serverless compute para Notebook
Prévia
Esse recurso está em Pré-lançamento público.
Este artigo explica como usar o site serverless compute para Notebook. Para obter informações sobre como usar serverless compute para Job, consulte executar seu Databricks Job com serverless compute para fluxo de trabalho.
Para obter informações sobre preços, consulte Databricks preços.
Requisitos
Seu site workspace deve estar habilitado para Unity Catalog.
Seu workspace deve estar em uma região compatível. Consulte Databricks clouds e regiões.
Seu account deve estar habilitado para serverless compute. Consulte Ativar serverless compute .
Anexe um Notebook a serverless compute
Se o seu workspace estiver habilitado para o serverless interativo compute, todos os usuários no workspace terão acesso ao serverless compute para Notebook. Não são necessárias permissões adicionais.
Para anexar ao site serverless compute, clique no menu suspenso Connect (Conectar ) no site Notebook e selecione serverless. Para o novo Notebook, o compute anexado é automaticamente padronizado para serverless na execução do código se nenhum outro recurso tiver sido selecionado.
view percepções de consulta
serverless compute para Notebook e Job usa percepções de consulta para avaliar o desempenho da execução do Spark. Depois de executar uma célula em um Notebook, o senhor pode view percepções relacionadas às consultas SQL e Python clicando no link See desempenho.
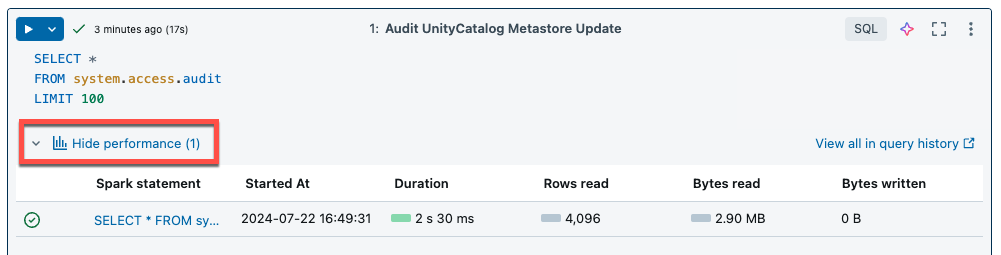
O senhor pode clicar em qualquer uma das declarações Spark para view as métricas de consulta. A partir daí, o senhor pode clicar em See query profile (Ver perfil da consulta) para ver uma visualização da execução da consulta. Para obter mais informações sobre perfis de consulta, consulte Perfil de consulta.
Observação
Para view percepções de desempenho para sua execução de trabalho, consulte visualizar percepções de consulta de execução de trabalho.
Histórico de consultas
Todas as consultas executadas no site serverless compute também serão registradas na página de histórico de consultas do site workspace. Para obter informações sobre a história da consulta, consulte História da consulta.
Limitações de entendimento da consulta
O perfil de consulta só fica disponível após o término da execução da consulta.
As métricas são atualizadas em tempo real, embora o perfil da consulta não seja mostrado durante a execução.
Somente os seguintes status de consulta são abordados: RUNNING, CANCELED, FAILED, FINISHED.
As consultas em execução não podem ser canceladas na página de histórico de consultas. Eles podem ser cancelados no Notebook ou no Job.
As métricas detalhadas não estão disponíveis.
O download do Query Profile não está disponível.
O acesso ao site Spark UI não está disponível.
O texto da declaração contém apenas a última linha que foi executada. No entanto, pode haver várias linhas anteriores a essa linha que foram executadas como parte da mesma declaração.
Quais regiões suportam a computação sem servidor?
serverless compute para Notebook e serverless compute para fluxo de trabalho são suportados nas seguintes regiões:
us-central1us-east1
Perguntas frequentes (FAQ)
Como as versões são implementadas?
serverless compute é um produto sem versão, o que significa que o Databricks atualiza automaticamente o tempo de execução do serverless compute para oferecer suporte a aprimoramentos e atualizações da plataforma. Todos os usuários recebem as mesmas atualizações, implementadas em um curto período de tempo.
Como posso determinar qual versão sem servidor estou executando?
as cargas de trabalho sem servidor sempre são executadas na versão mais recente do tempo de execução. Consulte as notas sobre a versão para obter a versão mais recente.
Como posso estimar os custos do serverless?
A Databricks recomenda a execução e o benchmarking de uma carga de trabalho representativa ou específica e, em seguida, a análise da tabela do sistema de faturamento. Consulte a referência da tabela do sistema de uso faturável.
Como faço para analisar o uso de DBU para uma carga de trabalho específica?
Para ver o custo de uma carga de trabalho específica, consulte a tabela do sistema system.billing.usage. Consulte Monitorar o custo de serverless computepara obter exemplos de consultas e para download nosso painel de observabilidade de custos.
A computação sem servidor oferece suporte a repositórios privados?
Os repositórios podem ser privados ou exigir autenticação. Por motivos de segurança, é necessário um URL pré-assinado ao acessar repositórios autenticados.
Como faço para instalar a biblioteca em minha tarefa Job?
Databricks recomenda o uso de ambientes para instalar e gerenciar biblioteca para seu trabalho. Consulte Configurar ambientes e dependências para tarefas que não sejam de notebooks.
Posso me conectar a uma fonte de dados personalizada?
Não, somente as fontes que usam lakehouse Federation são suportadas. Consulte Fonte de dados com suporte.
Como funciona a rede do plano de computação sem servidor?
serverless compute recurso execução no plano serverless compute , que é gerenciado por Databricks. Para obter mais detalhes sobre a rede e a arquitetura, consulte serverless compute plane networking.