normalmente utiliza uma fila de eventos para armazenar os eventos extraídos. A partir daí, o caso de uso segue o caso de uso de transmissão.
Se o CDC for feito em lote, onde os registros extraídos são armazenados primeiro no armazenamento em nuvem, o Databricks Autoloader poderá lê-los e o caso de uso seguirá o ETL em lote.
Caso de uso: aprendizado de máquina e IA
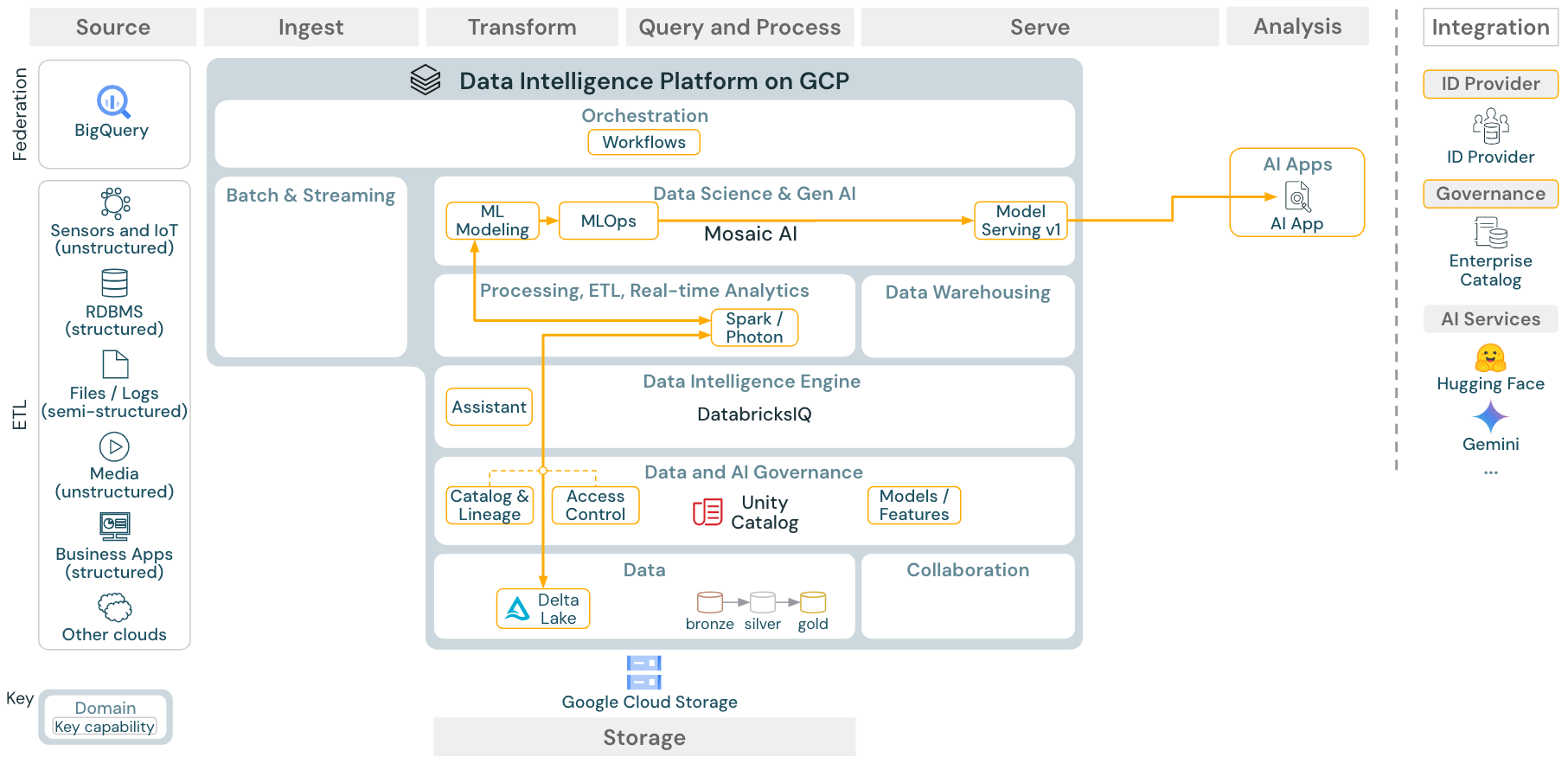
Download: Arquitetura de referência de aprendizado de máquina e IA para o Databricks on Google Cloud
Para o aprendizado de máquina, a Databricks Data Intelligence Platform oferece o Mosaic AI, que vem com biblioteca de aprendizagem profunda e de máquina de última geração. Ele oferece recursos como o Feature Store e o registro de modelos (ambos integrados ao Unity Catalog), recursos com pouco código com AutoML e integração do MLflow ao ciclo de vida da ciência de dados.
