Databricks Autologging
このページでは、さまざまな一般的な機械学習ライブラリからモデルをトレーニングするときに、モデル パラメーター、メトリクス、ファイル、およびリネージ情報を自動的にキャプチャする Databricks Autologgingをカスタマイズする方法について説明します。トレーニング セッションは、 MLflow 追跡の実行として記録されます。 モデルファイルも追跡されるため、 MLflow Model Registryに簡単にログに記録できます。
注
生成AI ワークロードのトレースログを有効にするために、 MLflow は OpenAI 自動ログをサポートしています。
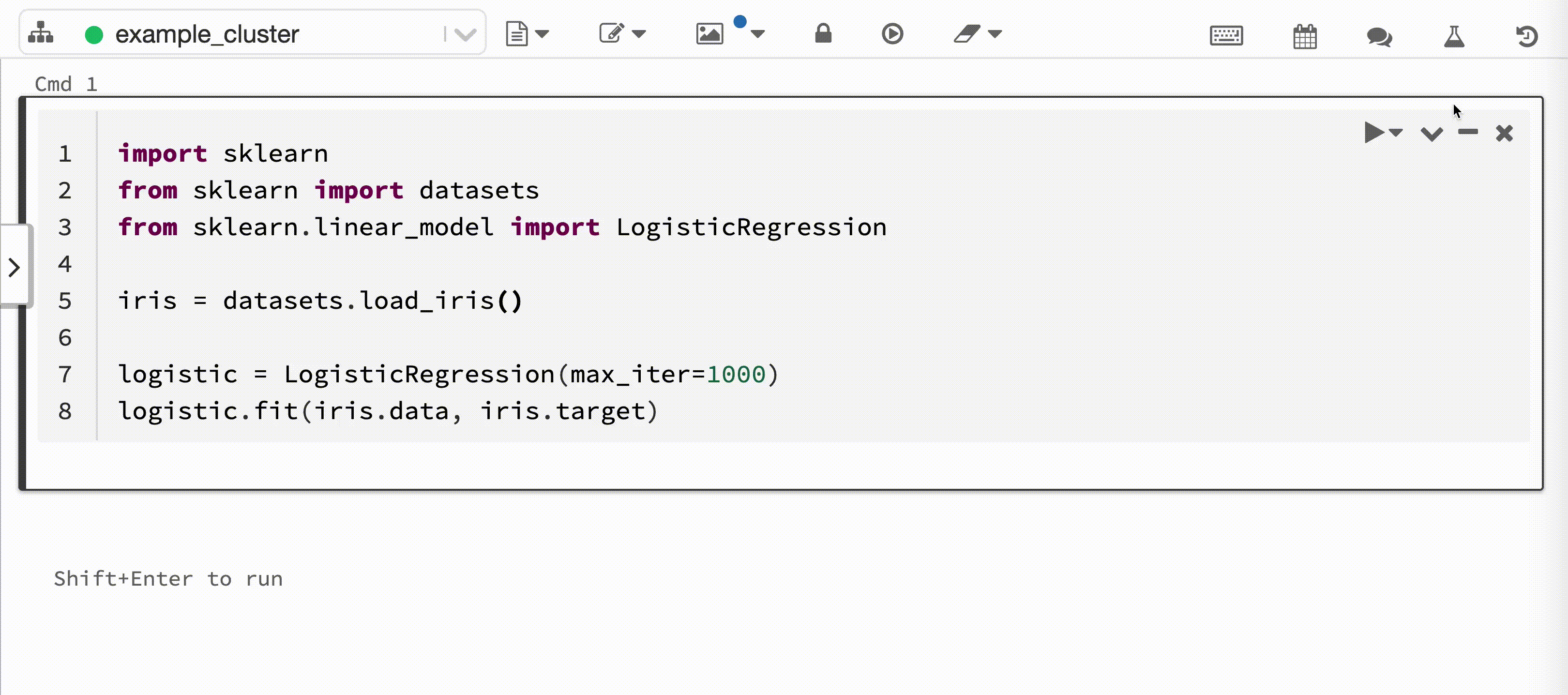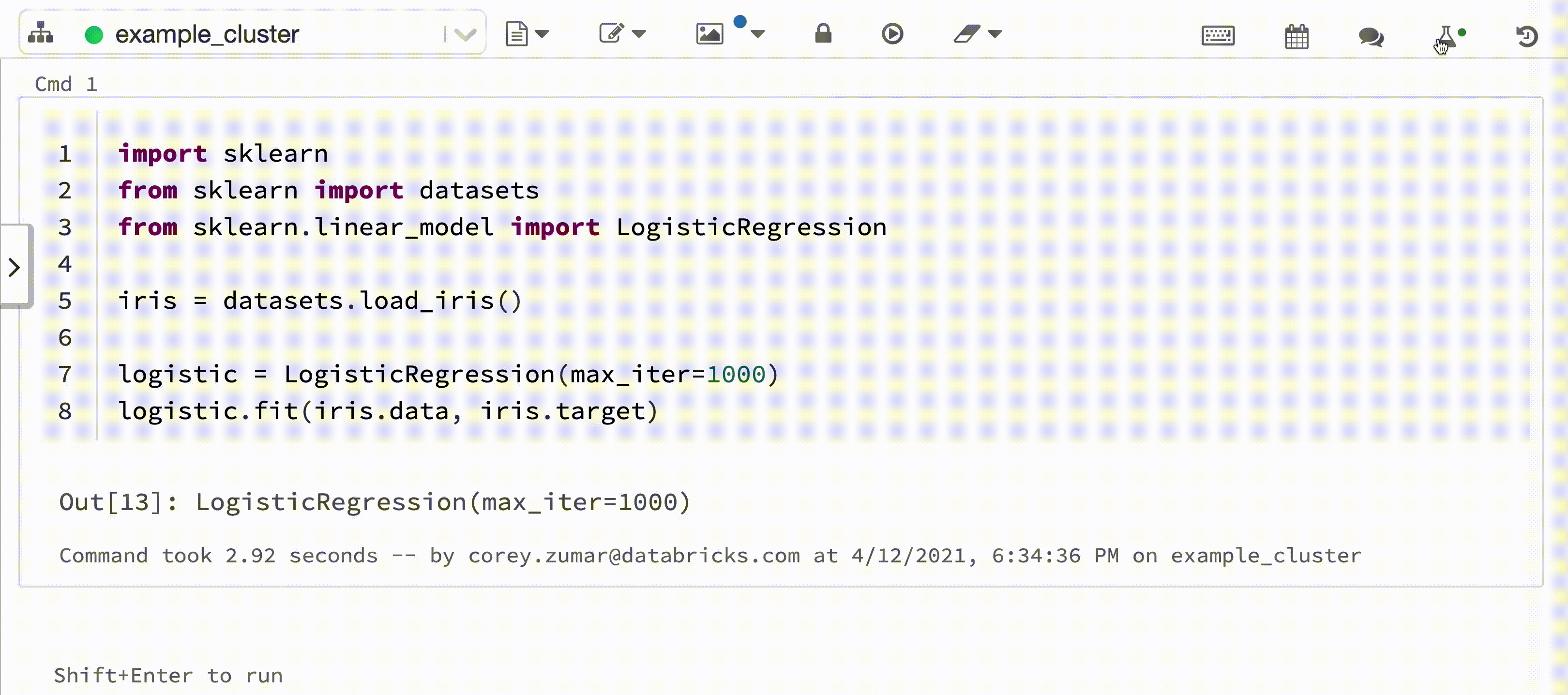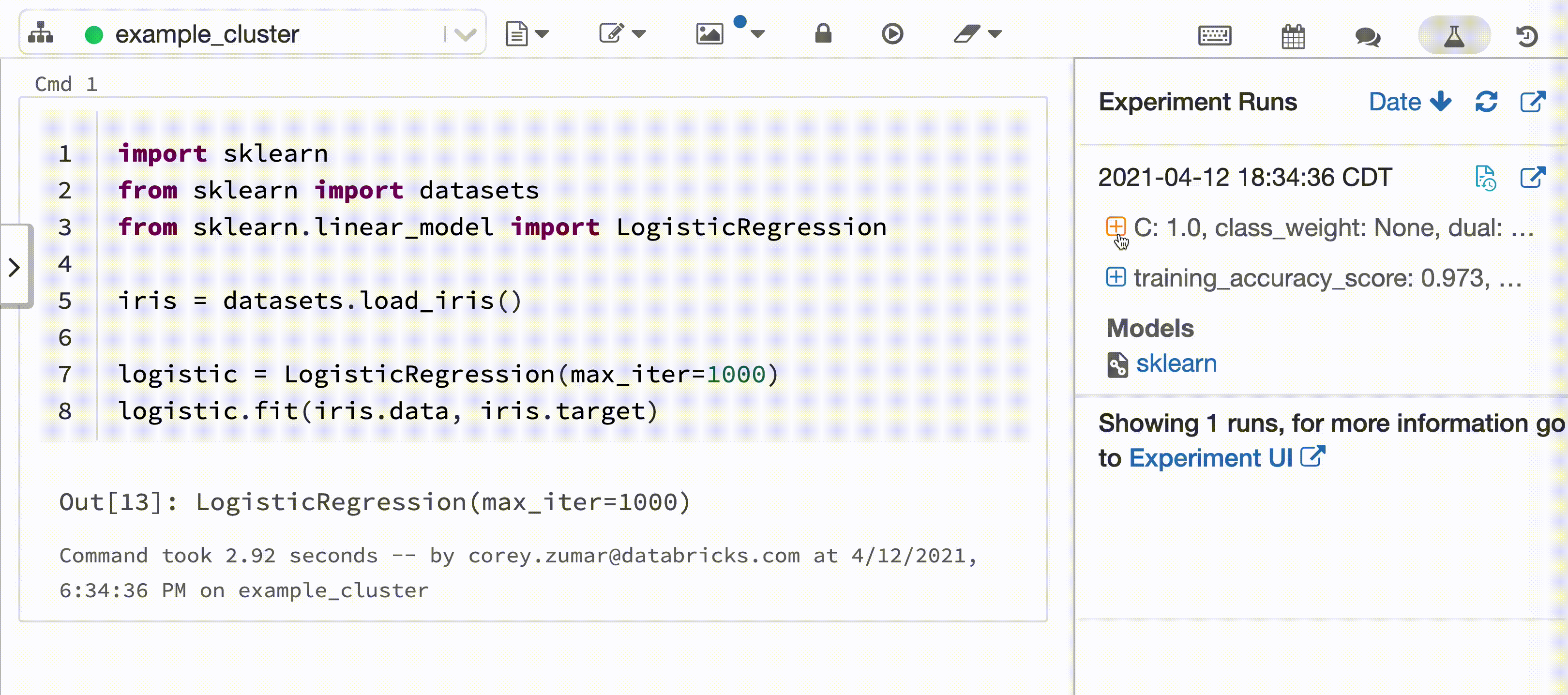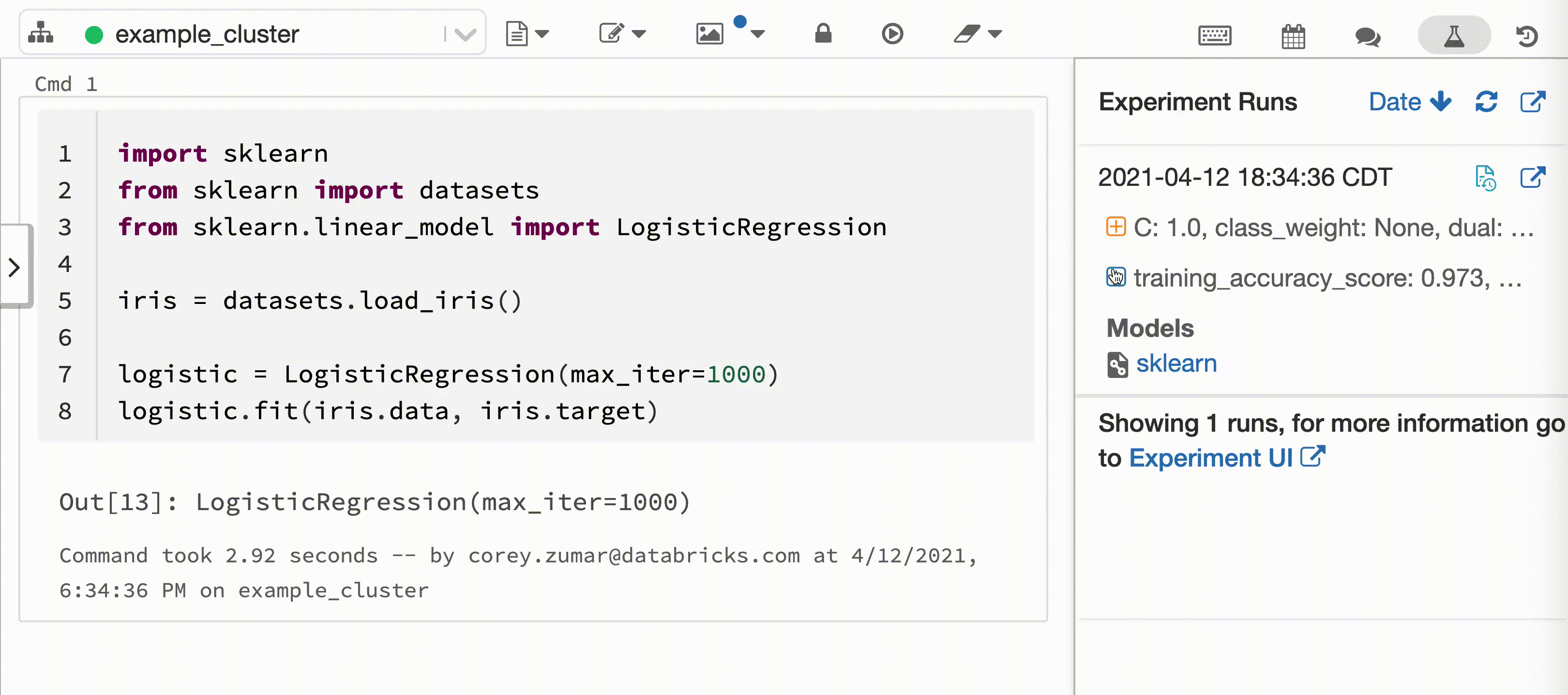
次のビデオは、対話型の Python ノートブックでの Scikit-Learn モデル トレーニング セッションを使用した Databricks Autologgingを示しています。 追跡情報は自動的にキャプチャされ、[エクスペリメントの実行] サイドバーと MLflow UI に表示されます。
要件
Databricks Autologging は、Databricks Runtime 10.4 LTS ML以降を使用するすべてのリージョンで一般公開されています。
Databricks Autologgingは、 Databricks Runtime 9.1 LTS ML以降の一部のプレビュー リージョンで使用できます。
仕組み