Toda a ciência de dados relacionada ao ativo (tabelas, recursos e modelos) é governada por Unity Catalog e data scientists pode usar Databricks Jobs para orquestrar seu trabalho.
Para implantar modelos de maneira escalável e de nível empresarial, use os recursos de MLOps para publicar os modelos no serviço de modelos.
Caso de uso: análise de BI e SQL
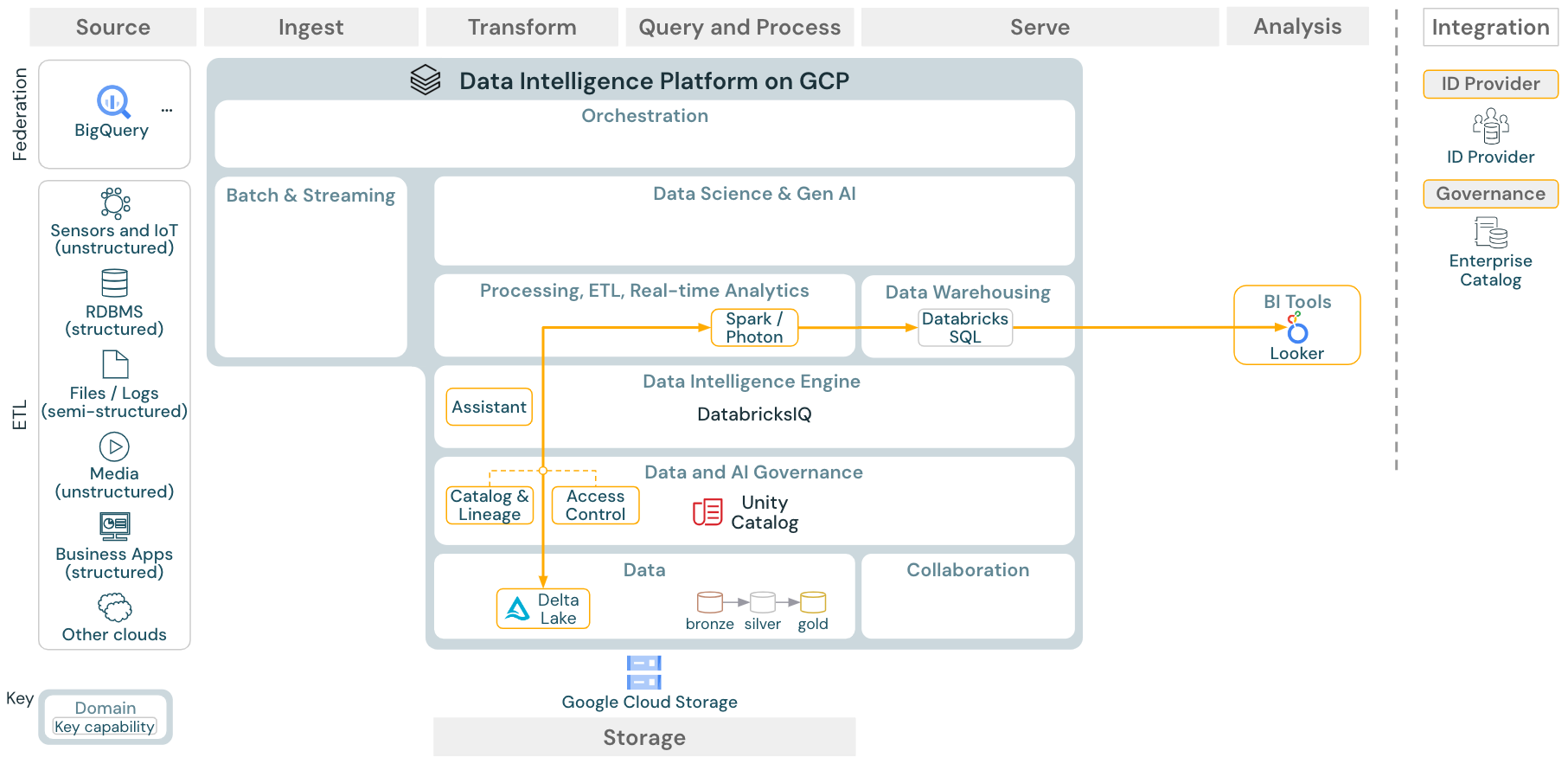
Download: Arquitetura de referência de análise de BI e SQL para Databricks on Google Cloud
Para casos de uso de BI, os analista de negócios podem usar o Databricks SQL ou ferramentas específicas de BI, como o Tableau ou o Looker. Em ambos os casos, o mecanismo é o Databricks SQL (serverless ou não) e o descobrimento de dados, a exploração e o controle de acesso são fornecidos pelo Unity Catalog.