対話型の Python ノートブックを Databricks クラスターにアタッチすると、Databricks Autologgingによって mlflow.autolog() が呼び出され、モデル トレーニング セッションの追跡が設定されます。 ノートブックでモデルをトレーニングすると、モデルのトレーニング情報は MLflow 追跡を使用して自動的に追跡されます。 このモデルのトレーニング情報をセキュリティで保護および管理する方法については、「 セキュリティとデータマネジメント」を参照してください。
mlflow.autolog() のデフォルト設定 呼び出しは:
mlflow.autolog(
log_input_examples=False,
log_model_signatures=True,
log_models=True,
disable=False,
exclusive=False,
disable_for_unsupported_versions=True,
silent=False
)
自動ロギング構成をカスタマイズできます。
使い方
Databricks Autologgingを使用するには、対話型の Databricks Python ノートブックを使用して、 サポートされているフレームワーク で機械学習モデルをトレーニングします。 Databricks の自動ログ記録では、モデル系列の情報、パラメーター、およびメトリクスが MLflow 追跡に自動的に記録されます。 Databricks Autologgingの動作をカスタマイズすることもできます。
注
Databricks Autologgingは、 mlflow.start_run() で MLflow fluent API を使用して作成された実行には適用されません。 このような場合は、 mlflow.autolog() を呼び出して、自動ログ記録されたコンテンツを MLflow 実行に保存する必要があります。 追加コンテンツの追跡を参照してください。
ログ記録の動作をカスタマイズする