Caso de uso: Federação da lakehouse
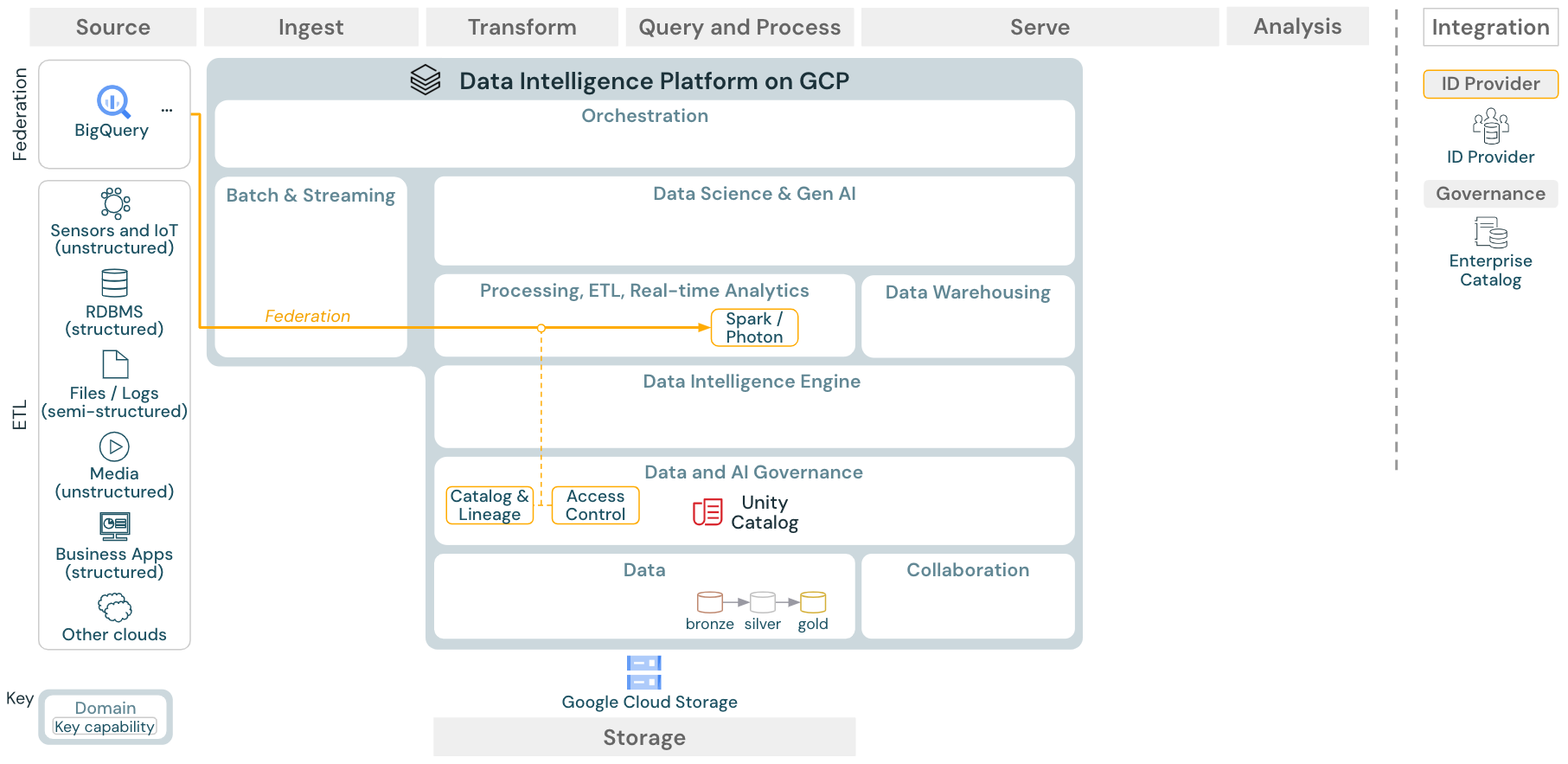
Download: Arquitetura de referência da federação da lakehouse para Databricks on Google Cloud
A federação da lakehouse possibilita que bancos de dados SQL externos (como MySQL ou Postgres) sejam integrados ao Databricks.