ロギングをカスタマイズするには、 mlflow.autolog() を使用します。 この関数は、モデルのログ記録 (log_models)、 log データセット (log_datasets)、 入力例の収集 (log_input_examples)、 記録済みモデル signatures (log_model_signatures)、警告の構成 (silent) などを有効にするための構成パラメーターを提供します。
追加コンテンツを追跡する
Databricks Autologgingによって作成された MLflow の実行を使用して追加のメトリクス、パラメーター、ファイル、メタデータを追跡するには、Databricks 対話型の Python ノートブックで次の手順に従います。
mlflow.autolog() を呼び出します。
exclusive=Falseで.mlflow.start_run() を使用して MLflow の実行を開始します。この呼び出しを
with mlflow.start_run()でラップできます。これを行うと、実行は完了後に自動的に終了します。MLflow 追跡メソッド(mlflow.log_param()) など) を使用して、トレーニング前のコンテンツを追跡します。
Databricks Autologgingでサポートされているフレームワーク内の 1 つ以上の機械学習モデルをトレーニングする。
MLflow 追跡メソッド(mlflow.log_metric()) など) を使用して、トレーニング後のコンテンツを追跡します。
ステップ 2 で
with mlflow.start_run()を使用しなかった場合は、 mlflow.end_run() を使用して MLflow の実行を終了します。
例:
import mlflow
mlflow.autolog(exclusive=False)
with mlflow.start_run():
mlflow.log_param("example_param", "example_value")
# <your model training code here>
mlflow.log_metric("example_metric", 5)