Todas as cargas de trabalho (IA, DWH e BI) podem se beneficiar disso sem a necessidade de ETL dos dados no armazenamento de objetos primeiro. O catálogo de fontes externas é associado no catálogo do Unity e o controle de acesso refinado pode ser aplicado ao acesso por meio da plataforma Databricks.
Caso de uso: compartilhamento de dados corporativos
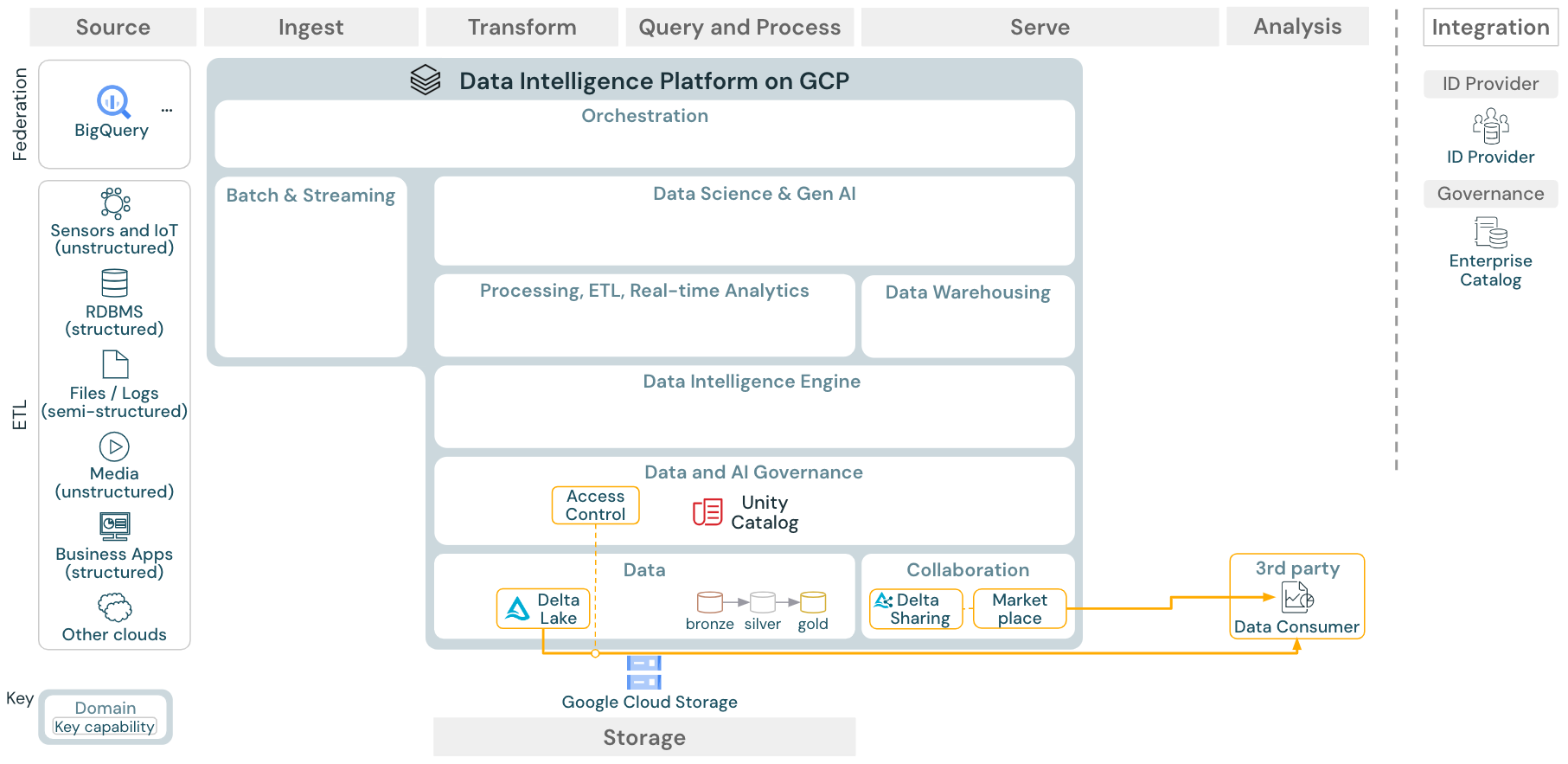
O compartilhamento de dados de nível empresarial é fornecido pela Delta Sharing. Proporciona acesso direto aos dados no armazenamento de objetos protegido pelo Unity Catalog, e o Databricks Marketplace é um fórum aberto para troca de produtos de dados.