Databricks Autologgingを無効にする
Databricks 対話型の Python ノートブックで Databricks Autologgingを無効にするには、 mlflow.autolog() を呼び出します。 disable=True付き:
import mlflow
mlflow.autolog(disable=True)
管理者は 、管理設定ページ の[ 詳細設定 ] タブから、ワークスペース内のすべてのクラスターの Databricks Autologgingを無効にすることもできます。この変更を有効にするには、クラスターを再起動する必要があります。
サポートされている環境とフレームワーク
Databricks Autologgingは、対話型の Python ノートブックでサポートされており、次の機械学習フレームワークで使用できます。
Scikit-Learn
Apache Spark MLlib
TensorFlow
Keras
PyTorch Lightning
XGBoost
LightGBM
Gluon
Fast.AI
統計モデル
パドルパドル
サポートされている各フレームワークの詳細については、「自動ログMLflow」を参照してください。
MLflow トレースの有効化
MLflow トレースでは、それぞれのモデル フレームワーク統合内の autolog 機能を使用して、トレースをサポートする統合のトレース サポートの有効化または無効化を制御します。
たとえば、LlamaIndex モデルの使用時にトレースを有効にするには、mlflow.llama_index.autolog() を使用します log_traces=True付き:
import mlflow
mlflow.llama_index.autolog(log_traces=True)
自動ログ実装内でトレースが有効になっているサポート対象のインテグレーションは次のとおりです。
セキュリティとデータマネジメント
Databricks Autologgingで追跡されるすべてのモデル トレーニング情報は、 MLflow Tracking に保存され、 MLflow拡張機能のアクセス許可によって保護されます。 MLflow Tracking API または UI を使用して、モデル トレーニング情報を共有、変更、または削除できます。
管理
管理者は 、管理設定ページ の [詳細設定 ] タブで、ワークスペース全体のすべての対話型ノートブック セッションに対して Databricks 自動ログ記録を有効または無効にすることができます。変更はクラスターが再起動されるまで有効になりません。
制限
Databricks Autologgingは、 Databricks ジョブではサポートされていません。 ジョブから自動ロギングを使用するには、 明示的に mlflow.autolog() を呼び出します。
Databricks Autologgingは、Databricks クラスターのドライバー ノードでのみ有効になります。 ワーカーノードから自動ロギングを使用するには、 明示的に mlflow.autolog() を呼び出す必要があります。 各ワーカーで実行されているコード内から。
XGBoost Scikit-Learn 統合はサポートされていません。
Apache Spark MLlib、Hyperopt、および自動 MLflow トラッキング
Databricks Autologgingは、 Apache Spark MLlib および Hyperopt の既存の自動 MLflow 追跡統合の動作を変更しません。
注
Databricks Runtime 10.1 MLでは、Apache Spark MLlib CrossValidator および TrainValidationSplit モデルの自動機械学習フロー追跡統合を無効にすると、すべての Apache Spark MLlib モデルのDatabricks Autologging も無効になります。